Imagen to model Google do generowania obrazów wysokiej jakości, który na podstawie promptów tekstowych tworzy realistyczne obrazy o wysokiej jakości. Wszystkie wygenerowane obrazy zawierają znak wodny SynthID. Więcej informacji o dostępnych wariantach modelu Imagen znajdziesz w sekcji Wersje modelu.
Generowanie obrazów za pomocą modeli Imagen
Ten przykład pokazuje generowanie obrazów za pomocą modelu Imagen:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Konfiguracja Imagen
Obecnie Imagen obsługuje tylko prompty w języku angielskim i te parametry:
numberOfImages: liczba obrazów do wygenerowania, od 1 do 4 (włącznie). Wartość domyślna to 4.imageSize: rozmiar wygenerowanego obrazu. Ta funkcja jest obsługiwana tylko w przypadku modeli Standard i Ultra. Obsługiwane wartości to1Ki2K. Wartość domyślna to1K.aspectRatio: zmienia format wygenerowanego obrazu. Obsługiwane wartości to"1:1","3:4","4:3","9:16"i"16:9". Wartość domyślna to"1:1".personGeneration: zezwolenie modelowi na generowanie obrazów przedstawiających ludzi; Obsługiwane są te wartości:"dont_allow": blokowanie generowania obrazów przedstawiających ludzi."allow_adult": generować obrazy przedstawiające osoby dorosłe, ale nie dzieci. Jest to ustawienie domyślne."allow_all": generować obrazy przedstawiające dorosłych i dzieci;
Przewodnik po promptach Imagen
W tej sekcji przewodnika po Imagen dowiesz się, jak modyfikowanie promptu do zamiany tekstu na obraz może dać różne wyniki. Znajdziesz tu też przykłady obrazów, które możesz utworzyć.
Podstawowe informacje o pisaniu promptów
Dobry prompt jest opisowy i jasny, a także zawiera odpowiednie słowa kluczowe i modyfikatory. Zacznij od określenia tematu, kontekstu i stylu.

Temat: pierwszą rzeczą, o której należy pomyśleć w przypadku każdego prompta, jest temat, czyli obiekt, osoba, zwierzę lub sceneria, które mają być przedstawione na obrazie.
Kontekst i tło: równie ważne jest tło lub kontekst, w którym umieścisz obiekt. Spróbuj umieścić obiekt na różnych tłach. Na przykład studio z białym tłem, plener lub wnętrze.
Styl: na koniec dodaj styl obrazu, który chcesz uzyskać. Style może być ogólny (obraz, zdjęcie, szkic) lub bardzo szczegółowy (pastel, rysunek węglem, izometryczny obraz 3D). Możesz też łączyć style.
Po napisaniu pierwszej wersji prompta dopracuj go, dodając więcej szczegółów, aż uzyskasz obraz, który Cię zadowoli. Iteracja jest ważna. Zacznij od ustalenia głównego pomysłu, a następnie dopracowuj go i rozwijaj, aż wygenerowany obraz będzie zbliżony do Twojej wizji.

|

|

|
Modele Imagen mogą przekształcać Twoje pomysły w szczegółowe obrazy, niezależnie od tego, czy prompty są krótkie, czy długie i szczegółowe. Dopracuj swoją wizję, iteracyjnie dodając szczegóły do prompta, aż uzyskasz idealny rezultat.
|
Krótkie prompty umożliwiają szybkie wygenerowanie obrazu. 
|
Dłuższe prompty pozwalają dodawać szczegółowe informacje i budować obraz. 
|
Dodatkowe wskazówki dotyczące pisania promptów dla Imagen:
- Używaj opisowego języka: używaj szczegółowych przymiotników i przysłówków, aby stworzyć dla Imagen wyraźny obraz.
- Podaj kontekst: w razie potrzeby podaj dodatkowe informacje, które pomogą AI zrozumieć Twoje pytanie.
- Odwołuj się do konkretnych wykonawców lub stylów: jeśli masz na myśli konkretną estetykę, pomocne może być odwołanie się do konkretnych wykonawców lub ruchów artystycznych.
- Korzystaj z narzędzi do tworzenia promptów: rozważ użycie narzędzi lub materiałów do tworzenia promptów, które pomogą Ci udoskonalić prompty i uzyskać optymalne wyniki.
- Poprawianie szczegółów twarzy na zdjęciach osobistych i grupowych: określ szczegóły twarzy jako główny element zdjęcia (np. użyj w prompcie słowa „portret”).
Generowanie tekstu na obrazach
Modele Imagen mogą dodawać tekst do obrazów, co otwiera nowe możliwości kreatywnego generowania obrazów. Aby w pełni korzystać z tej funkcji, postępuj zgodnie z tymi wskazówkami:
- Iteracyjne generowanie obrazów: może być konieczne wielokrotne generowanie obrazów, aż uzyskasz pożądany efekt. Integracja tekstu w Imagen wciąż się rozwija, a czasami najlepsze wyniki uzyskuje się po kilku próbach.
- Krótko i zwięźle: aby uzyskać optymalne wyniki, ogranicz tekst do maksymalnie 25 znaków.
Kilka wyrażeń: eksperymentuj z 2–3 różnymi wyrażeniami, aby podać dodatkowe informacje. Aby uzyskać bardziej przejrzyste kompozycje, unikaj przekraczania 3 wyrażeń.

Prompt: Plakat z tekstem „Summerland” pogrubioną czcionką jako tytułem, pod którym znajduje się slogan „Summer never felt so good”. Umieszczanie tekstu: Imagen może próbować umieścić tekst zgodnie z instrukcjami, ale mogą wystąpić pewne odchylenia. Ta funkcja jest stale ulepszana.
Styl czcionki Inspire: określ ogólny styl czcionki, aby subtelnie wpłynąć na wybory Imagen. Nie polegaj na dokładnym odwzorowaniu czcionki, ale spodziewaj się kreatywnych interpretacji.
Rozmiar czcionki: określ rozmiar czcionki lub ogólny wskaźnik rozmiaru (np. mały, średni, duży), aby wpłynąć na generowanie rozmiaru czcionki.
Parametryzacja promptów
Aby lepiej kontrolować wyniki, możesz sparametryzować dane wejściowe Imagen. Załóżmy na przykład, że chcesz, aby klienci mogli generować logo dla swojej firmy, i chcesz mieć pewność, że logo są zawsze generowane na jednolitym tle. Chcesz też ograniczyć opcje, które klient może wybrać z menu.
W tym przykładzie możesz utworzyć prompt z parametrami podobny do tego:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.W niestandardowym interfejsie użytkownika klient może wprowadzać parametry za pomocą menu, a wybrana wartość wypełnia prompt, który otrzymuje Imagen.
Na przykład:
Prompt:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Prompt:
A modern logo for a software company on a solid color background. Include the text Silo.
Prompt:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Zaawansowane techniki pisania promptów
Skorzystaj z tych przykładów, aby tworzyć bardziej szczegółowe prompty na podstawie atrybutów, takich jak deskryptory fotografii, kształty i materiały, historyczne kierunki w sztuce i modyfikatory jakości obrazu.
Fotografia
- Prompt zawiera: „Zdjęcie…”
Aby użyć tego stylu, zacznij od słów kluczowych, które wyraźnie informują Imagen, że szukasz zdjęcia. Rozpocznij prompta od słów:„Zdjęcie”. . .". Na przykład:

|

|

|
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego za pomocą modelu Imagen 4.
Modyfikatory fotograficzne
W przykładach poniżej znajdziesz kilka modyfikatorów i parametrów związanych z fotografią. Możesz połączyć kilka modyfikatorów, aby uzyskać większą kontrolę.
Bliskość aparatu – zbliżenie zrobione z daleka

Prompt: Zdjęcie z bliska ziaren kawy 
Prompt: Oddalone zdjęcie małej torebki z
ziarnami kawy w nieuporządkowanej kuchniPozycja kamery – z lotu ptaka, od dołu

Prompt: zdjęcie lotnicze miasta z wieżowcami 
Prompt: Zdjęcie korony drzew w lesie z błękitnym niebem z perspektywy od dołu Oświetlenie – naturalne, efektowne, ciepłe, zimne

Prompt: studio photo of a modern arm chair, natural lighting 
Prompt: studio photo of a modern arm chair, dramatic lighting Ustawienia aparatu – rozmycie ruchu, miękka ostrość, bokeh, portret

Prompt: zdjęcie miasta z wieżowcami zrobione z wnętrza samochodu z rozmyciem w ruchu 
Prompt: nieostre zdjęcie mostu w mieście nocą Rodzaje obiektywów – 35 mm, 50 mm, rybie oko, szerokokątny, makro

Prompt: zdjęcie liścia, obiektyw makro 
Prompt: street photography, new york city, fisheye lens Rodzaje filmów – czarno-białe, polaroidowe

Prompt: zdjęcie polaroidowe psa w okularach przeciwsłonecznych 
Prompt: czarno-białe zdjęcie psa w okularach przeciwsłonecznych
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego za pomocą modelu Imagen 4.
Ilustracje i sztuka
- Prompt zawiera: „A painting of...”, „sketch z …”
Style artystyczne są różne – od monochromatycznych, takich jak szkice ołówkiem, po hiperrealistyczne cyfrowe dzieła sztuki. Na przykład te obrazy zostały wygenerowane na podstawie tego samego prompta, ale w różnych stylach:
„Zdjęcie [art style or creation technique] kanciastego, sportowego sedana elektrycznego z wieżowcami w tle”

|

|

|

|

|

|
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego w modelu Imagen 2.
Kształty i materiały
- Prompt zawiera: „...wykonane z...”, „…w kształcie…”
Jedną z zalet tej technologii jest możliwość tworzenia obrazów, które w inny sposób byłyby trudne lub niemożliwe do uzyskania. Możesz na przykład odtworzyć logo firmy z różnych materiałów i o różnych fakturach.

|

|

|
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego za pomocą modelu Imagen 4.
Odwołania do historycznych dzieł sztuki
- Prompt zawiera: „…w stylu…”
Niektóre style stały się kultowe na przestrzeni lat. Oto kilka pomysłów na style malarstwa historycznego lub style artystyczne, które możesz wypróbować.
„wygeneruj obraz w stylu [art period or movement] : farma wiatrowa”

|

|

|
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego za pomocą modelu Imagen 4.
Modyfikatory jakości obrazu
Niektóre słowa kluczowe mogą informować model, że szukasz zasobu wysokiej jakości. Przykłady modyfikatorów jakości:
- Modyfikatory ogólne – wysoka jakość, piękny, stylizowany
- Zdjęcia – 4K, HDR, zdjęcie studyjne
- Sztuka, ilustracja – profesjonalna, szczegółowa
Poniżej znajdziesz kilka przykładów promptów bez modyfikatorów jakości i tych samych promptów z modyfikatorami jakości.

|

kukurydzy zrobiony przez profesjonalnego fotografa |
Źródło obrazu: każdy obraz został wygenerowany przy użyciu odpowiedniego promptu tekstowego za pomocą modelu Imagen 4.
Formaty obrazu
Generowanie obrazów w Imagen umożliwia ustawienie 5 różnych formatów obrazu.
- Kwadrat (1:1, domyślny) – standardowe zdjęcie kwadratowe. Ten format jest często używany w postach w mediach społecznościowych.
Pełny ekran (4:3) – ten format jest często używany w mediach i filmach. Jest to też format większości starszych telewizorów (nie panoramicznych) i aparatów średnioformatowych. Obejmuje on większą część sceny w poziomie (w porównaniu z formatem 1:1), dlatego jest preferowanym współczynnikiem proporcji w fotografii.

Prompt: zbliżenie na palce muzyka grającego na pianinie, czarno-biały film, vintage (format obrazu 4:3) 
Prompt: Profesjonalne zdjęcie studyjne frytek dla ekskluzywnej restauracji w stylu magazynu kulinarnego (format obrazu 4:3) Pełny ekran w orientacji pionowej (3:4) – to pełnoekranowy format obrazu obrócony o 90 stopni. Dzięki temu możesz uchwycić więcej sceny w pionie niż w przypadku formatu 1:1.

Prompt: kobieta wędrująca po górach, zbliżenie na jej buty odbijające się w kałuży, w tle duże góry, w stylu reklamy, dramatyczne ujęcia (format obrazu 3:4) 
Prompt: ujęcie z lotu ptaka przedstawiające rzekę płynącą w górę mistycznej doliny (format obrazu 3:4) Panoramiczny (16:9) – ten format zastąpił format 4:3 i jest obecnie najpopularniejszym formatem obrazu w telewizorach, monitorach i ekranach telefonów komórkowych (w orientacji poziomej). Użyj tego formatu, jeśli chcesz uchwycić większą część tła (np. malownicze krajobrazy).

Prompt: mężczyzna ubrany na biało siedzi na plaży, zbliżenie, oświetlenie o złotej godzinie (format obrazu 16:9) Pionowy (9:16) – ten format jest panoramiczny, ale obrócony. Jest to stosunkowo nowy format obrazu, który zyskał popularność dzięki aplikacjom z krótkimi filmami (np. YouTube Shorts). Używaj tego trybu w przypadku wysokich obiektów o wyraźnej orientacji pionowej, takich jak budynki, drzewa, wodospady lub inne podobne obiekty.

Prompt: cyfrowa wizualizacja ogromnego, nowoczesnego, wspaniałego i epickiego drapacza chmur z pięknym zachodem słońca w tle (format obrazu 9:16)
Fotorealistyczne obrazy
Różne wersje modelu generowania obrazów mogą oferować połączenie wyjść artystycznych i fotorealistycznych. W promptach używaj poniższych sformułowań, aby generować bardziej fotorealistyczne wyniki na podstawie tematu, który chcesz wygenerować.
| Przypadek użycia | Rodzaj obiektywu | Ogniskowe | Informacje dodatkowe |
|---|---|---|---|
| Osoby (portrety) | Obiektyw stałoogniskowy, zoom | 24-35mm | film czarno-biały, film noir, głębia ostrości, duotone (wymień 2 kolory) |
| Jedzenie, owady, rośliny (obiekty, martwa natura) | Makro | 60-105mm | Wysoka szczegółowość, precyzyjne ustawianie ostrości, kontrolowane oświetlenie |
| Sport, dzika przyroda (ruch) | Powiększenie teleobiektywu | 100-400mm | Krótki czas otwarcia migawki, śledzenie akcji lub ruchu |
| Astronomiczne, krajobrazowe (szerokokątne) | Szerokokątny | 10-24mm | Długie czasy naświetlania, ostra ostrość, długi czas naświetlania, gładka woda lub chmury |
Portrety
| Przypadek użycia | Rodzaj obiektywu | Ogniskowe | Informacje dodatkowe |
|---|---|---|---|
| Osoby (portrety) | Obiektyw stałoogniskowy, zoom | 24-35mm | film czarno-biały, film noir, głębia ostrości, duotone (wymień 2 kolory) |
Korzystając z kilku słów kluczowych z tabeli, Imagen może wygenerować te portrety:

|

|

|

|
Prompt: Kobieta, portret 35 mm, duotony w odcieniach niebieskiego i szarego
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: Kobieta, portret 35 mm, film noir
Model: imagen-4.0-generate-001
Obiekty
| Przypadek użycia | Rodzaj obiektywu | Ogniskowe | Informacje dodatkowe |
|---|---|---|---|
| Jedzenie, owady, rośliny (obiekty, martwa natura) | Makro | 60-105mm | Wysoka szczegółowość, precyzyjne ustawianie ostrości, kontrolowane oświetlenie |
Korzystając z kilku słów kluczowych z tabeli, Imagen może wygenerować te obrazy obiektów:

|

|

|

|
Prompt: liść maranty, obiektyw makro, 60 mm
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: a plate of pasta, 100mm Macro lens
Model: imagen-4.0-generate-001
Ruch
| Przypadek użycia | Rodzaj obiektywu | Ogniskowe | Informacje dodatkowe |
|---|---|---|---|
| Sport, dzika przyroda (ruch) | Powiększenie teleobiektywu | 100-400mm | Krótki czas otwarcia migawki, śledzenie akcji lub ruchu |
Korzystając z kilku słów kluczowych z tabeli, Imagen może wygenerować te obrazy w ruchu:

|

|
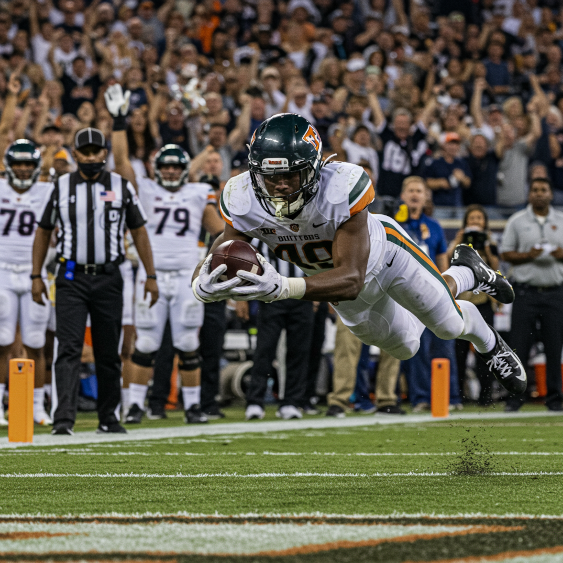
|

|
Prompt: zwycięskie przyłożenie, krótki czas otwarcia migawki, śledzenie ruchu
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: Jeleń biegnący po lesie, szybka migawka, śledzenie ruchu
Model: imagen-4.0-generate-001
Szerokokątny
| Przypadek użycia | Rodzaj obiektywu | Ogniskowe | Informacje dodatkowe |
|---|---|---|---|
| Astronomiczne, krajobrazowe (szerokokątne) | Szerokokątny | 10-24mm | Długie czasy naświetlania, ostra ostrość, długi czas naświetlania, gładka woda lub chmury |
Korzystając z kilku słów kluczowych z tabeli, Imagen może wygenerować te zdjęcia szerokokątne:

|

|

|

|
Prompt: rozległe pasmo górskie, krajobraz, szeroki kąt 10 mm
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: zdjęcie księżyca, astrofotografia, szeroki kąt 10 mm
Model: imagen-4.0-generate-001
Wersje modelu
Imagen 4
| Właściwość | Opis |
|---|---|
| Kod modelu |
Gemini API
|
| Obsługiwane typy danych |
Wejście Tekst Dane wyjściowe Obrazy |
| Limity tokenów[*] |
Limit tokenów wejściowych 480 tokenów (tekst) Obrazy wyjściowe 1–4 (Ultra/Standard/Fast) |
| Ostatnia aktualizacja | Czerwiec 2025 r. |
Imagen 3
Model Imagen 3 został wyłączony.