
Jeder verantwortungsbewusste Ansatz bei der Anwendung von künstlicher Intelligenz (KI) sollte Sicherheitsrichtlinien, Transparenzelemente und Sicherheitsmaßnahmen umfassen. Der verantwortungsvolle Umgang mit KI bedeutet jedoch mehr als das Abhaken von Checklisten.
Produkte für generative KI sind relativ neu und das Verhalten einer Anwendung kann variieren als frühere Formen von Software. Aus diesem Grund sollten Sie die verwendeten Modelle testen, um Beispiele für das Verhalten des Modells zu untersuchen und unerwartete Ergebnisse zu untersuchen.
Prompting ist die allgegenwärtige Schnittstelle für die Interaktion mit generativer KI. Das Erstellen dieser Aufgaben ist so viel Kunst wie Wissenschaft. Es gibt jedoch Tools, mit denen Sie Aufgaben für LLMs empirisch verbessern können, z. B. Learning Interpretability Tool (LIT): LIT ist ein Open-Source-Tool zum visuellen Verständnis und zur Fehlerbehebung von KI-Modellen, das als Debugger für schnelle Entwicklungsarbeit verwendet werden kann. Folgen Sie der angegebenen Anleitung mit Colab oder Codelab.
Gemma-Modelle mit LIT analysieren
|
|
|
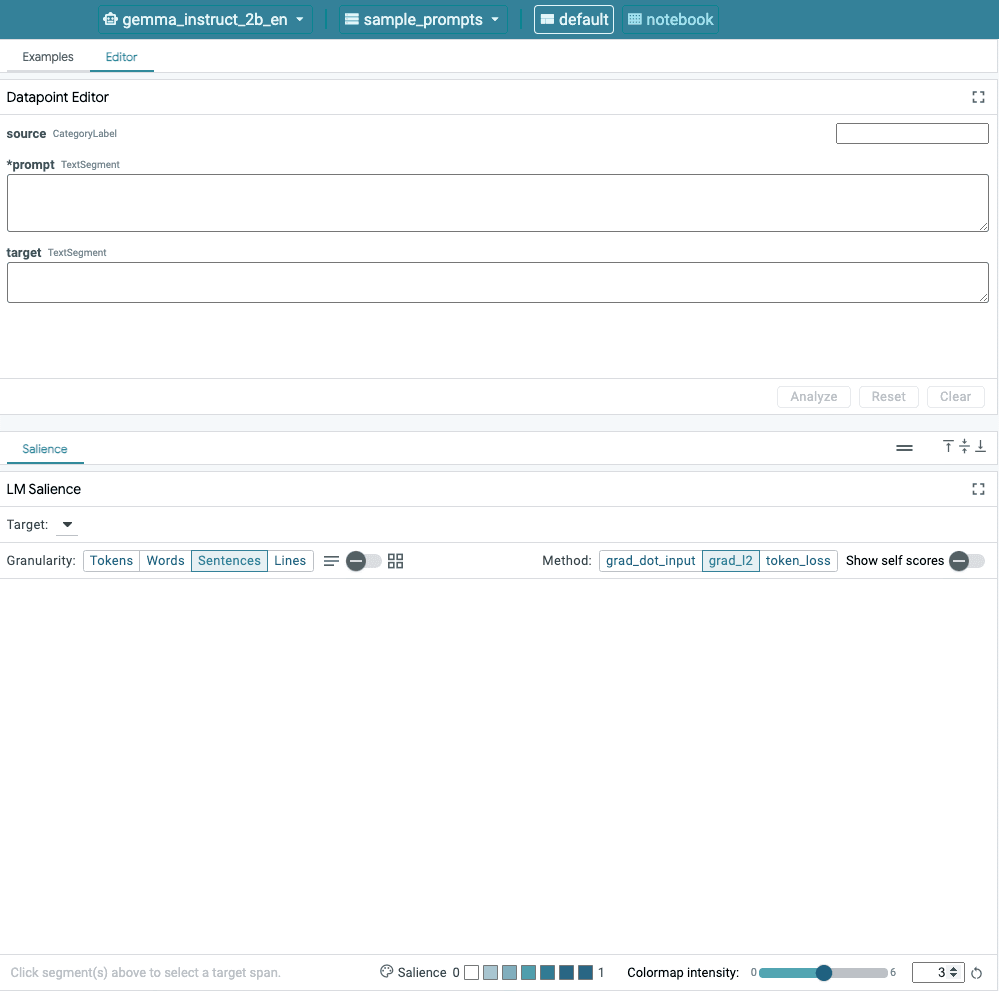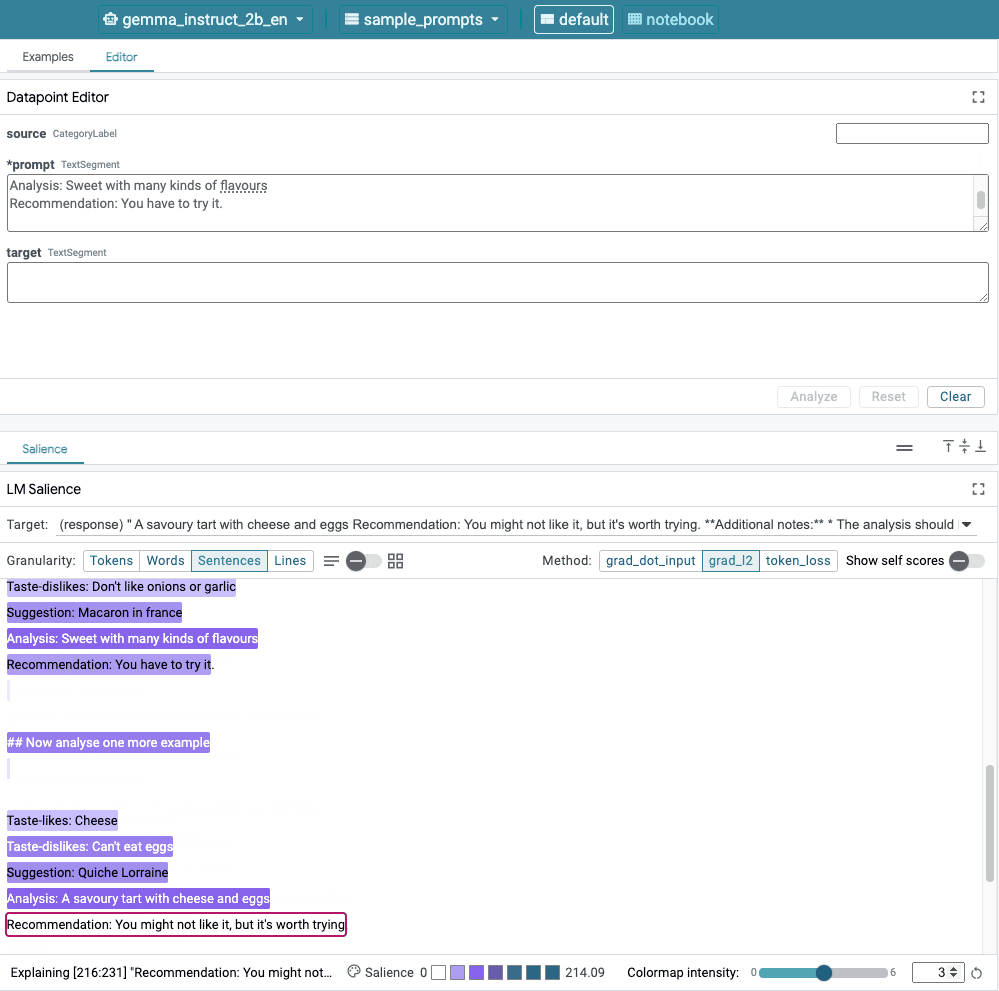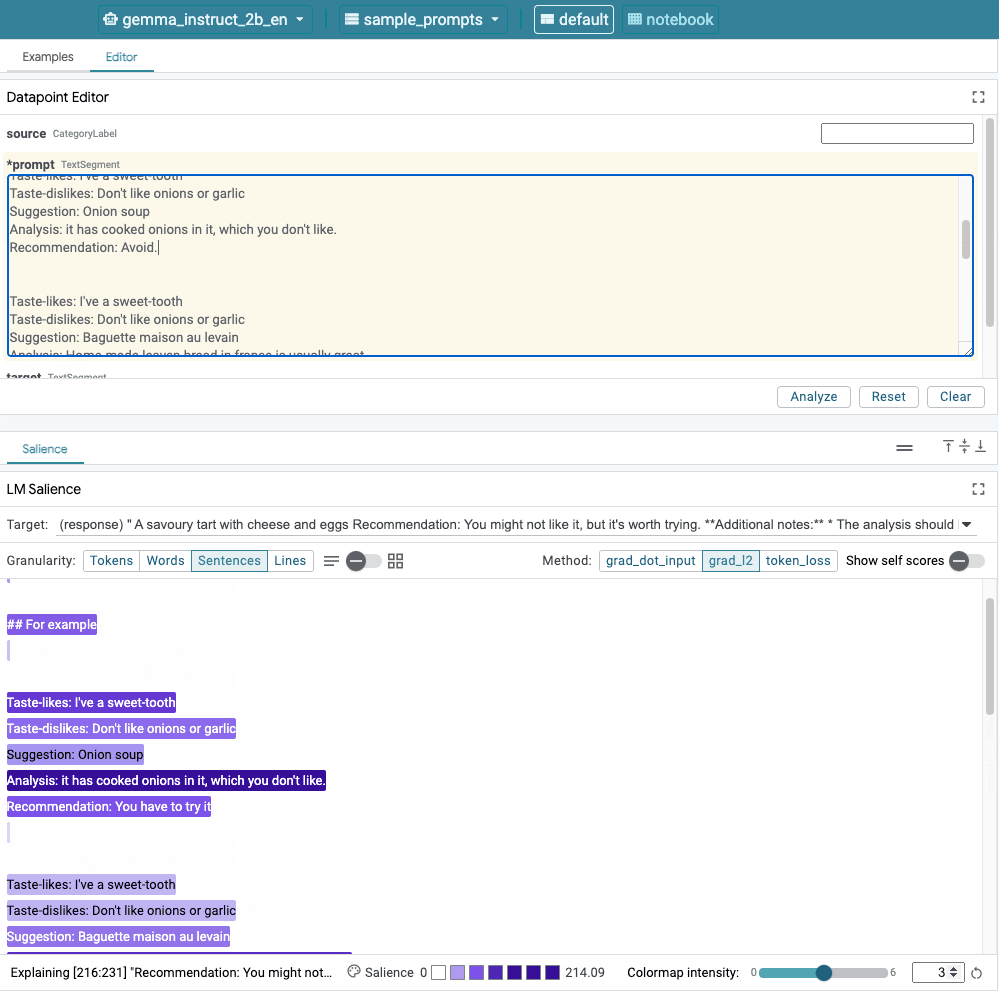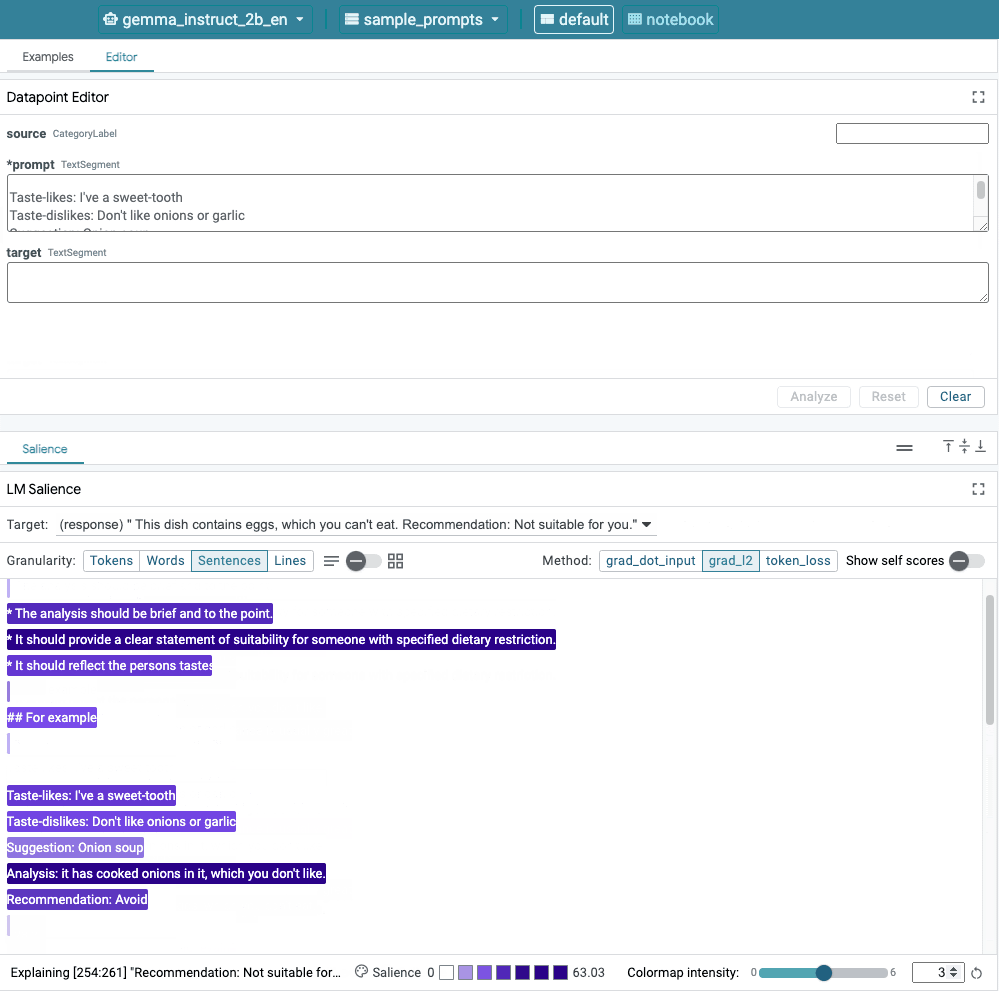
Abbildung 1. Die Benutzeroberfläche von LIT: Der Datapoint Editor oben die Nutzer ihre Aufforderungen bearbeiten können. Unten können sie mit dem LM Salience-Modul um die Auffälligkeitsergebnisse zu überprüfen.
Sie können LIT auf Ihrem lokalen Computer, in Colab oder in Google Cloud verwenden.
Nicht technische Teams in die Modellerprobung und explorative Datenanalyse einbeziehen
Interpretierbarkeit ist auf Teamarbeit ausgelegt, die Fachwissen über Richtlinien, Rechtliches und mehr. Das visuelle Medium und die interaktive Fähigkeit von LIT, Auffälligkeit und Beispiele untersuchen, können verschiedenen Stakeholdern helfen, und kommunizieren Ergebnisse. Dieser Ansatz kann für mehr Vielfalt in der Perspektive Erkunden, Testen und Debuggen von Modellen. Ihre Teamkollegen mit diesen technischen Methoden ihr Verständnis der Funktionsweise von Modellen erweitern. Darüber hinaus kann eine größere Vielfalt an Fachwissen in frühen Modelltests dazu beitragen, unerwünschte Ergebnisse zu erkennen, die verbessert werden können.