
Qualsiasi approccio responsabile all'applicazione dell'intelligenza artificiale (IA) deve includere norme di sicurezza, elementi di trasparenza e garanzie, ma essere responsabili con l'IA significa molto più che seguire le liste di controllo.
I prodotti di IA generativa sono relativamente nuovi e il comportamento di un'applicazione può variare più rispetto alle forme precedenti di software. Per questo motivo, devi analizzare i modelli in uso per esaminare esempi del comportamento del modello e verificare le sorprese.
La richiesta è l'interfaccia onnipresente per interagire con l'IA generativa. progettare questi prompt è tanto arte che scienza. Tuttavia, esistono strumenti che possono aiutarti a migliorare empiricamente i prompt per gli LLM, come lo strumento di interpretabilità dell'apprendimento (LIT). LIT è uno strumento open source per comprendere visivamente e eseguire il debug dei modelli di IA, che può essere utilizzato come debugger per il lavoro di progettazione dei prompt. Segui il tutorial fornito utilizzando Colab o Codelab.
Analisi dei modelli Gemma con LIT
|
|
|
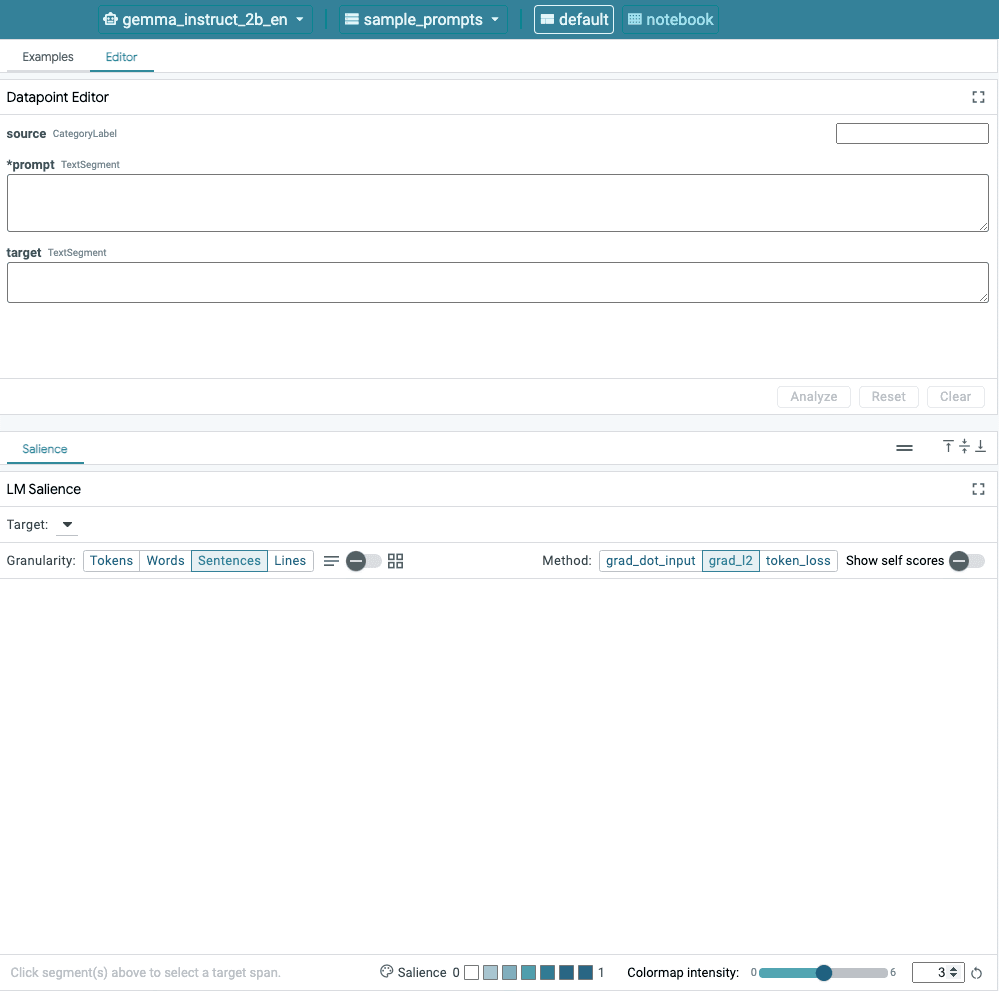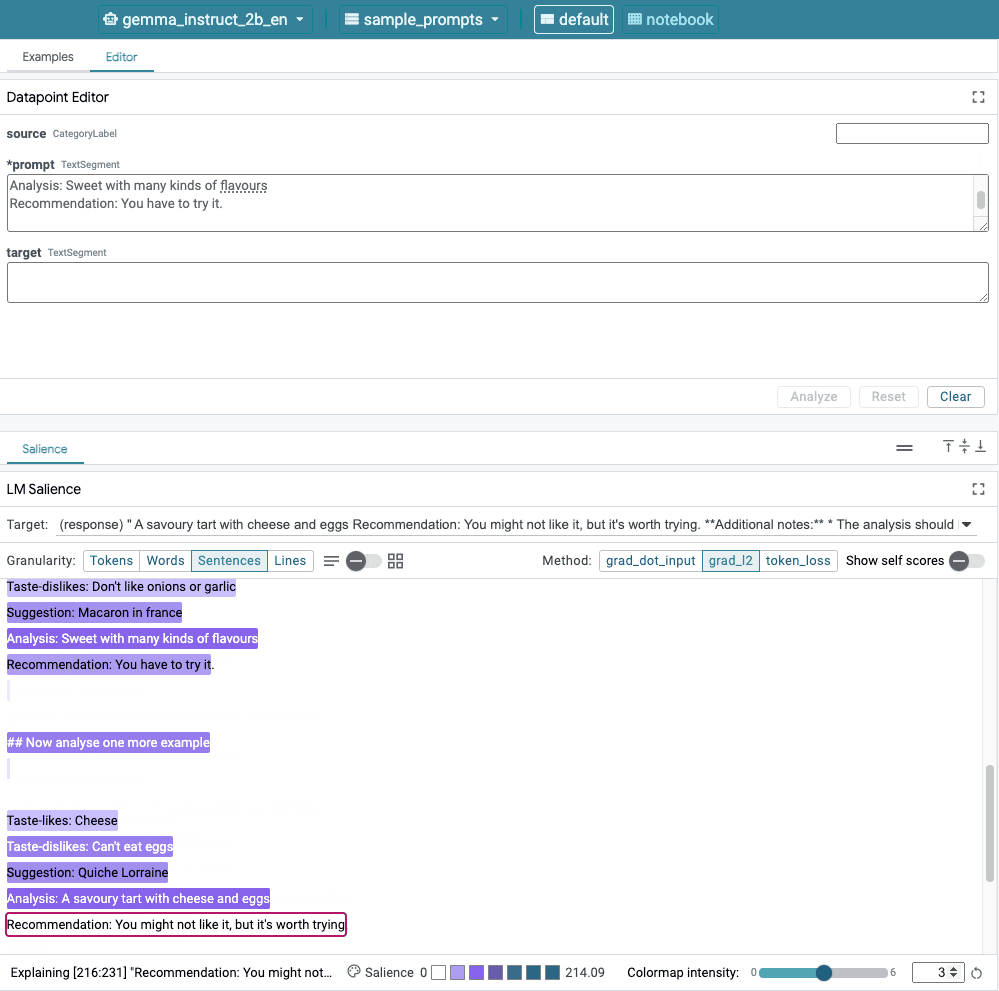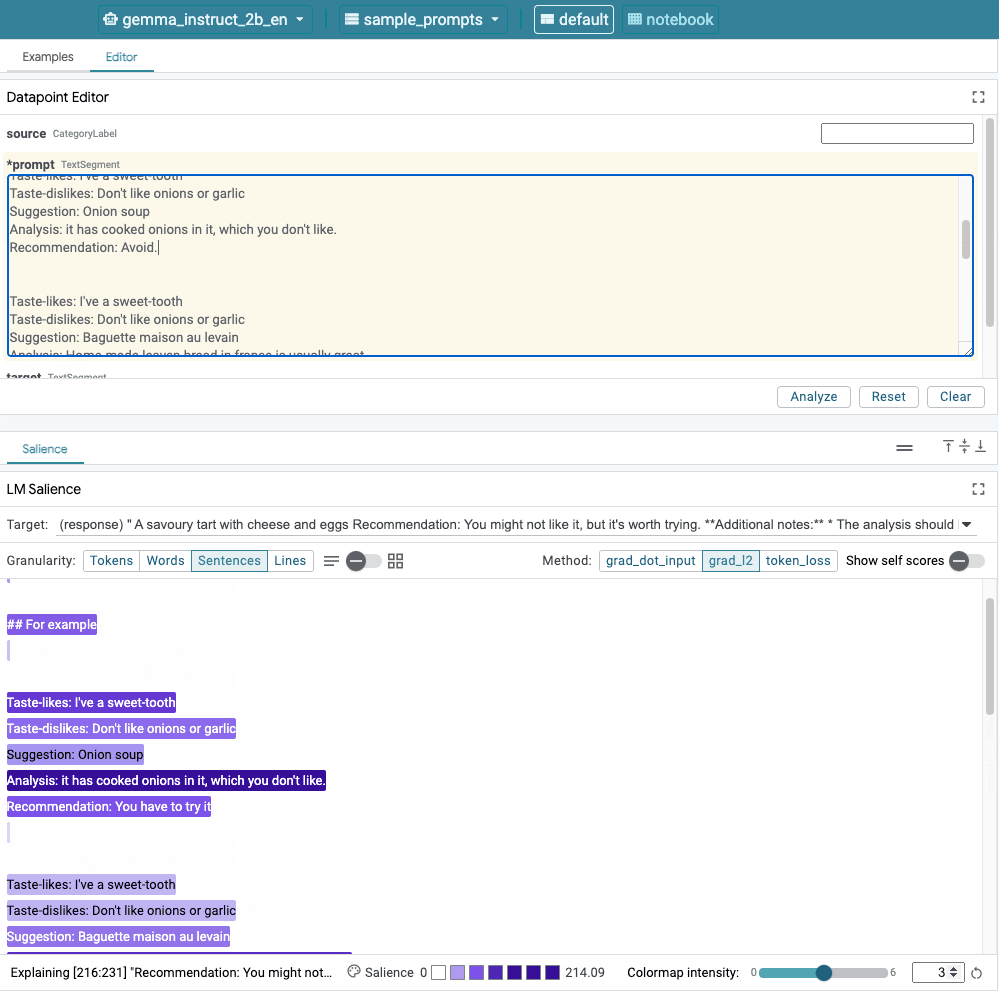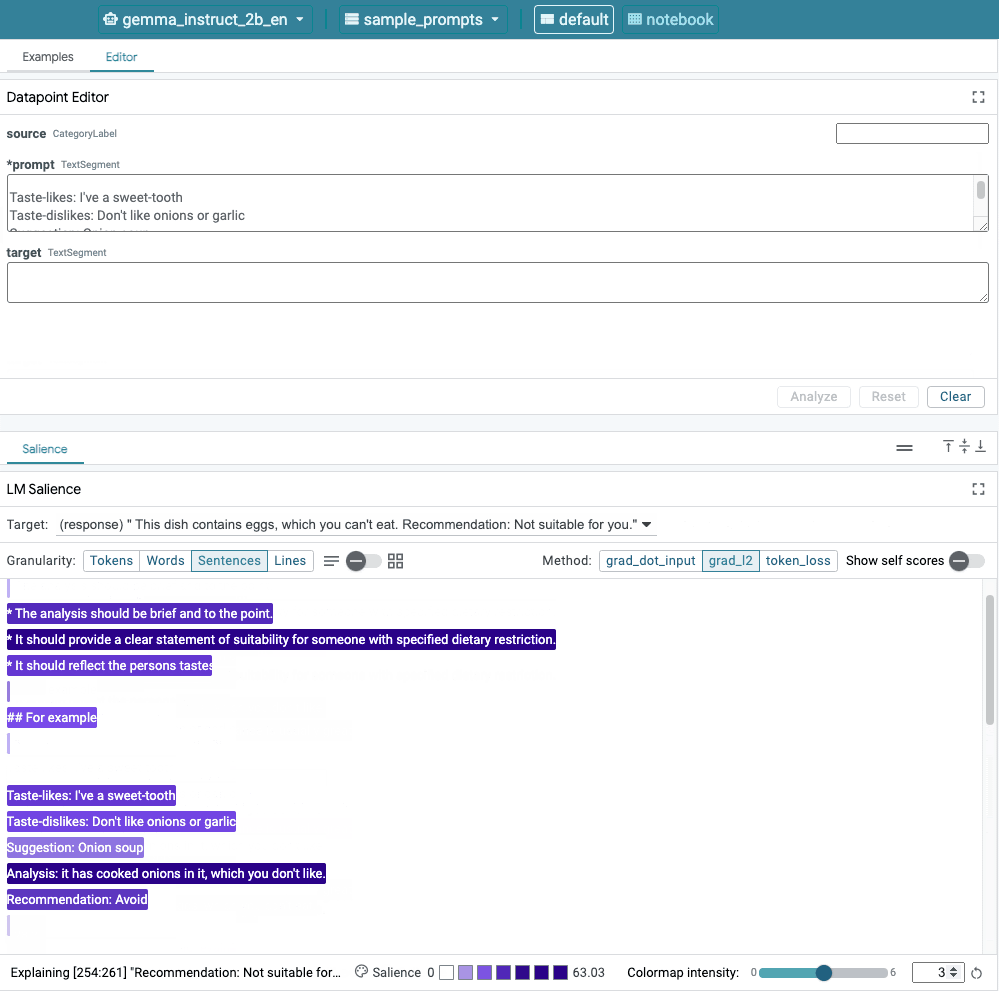
Figura 1. Interfaccia utente di LIT: l'editor dei punti dati in alto consente agli utenti di modificare i prompt. Nella parte inferiore, il modulo LM Salience consente loro per controllare i risultati della rilevanza.
Puoi utilizzare LIT sulla tua macchina locale, in Colab o su Google Cloud.
Includi team non tecnici nel probe e nell'esplorazione del modello
L'interpretabilità è pensata come un lavoro di squadra, che richiede competenze in materia di norme, diritto e altro ancora. Mezzo visivo delle LIT e capacità interattiva di esaminare la rilevanza e l'esplorazione degli esempi possono aiutare i vari stakeholder a condividere comunicare i risultati. Questo approccio consente una maggiore diversità di prospettive esplorazione, probe e debug del modello. Mettere i tuoi colleghi in contatto con questi metodi tecnici può aiutarli a comprendere meglio il funzionamento dei modelli. Nella Inoltre, una serie più diversificata di competenze nei test iniziali del modello può aiutare e scoprire risultati indesiderati che possono essere migliorati.