
Toute approche responsable de l'application de l'intelligence artificielle (IA) doit inclure des règles de sécurité, des artefacts de transparence et des garanties, mais être responsable avec l'IA signifie bien plus que suivre des checklists.
Les produits d'IA générative sont relativement nouveaux, et les comportements d'une application peuvent varier davantage que les formes antérieures de logiciels. Pour cette raison, vous devez interroger les modèles utilisés pour examiner des exemples du comportement du modèle et examiner les surprises.
Les requêtes sont l'interface incontournable d'interaction avec l'IA générative. l'ingénierie de ces requêtes est autant de l'art que de la science. Toutefois, il existe des outils qui peuvent vous aider à améliorer empiriquement les requêtes pour les LLM, comme Learning Interpretability Tool (LIT). LIT est une plate-forme Open Source un outil de compréhension visuelle et de débogage des modèles d'IA, qui peut être utilisé un débogueur pour les tâches d'ingénierie des requêtes. Suivez le tutoriel fourni à l'aide de Colab ou d'un atelier de programmation.
Analyser des modèles Gemma avec LIT
|
|
|
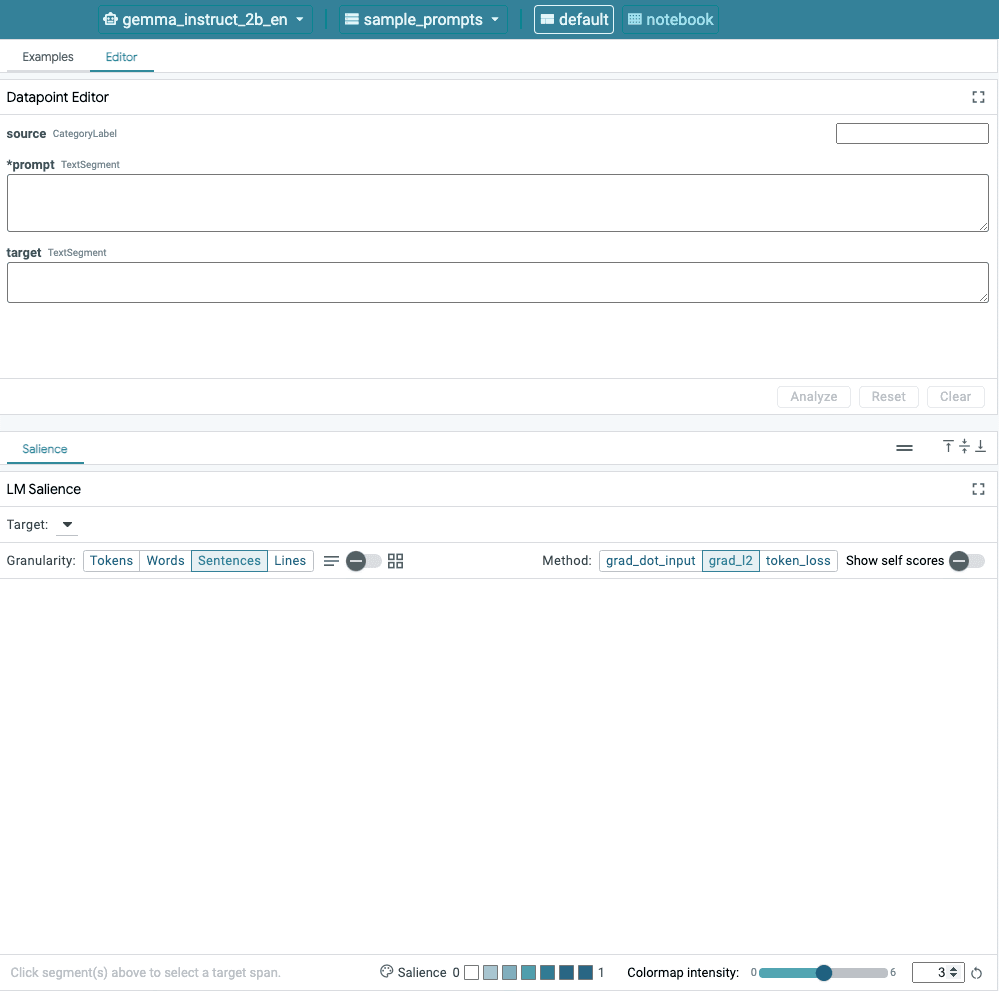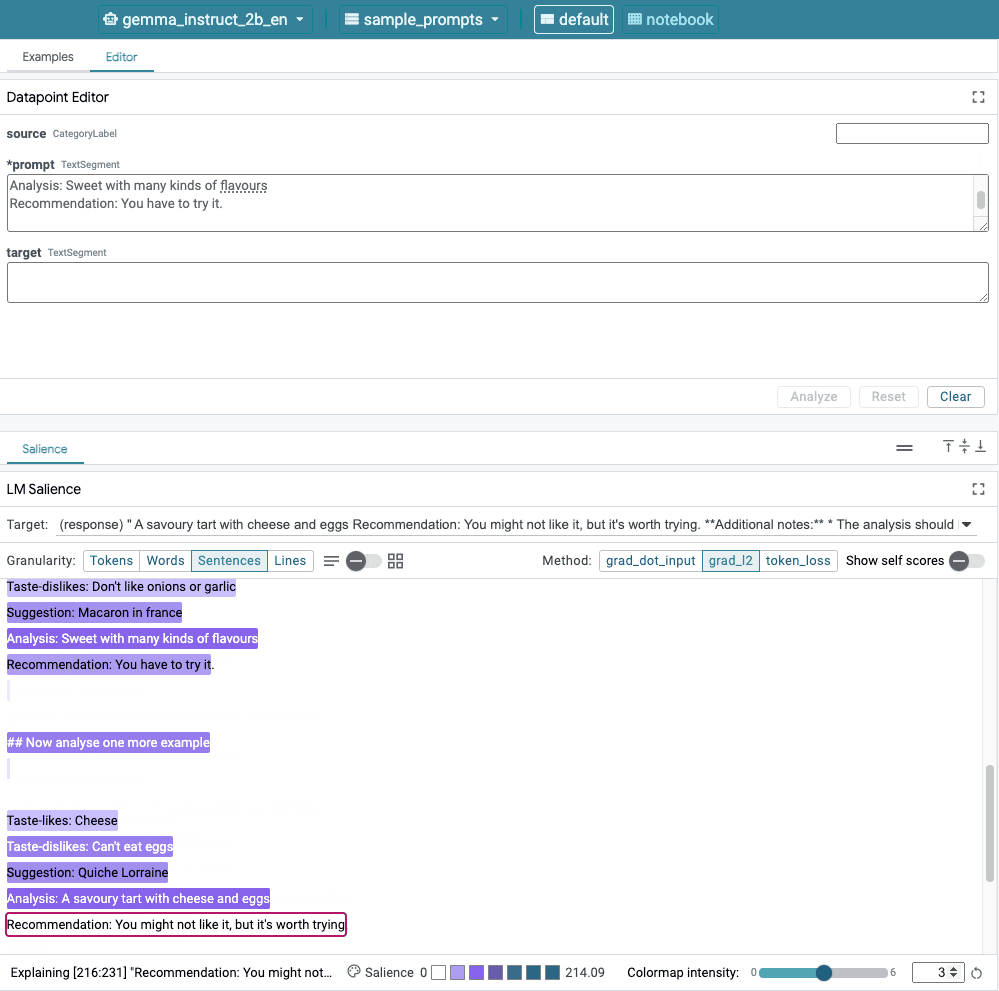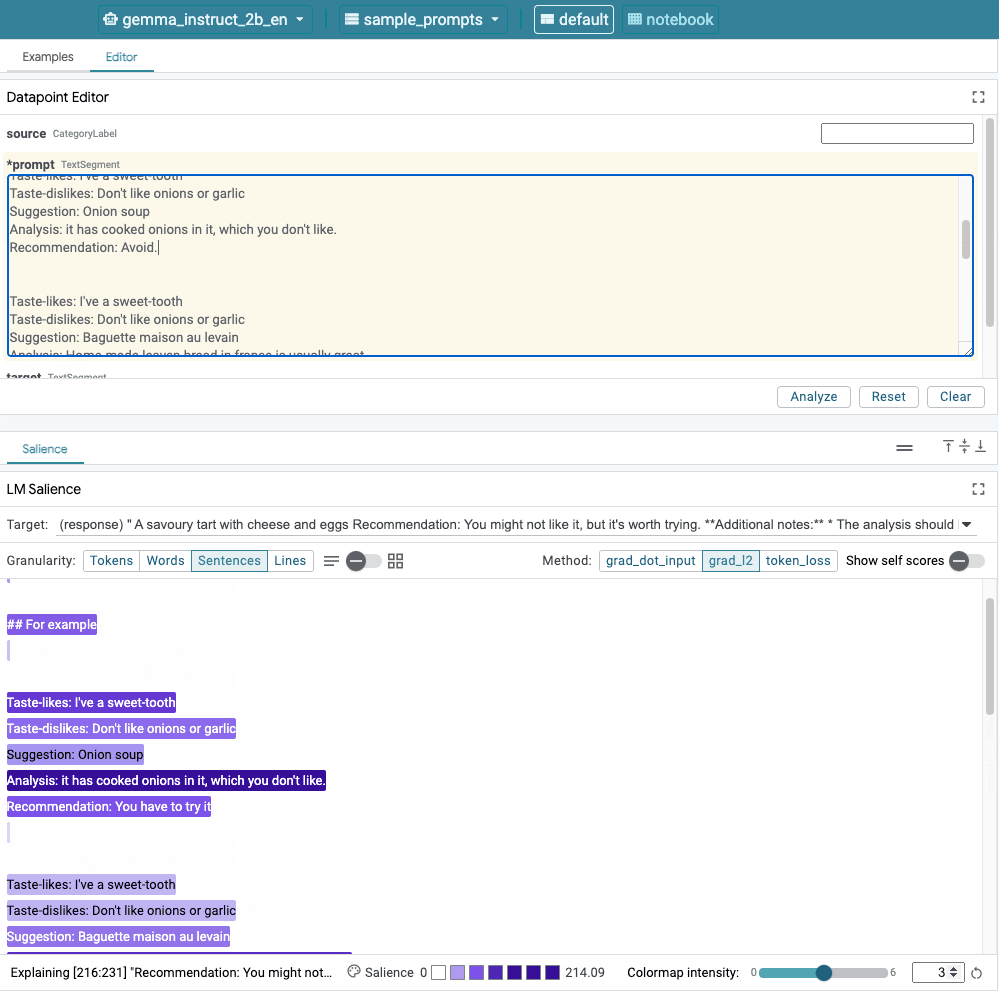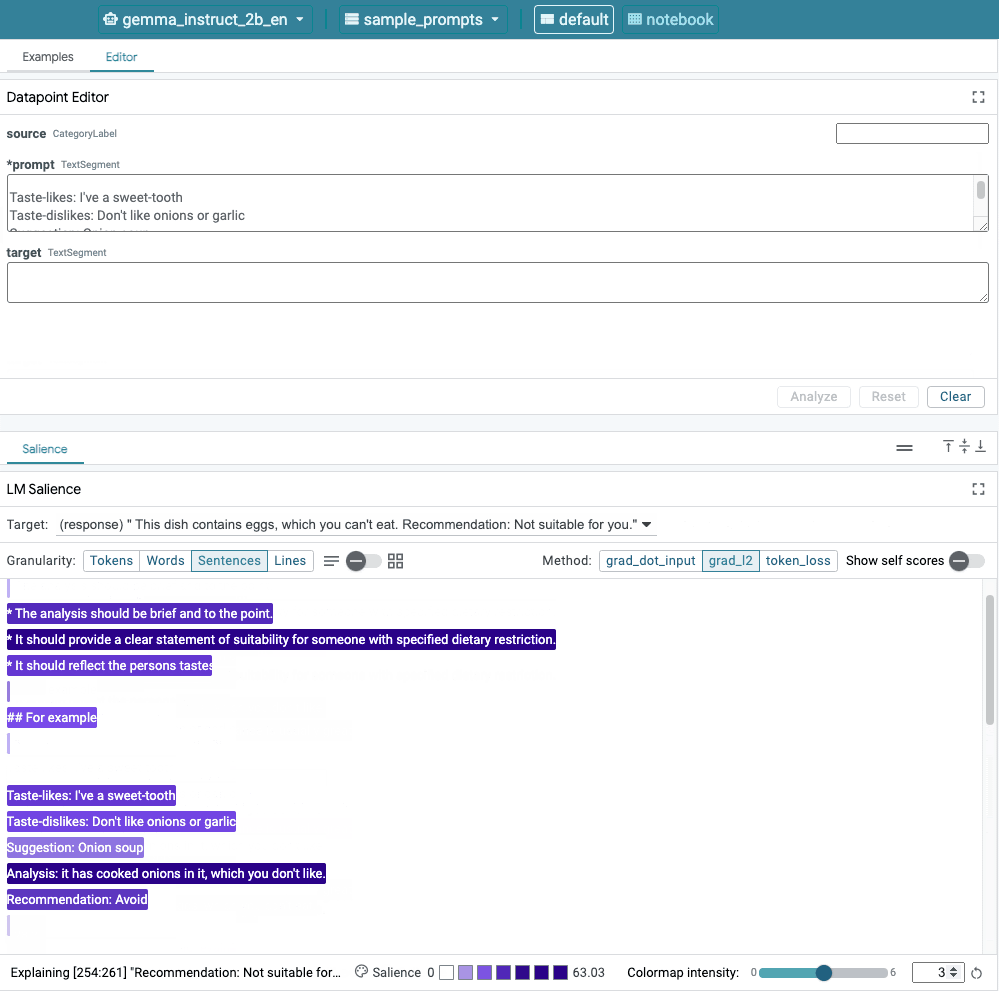
Figure 1. Interface utilisateur de LIT: l'éditeur de points de données en haut aux utilisateurs de modifier leurs requêtes. En bas, le module Salience LM permet pour vérifier les résultats de saillance.
Vous pouvez utiliser LIT sur votre machine locale, dans Colab ou sur Google Cloud.
Inclure les équipes non techniques dans la vérification et l'exploration du modèle
L'interprétabilité doit être un effort d'équipe, impliquant des expertises dans les domaines de la politique, du droit, etc. Le support visuel et la capacité interactive de la LIT à examiner la saillance et à explorer des exemples peuvent aider différents partenaires à partager et à communiquer leurs résultats. Cette approche permet une plus grande diversité de perspective dans l'exploration, la vérification et le débogage du modèle. Exposer vos coéquipiers à ces méthodes techniques peut améliorer leur compréhension du fonctionnement des modèles. Dans En outre, une expertise plus diversifiée dans les premiers tests de modèles peut également aider découvrir des résultats indésirables qui peuvent être améliorés.