
Qualquer abordagem responsável para aplicar a inteligência artificial (IA) precisa incluir políticas de segurança, artefatos de transparência e proteções, mas ser responsável com a IA significa mais do que seguir listas de verificação.
Os produtos de IA generativa são relativamente novos, e os comportamentos de um aplicativo podem variar muito mais do que as formas anteriores de software. Por isso, você deve sondar modelos sendo usados para examinar exemplos de comportamento do modelo e investigar surpresas.
Os comandos são a interface onipresente para interagir com a IA generativa e criar esses comandos é tanto arte quanto ciência. No entanto, existem ferramentas que podem ajudar a melhorar empiricamente os comandos para LLMs, como o Ferramenta de aprendizado de interpretabilidade (LIT, na sigla em inglês). O LIT é uma ferramenta de código aberto para entender e depurar visualmente modelos de IA, que pode ser usada como um depurar para trabalho de engenharia imediato. Siga o tutorial fornecido usando o Colab ou o Codelab.
Analisar modelos Gemma com a LIT
|
|
|
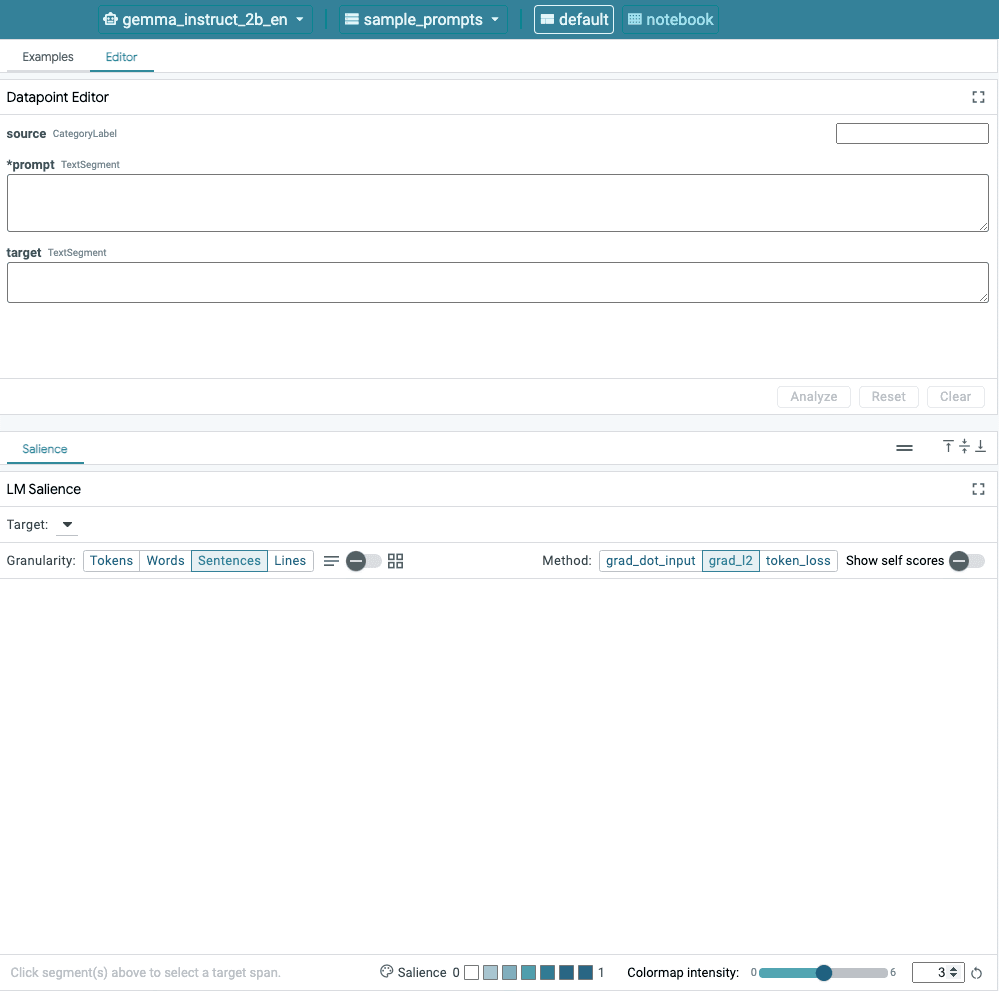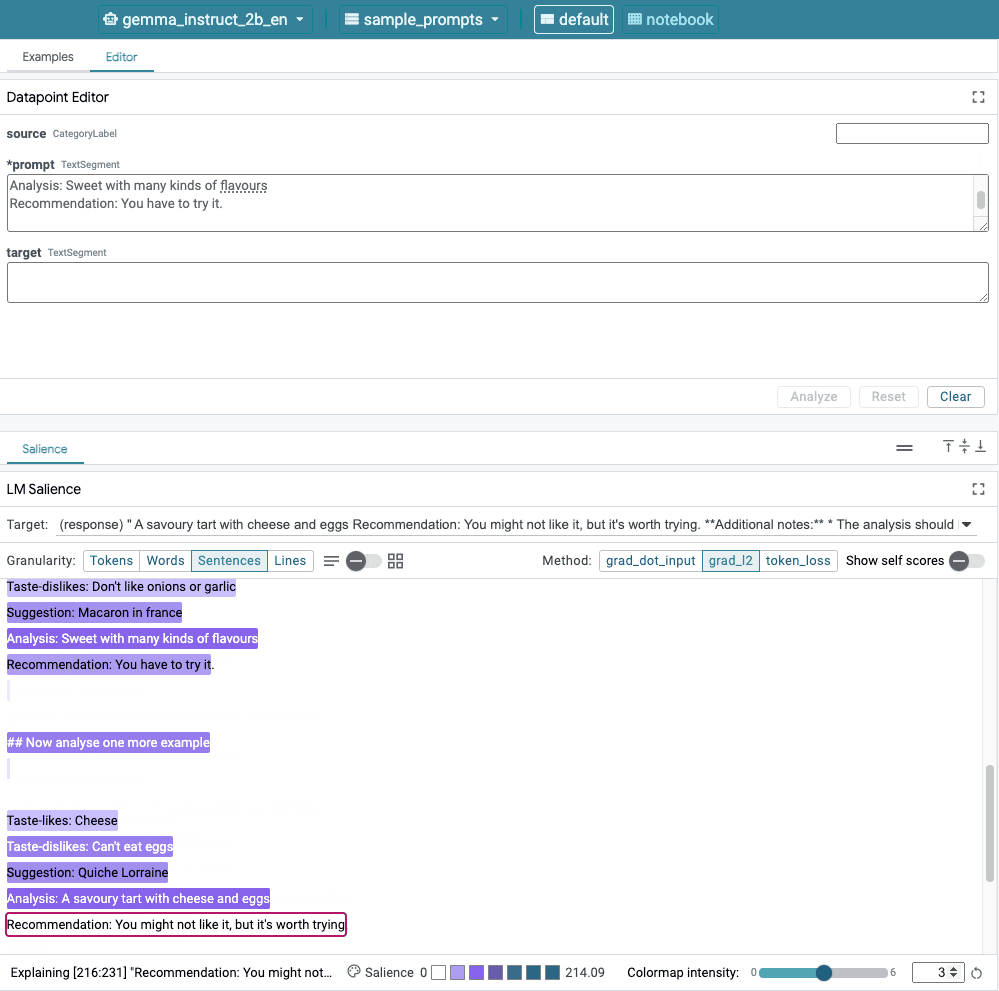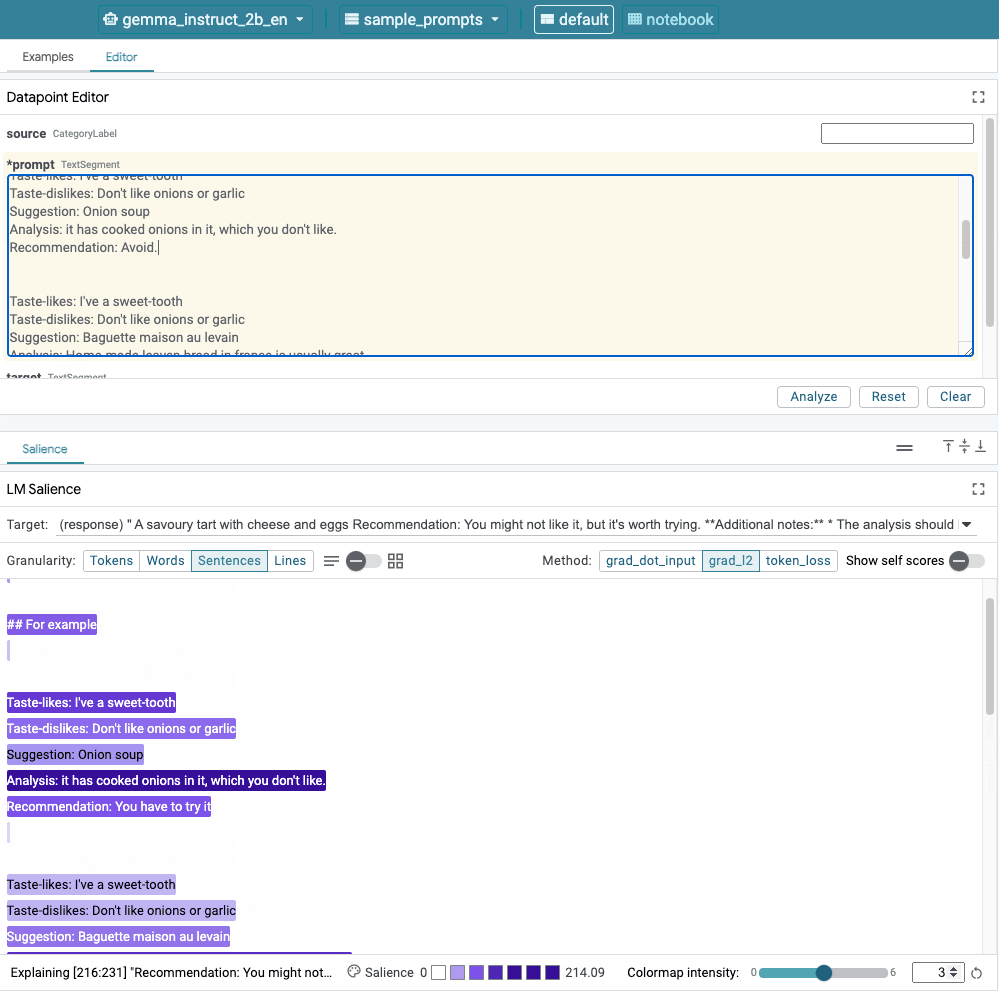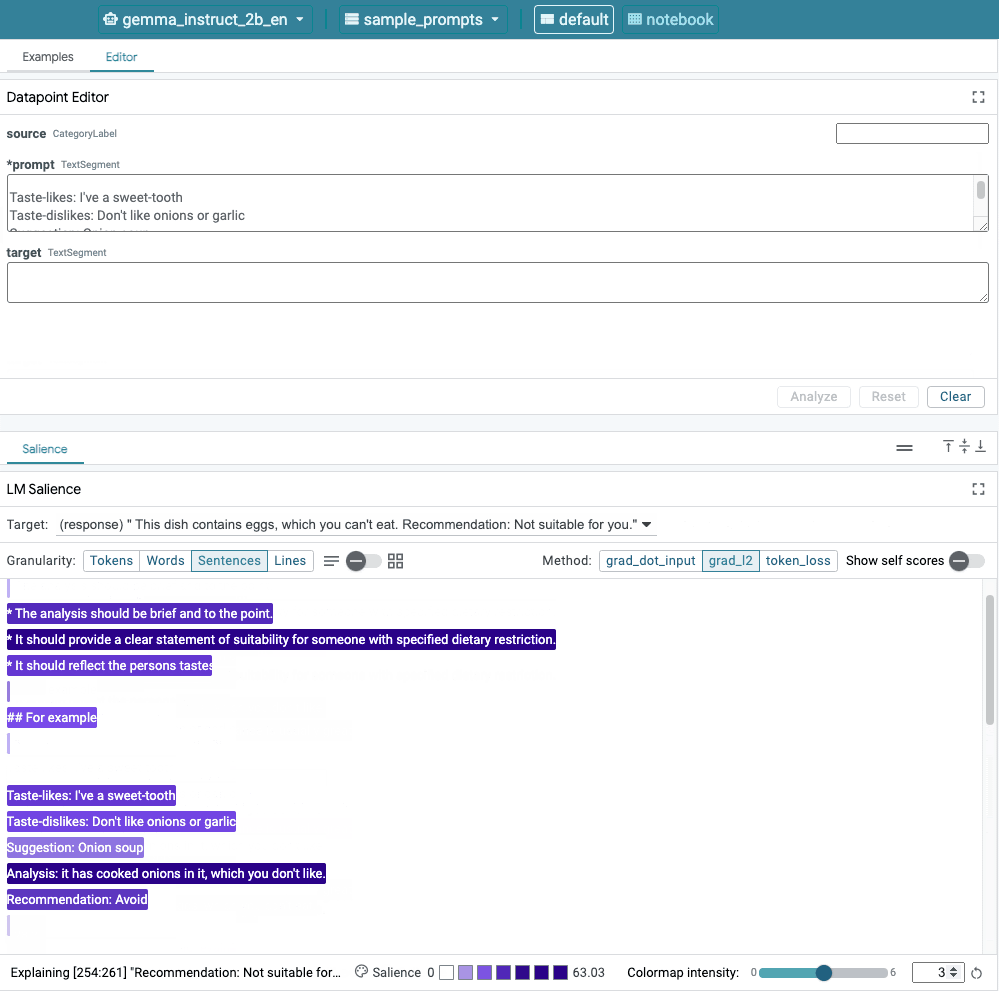
Figura 1. Interface do usuário da LIT: com o editor de pontos de dados na parte de cima, que os usuários editem os comandos. Na parte de baixo, o módulo Salience do LM permite para verificar os resultados de saliência.
É possível usar o LIT na sua máquina local, no Colab ou no Google Cloud.
Incluir equipes não técnicas na investigação e análise detalhada do modelo
A interpretabilidade é um esforço coletivo, que abrange a experiência em políticas, questões legais e muito mais. A capacidade interativa e o meio visual do LIT de examinar a saliência e analisar exemplos podem ajudar diferentes partes interessadas a compartilhar e comunicar descobertas. Essa abordagem pode gerar mais diversidade de perspectiva em exploração, sondagem e depuração do modelo. Ao expor seus colegas a esses e técnicos podem melhorar sua compreensão de como os modelos funcionam. Em Além disso, um conjunto mais diversificado de conhecimentos em testes iniciais de modelos também pode ajudar e revelam resultados indesejáveis que podem ser melhorados.