 Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
使用 LIT 顯示提示偵錯
凡是以負責任的方式應用人工智慧 (AI) 的做法,都應包括
安全性政策
透明度構件,以及
不僅保障使用者安全,對 AI 抱持負責態度的助益
請點選下列檢查清單。
生成式 AI 產品屬於新興技術,應用程式的行為可能會比早期軟體形式更不一致。因此,您應探查所用模型,以便檢查模型行為的範例,並調查意外結果。
提示是與 GenAI 互動的常見介面,而設計這些提示既是藝術,也是科學。不過,您可以使用學習技術可解釋性工具 (LIT) 等工具,根據經驗改善 LLM 提示。LIT 是一項開放原始碼工具,可用於視覺化瞭解及偵錯 AI 模型,並可做為提示工程工作偵錯工具。接著,請參閱
教學課程。
使用 LIT 分析 Gemma 模型
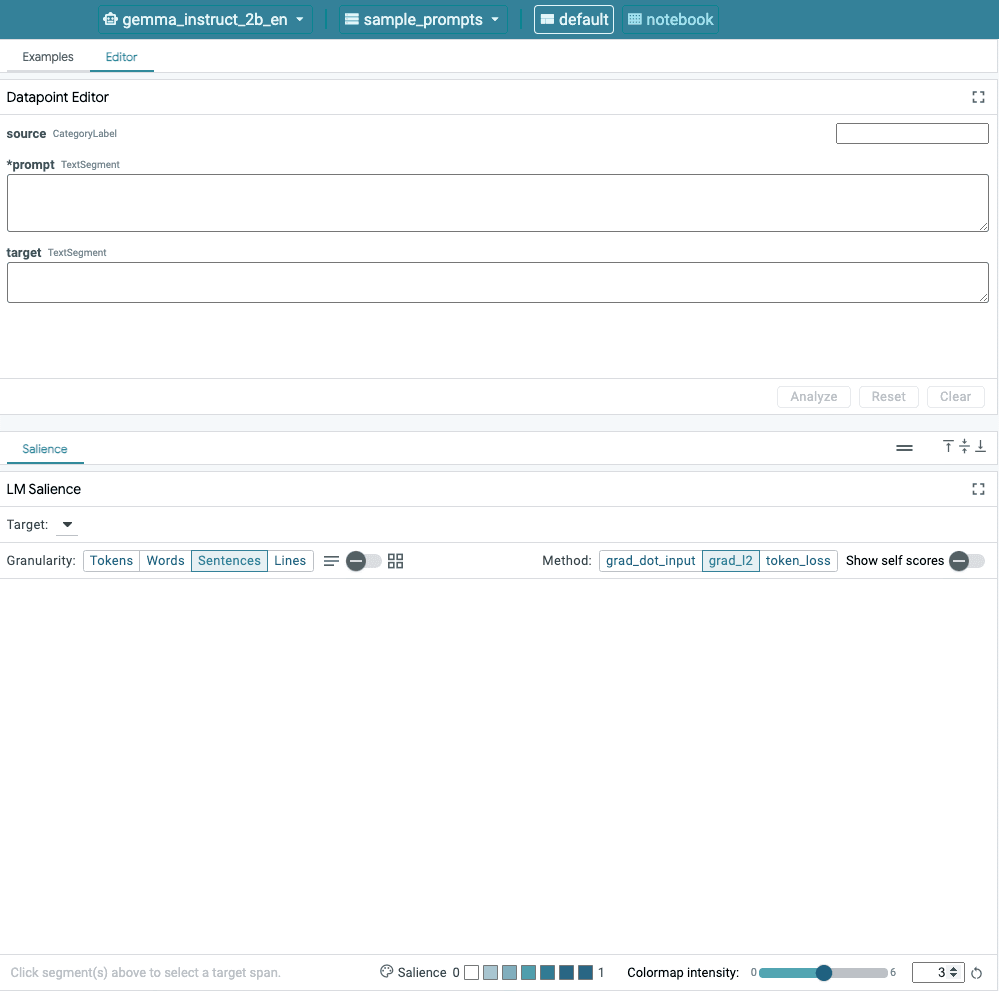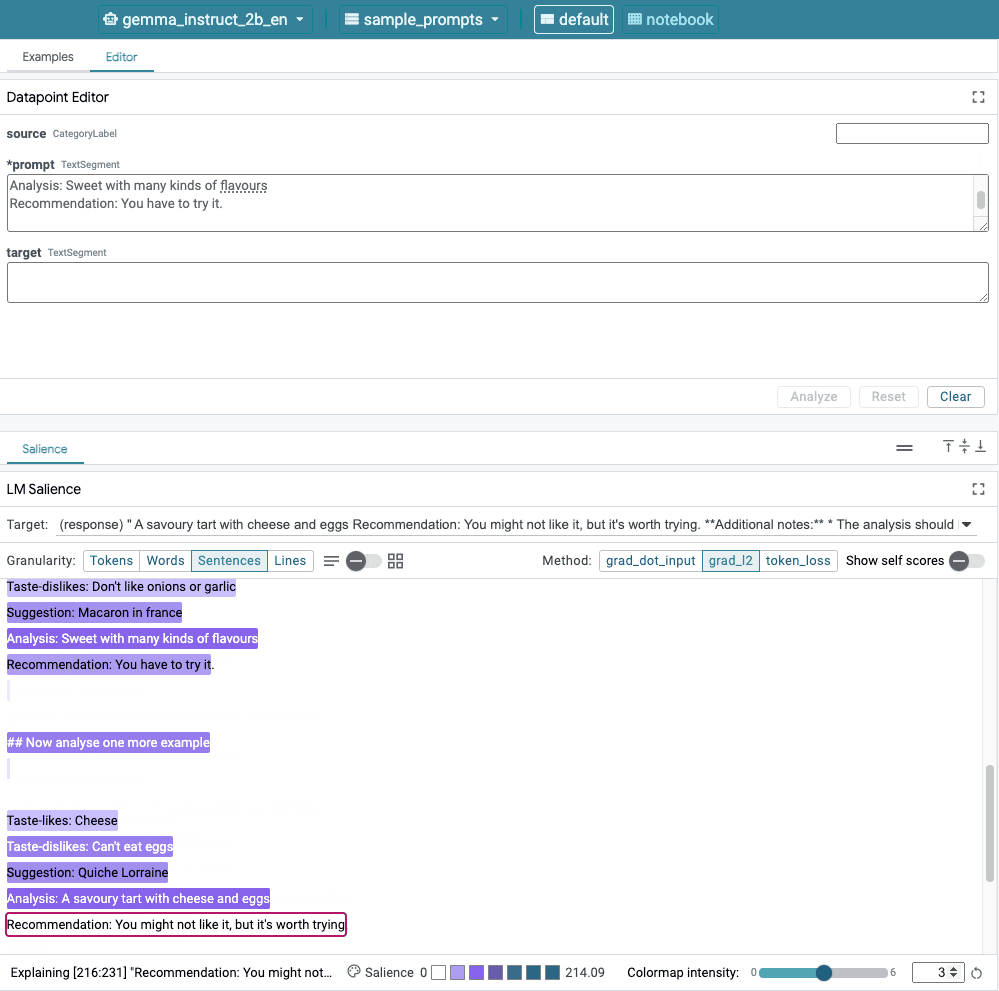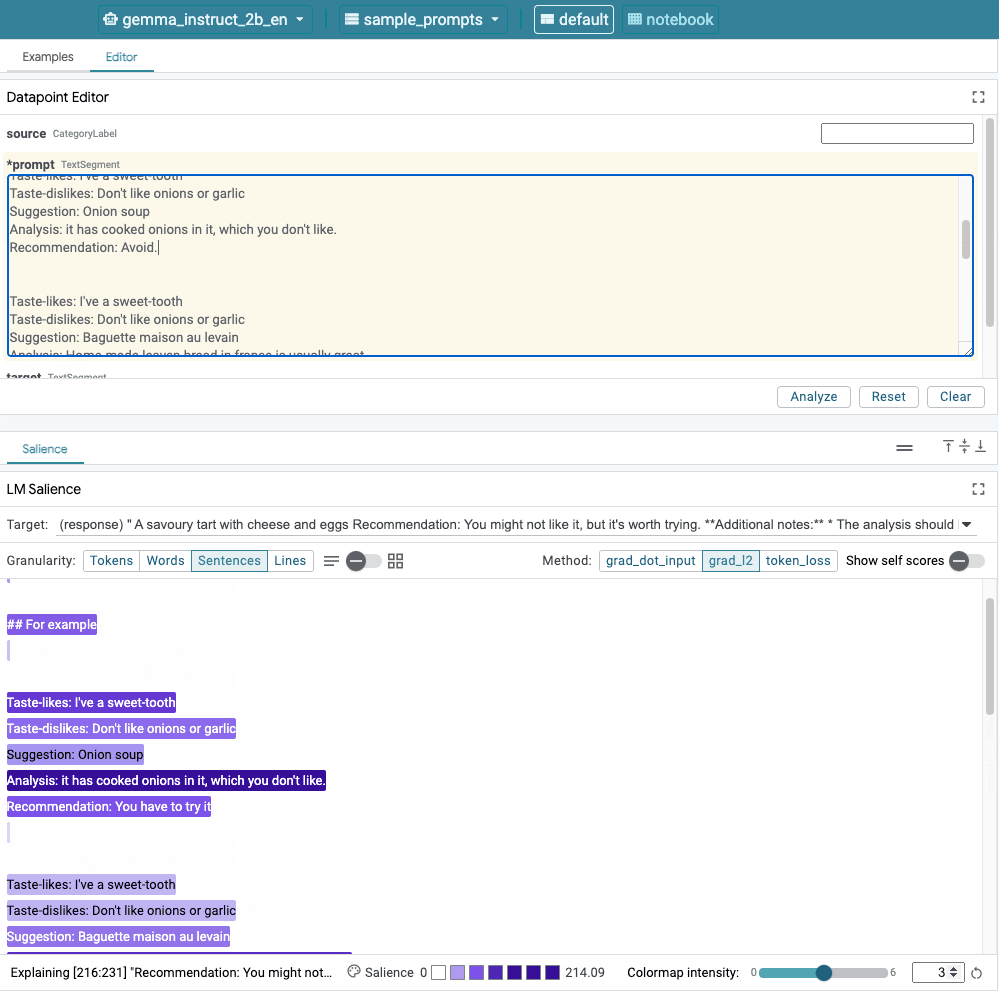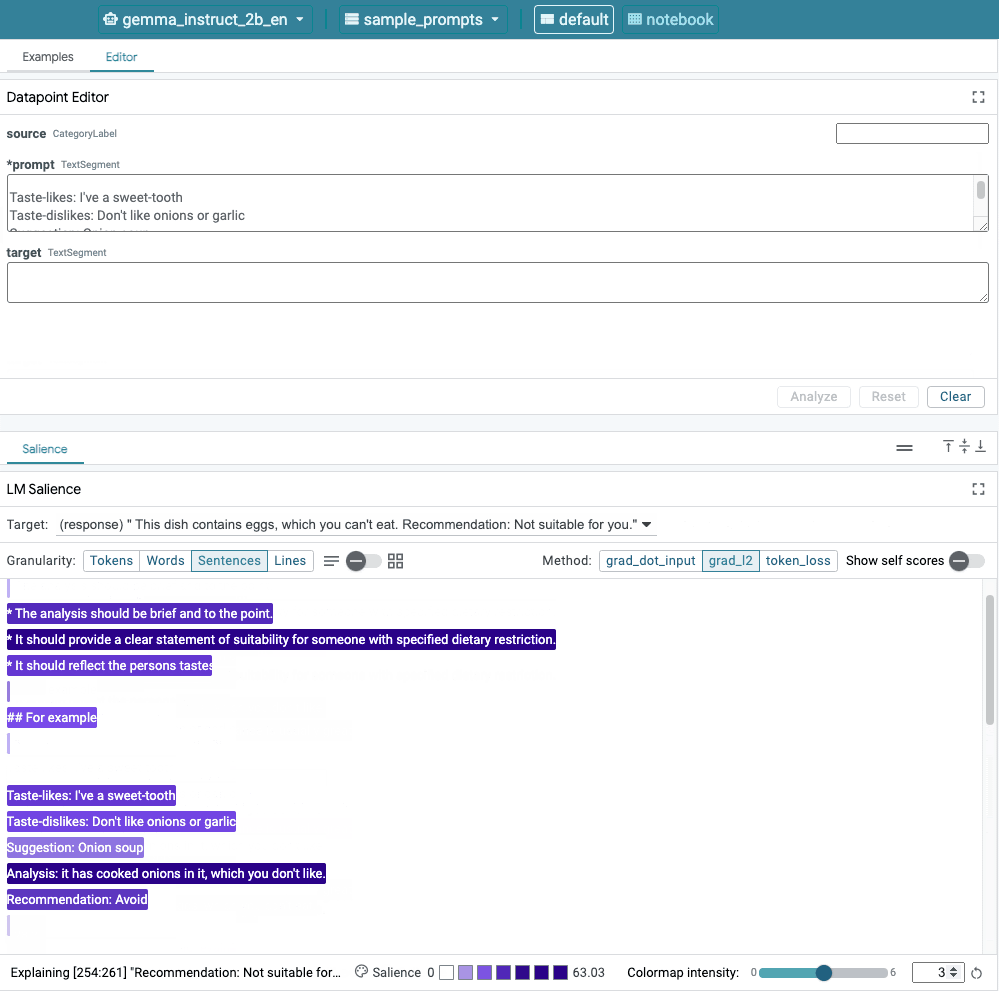
圖 1. LIT 的使用者介面:頂端的資料點編輯器可讓使用者編輯提示。在底部,LM Salience 模組可讓他們查看重要性結果。
您可以在本機電腦、Colab 或 Google Cloud 上使用 LIT。
請非技術團隊參與模型探測和探索
可解釋性是指讓團隊合作,並將跨越專業領域的專業能力串連起來
政策和法律等。透過 LIT 的視覺媒體和互動功能,可以檢視顯著性並探索相關範例,協助不同利害關係人分享和傳達研究結果。這種做法可在模型探索、探測和偵錯時提供更多元的觀點。讓同事瞭解這些技術方法,有助於他們進一步瞭解模型的運作方式。此外,在早期模型測試中,多樣化的專家知識也能協助找出可改善的負面結果。
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2026-01-15 (世界標準時間)。
[[["容易理解","easyToUnderstand","thumb-up"],["確實解決了我的問題","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["缺少我需要的資訊","missingTheInformationINeed","thumb-down"],["過於複雜/步驟過多","tooComplicatedTooManySteps","thumb-down"],["過時","outOfDate","thumb-down"],["翻譯問題","translationIssue","thumb-down"],["示例/程式碼問題","samplesCodeIssue","thumb-down"],["其他","otherDown","thumb-down"]],["上次更新時間:2026-01-15 (世界標準時間)。"],[],[]]
