
将生成式 AI 添加到您的应用中,可为您的 但它也需要敏锐的判断力来维护 您用户的期望。
安全设计
每项支持生成式 AI 的功能都提供了设计安全层的机会。如 如下图所示,安全性的一种思路就是将 启用了此功能的 AI 模型。此模型应符合以下要求:
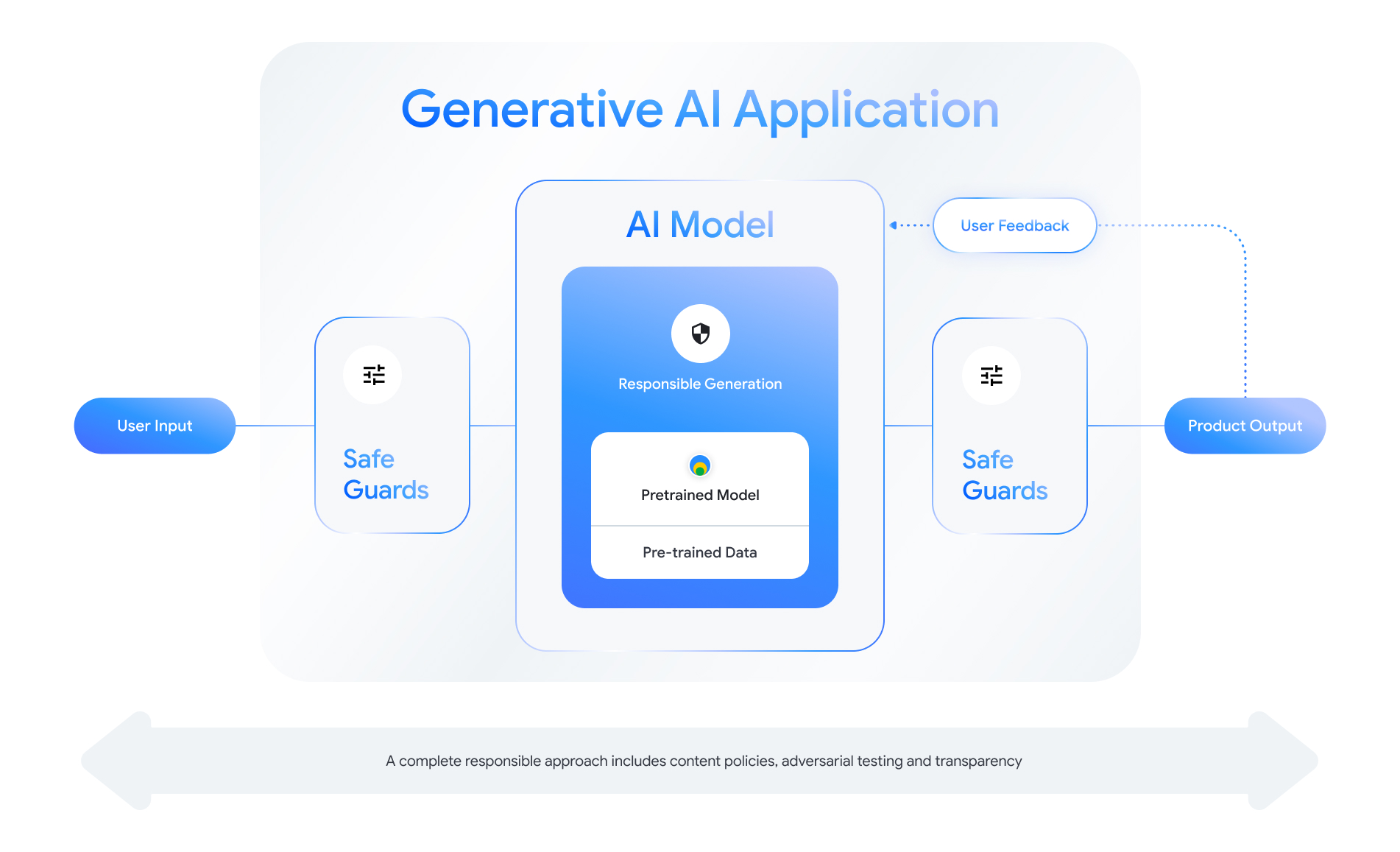
请查看 “打造负责任的 AI 产品”会话 2024 年 Google I/O 大会。 以及有助于加快负责任开发速度的原型设计方法 做法。
此外,您还可以了解以下最佳做法并查看相关示例:
最重要的是,请记住,以合理的方式保障安全和承担责任是 能够自我反思并适应技术、文化和流程 挑战。让您自己和团队定期通过批判性评审您的 以确保取得最佳成效。
定义系统级政策
内容安全政策规定了不允许发布哪些类型的有害内容 使用在线平台你可能比较熟悉各个平台的内容政策 例如 YouTube 或 Google Play。内容 生成式 AI 应用的政策类似:它们规定了 您的应用不应生成的内容,它们可指导您如何调优模型 以及要添加哪些适当的保护措施
您的政策应反映应用的用例。例如, 生成式 AI 产品,旨在根据以下因素为家庭活动提供灵感: 社区建议可能具有禁止生成 暴力性质的内容,因为可能会给用户造成伤害。相反, 一款应用总结了用户提出的科幻故事创意 因为这是美国许多故事的主题, 。
您的安全政策应禁止生成有害内容 或非法内容,并且应指明生成的内容类型符合 为应用设置门槛您还可以考虑添加 具有教育、纪实、科学或艺术目的的内容, 否则可能会被视为有害的内容。
以极为精细的细节定义清晰的政策,包括 提供示例政策例外项,是建立负责任的 产品。您的政策会在模型开发的每个步骤中使用。用于数据 清理或加标签时,不精确可能会导致数据标记错误、过度移除或 数据移除不足,这将影响模型的安全响应。对于 出于评估目的,如果政策定义不合理,会导致高评分者之间 方差,从而更加难以确定您的模型是否符合您的安全要求 标准。
假设性政策(仅用于说明)
下面列举了一些示例来说明,您可以考虑为 只要它们与您的使用情形相符即可
| 政策类别 | 政策 |
|---|---|
| 敏感的个人身份信息 (SPII) | 应用不得读出包含敏感信息和个人身份信息 信息(例如电子邮件、信用卡号或 个人的社会保障号)。 |
| 仇恨言论 | 应用不会生成负面或有害内容 针对身份和/或受保护特征(例如种族诋毁、 宣扬歧视、煽动对受保护群体实施暴力的行为 群组)。 |
| 骚扰内容 | 应用不得生成恶意、恐吓、欺凌或 或针对其他个人的侮辱性内容(例如身体 威胁、否认悲剧事件、诋毁受害者 暴力内容)。 |
| 危险内容 | 应用不会生成关于伤害行为的说明或建议 (例如使用或制造枪支和 爆炸装置, 宣扬恐怖主义, 说明 自杀)。 |
| 露骨色情内容 | 应用不会生成包含引用 性行为或其他淫秽内容(如露骨色情) 说明、旨在引起性欲的内容)。 |
| 允许访问有害商品和服务 | 应用不得生成宣传或支持 接触可能有害的商品、服务和活动(例如 为赌博、药品和 烟花、色情服务)。 |
| 恶意内容 | 应用不会生成关于执行非法操作的说明 或欺骗活动(例如,生成钓鱼式攻击、垃圾邮件或 意在追求大众募集和越狱的内容)。 |
透明度制品
对于开发者而言,文档是实现信息透明的关键方法, 政府机构、政策参与者和最终用户。这可能包括 发布详细的技术报告,或者发布模型、数据和系统卡片, 根据安全性要求和其他模型以适当的方式 评估。透明度工件不仅仅是通信工具;他们 还为 AI 研究人员、部署者和下游开发者提供了有关 负责任地使用模型。这些信息对 了解该模型的详情。
您可以参考以下透明度准则:
- 在用户与实验性功能互动时明确说明 生成式 AI 技术,并强调了出现意外模型的可能性 行为
- 提供关于生成式 AI 服务或产品的全面文档 使用易于理解的语言来制作游戏。考虑采用结构化发布方式 透明度工件,例如模型卡片。这些卡片提供了 对模型的预期用途,并总结 在整个模型开发过程中执行的操作。
- 向用户展示他们该如何提供反馈,以及他们如何拥有控制权,例如
以:
<ph type="x-smartling-placeholder">
- </ph>
- 提供相应机制,帮助用户验证基于事实的问题
- 用于提供用户反馈的“我喜欢”和“不喜欢”图标
- 用于报告问题和提供对 快速响应支持的链接 用户反馈
- 用于存储或删除用户活动的用户控件
安全的 AI 系统
支持生成式 AI 的应用存在复杂的攻击面 因此需要比常规应用更加多样化的缓解措施。 Google 的安全 AI 框架 (SAIF) 可全面 概念框架,考虑如何设计支持生成式 AI 的应用 安全使用此框架可帮助您评估 匹配、对抗性评估和 safeguard,可以有效地帮助保护您的应用 但请注意,这些仅仅是入门部分其他更改 可能需要利用组织做法、监控和提醒功能, 并根据您的具体应用场景和情境实现安全目标。
开发者资源
生成式 AI 政策示例:
- Cloud Gemini API 和 PaLM API 提供了 可作为建立安全基础的安全属性列表 政策。
- “Google Analytics 4 媒体资源” 2023 年 Google AI 原则进度更新。
- MLCommons 协会,这是一个基于 开放协作以改进 AI 系统的理念,参考 6 在评估模型以提升 AI 安全性的同时, AI 安全基准。
在整个 但现有的模型卡片可以作为基础, 创建您自己的模板: