
7 ноября 2024 г.
Расширение возможностей ИИ-помощников в программировании с помощью анализа расширенного контекста от Gemini Models.

Одно из самых перспективных направлений в применении длинных контекстных окон — это генерация и понимание кода. Большие кодовые базы требуют глубокого понимания сложных взаимосвязей и зависимостей, с чем традиционные модели ИИ с трудом справляются. Расширяя объем кода за счет больших контекстных окон, мы можем достичь нового уровня точности и полезности в генерации и понимании кода.
Мы объединились с компанией Sourcegraph, создателями помощника по программированию Cody AI , поддерживающего LLM-ы, такие как Gemini 1.5 Pro и Flash , чтобы изучить потенциал длительных контекстных окон в реальных сценариях программирования. Ориентация Sourcegraph на интеграцию поиска кода и интеллектуальных функций в генерацию кода с помощью ИИ, а также успешное внедрение Cody в предприятиях с большими и сложными кодовыми базами, таких как Palo Alto Networks и Leidos, сделали их идеальным партнером для этого исследования.
Подход и результаты Sourcegraph
Sourcegraph сравнил производительность Cody с контекстным окном в 1 миллион токенов (используя Google Gemini 1.5 Flash) с его рабочей версией. Это прямое сравнение позволило им выделить преимущества расширенного контекста. Они сосредоточились на ответах на технические вопросы, что является важнейшей задачей для разработчиков, работающих с большими кодовыми базами. Они использовали набор данных сложных вопросов, требующих глубокого понимания кода.
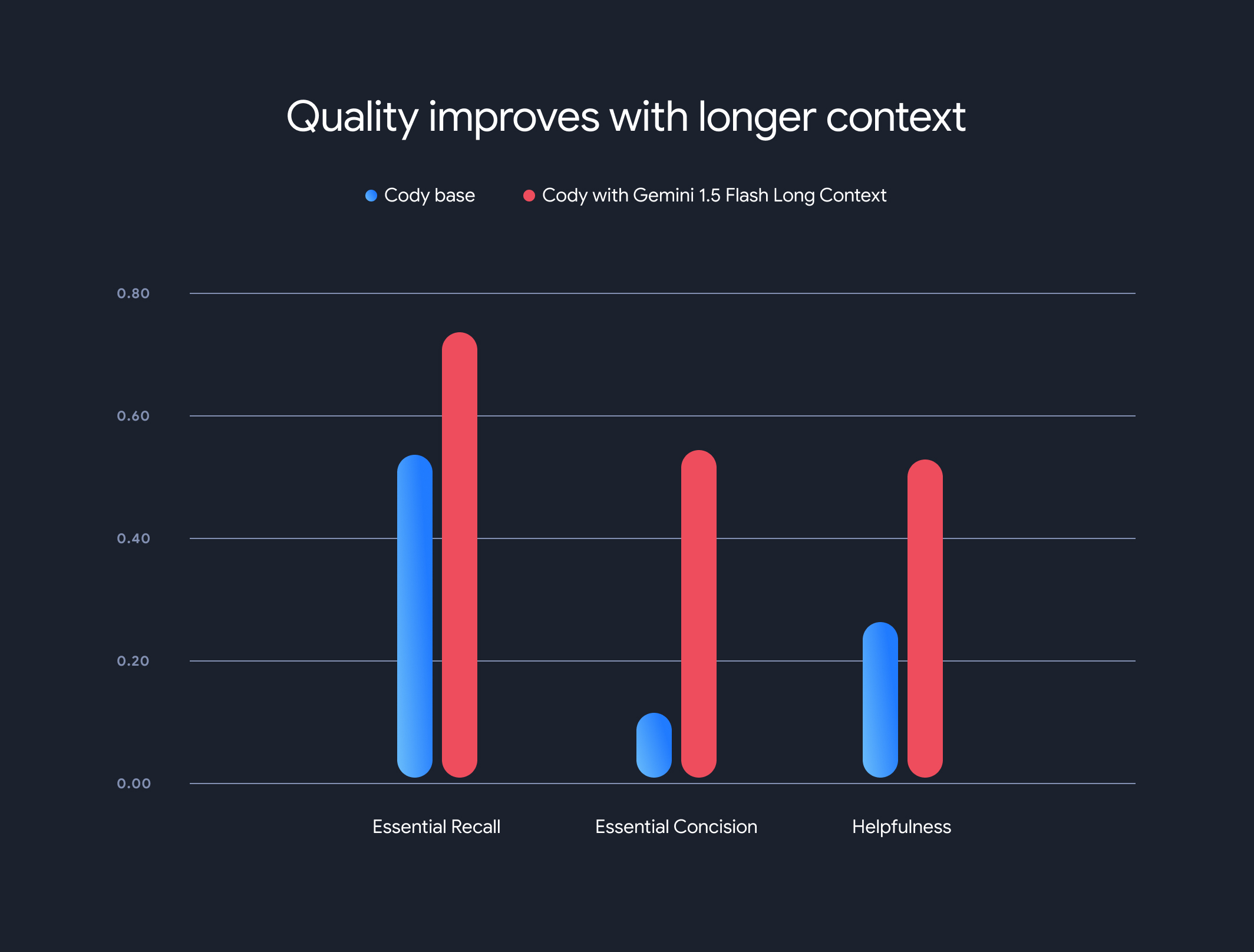
Результаты оказались поразительными. Три ключевых показателя Sourcegraph — запоминание основной информации, краткость изложения и полезность — продемонстрировали значительное улучшение при использовании более длинного контекста.
Важное напоминание: Доля ключевых фактов в ответе существенно возросла.
Краткость: Доля важных фактов, нормализованная по длине ответа, также улучшилась, что указывает на более краткие и релевантные ответы.
Полезность: Общий показатель полезности, нормализованный по длине ответа, значительно повысился, что указывает на более удобный для пользователя интерфейс.
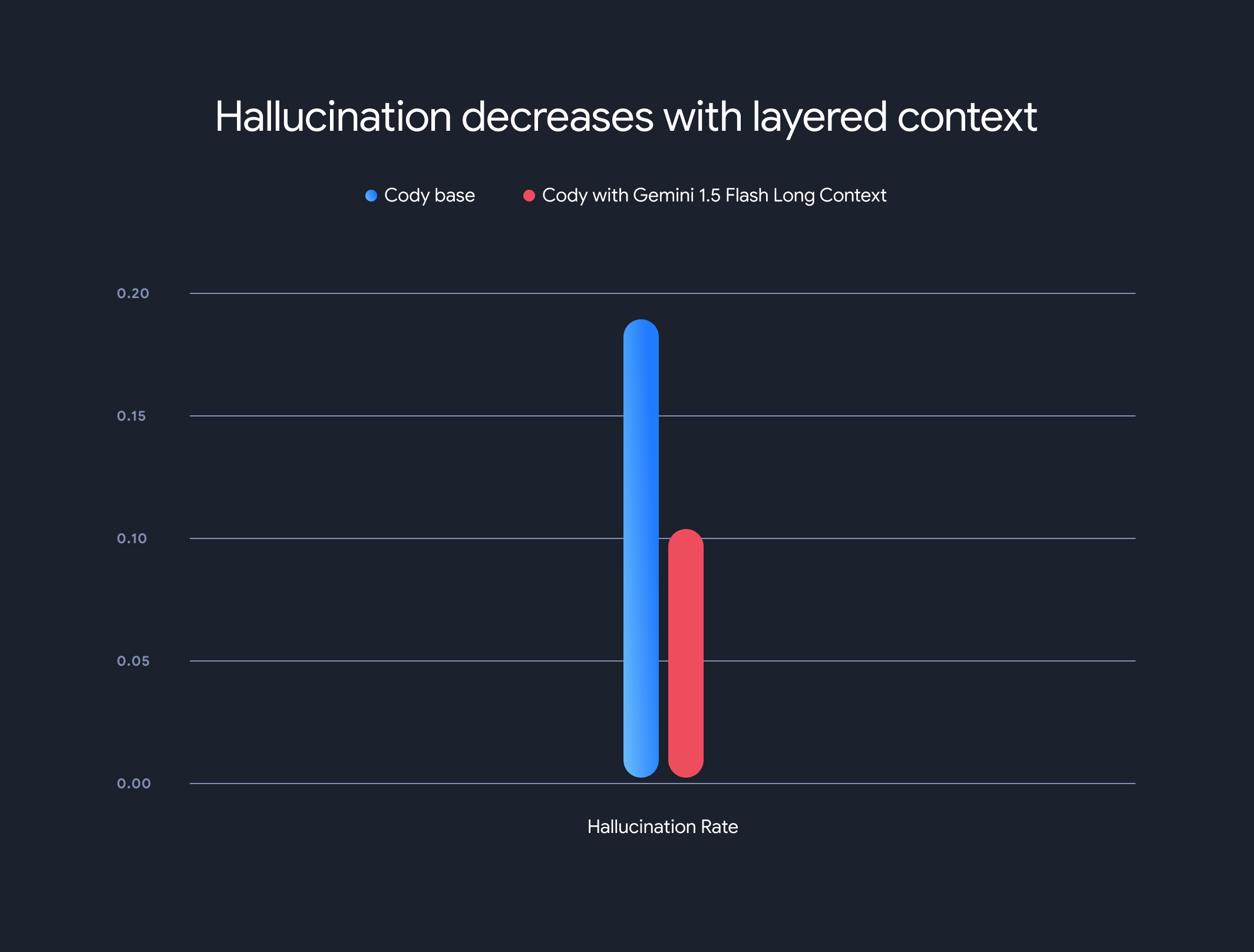
Кроме того, использование моделей с длинным контекстом резко снизило общий уровень галлюцинаций (генерацию фактически неверной информации). Уровень галлюцинаций снизился с 18,97% до 10,48%, что является значительным улучшением точности и надежности.
Компромиссы и будущее направление
Хотя преимущества длинных контекстов значительны, существуют и компромиссы. Время до получения первого токена увеличивается линейно с длиной контекста. Для решения этой проблемы Sourcegraph реализовал механизм предварительной выборки и многоуровневую архитектуру контекстной модели для кэширования состояния выполнения модели. В моделях Gemini 1.5 Flash и Pro с длинным контекстом это оптимизировало время до получения первого токена с 30-40 секунд до примерно 5 секунд для контекстов размером 1 МБ — значительное улучшение для генерации кода в реальном времени и технической поддержки.
Это сотрудничество демонстрирует преобразующий потенциал моделей с длинным контекстом в революционном преобразовании понимания и генерации кода. Мы рады сотрудничать с такими компаниями, как Sourcegraph, чтобы и дальше открывать для себя еще больше инновационных приложений и парадигм с большими контекстными окнами.
Чтобы глубже изучить подробные методологии оценки, критерии и анализ Sourcegraph, включая наглядные примеры, обязательно ознакомьтесь с их подробной статьей в блоге .
Соответствующие тематические исследования

AgentOps
Узнайте, как AgentOps обеспечивает экономичное и мощное наблюдение за агентами на основе LLM для предприятий с использованием API Gemini.

Подслой
Узнайте, как основанная на Ruby платформа для создания ИИ-агентов позволяет командам разработчиков повысить производительность благодаря возможностям моделей Gemini.

Комнаты
Расширенные возможности взаимодействия с аватарами благодаря текстовым и аудиофункциям Gemini 2.0.