API Gemini предоставляет параметры безопасности, которые можно настроить на этапе прототипирования, чтобы определить, требуется ли вашему приложению более или менее строгая конфигурация безопасности. Вы можете настроить эти параметры в четырех категориях фильтров, чтобы ограничить или разрешить определенные типы контента.
В этом руководстве описано, как API Gemini обрабатывает параметры безопасности и фильтрацию, а также как вы можете изменить параметры безопасности для своего приложения.
Защитные фильтры
Регулируемые фильтры безопасности API Gemini охватывают следующие категории:
| Категория | Описание |
|---|---|
| Домогательство | Негативные или оскорбительные комментарии, направленные против личности и/или защищаемых характеристик. |
| Язык ненависти | Контент, содержащий грубость, неуважение или нецензурную лексику. |
| Откровенно сексуального характера | Содержит отсылки к сексуальным действиям или другому непристойному контенту. |
| Опасный | Способствует, облегчает или поощряет совершение вредоносных действий. |
These categories are defined in HarmCategory . You can use these filters to adjust what's appropriate for your use case. For example, if you're building video game dialogue, you may deem it acceptable to allow more content that's rated as Dangerous due to the nature of the game.
В дополнение к настраиваемым фильтрам безопасности, API Gemini имеет встроенную защиту от основных угроз, таких как контент, представляющий опасность для детей. Такие угрозы всегда блокируются и не могут быть скорректированы.
уровень фильтрации контента для обеспечения безопасности
API Gemini классифицирует уровень вероятности небезопасности контента как HIGH , MEDIUM , LOW или NEGLIGIBLE .
API Gemini блокирует контент на основе вероятности его небезопасности, а не степени опасности. Это важно учитывать, поскольку некоторый контент может иметь низкую вероятность небезопасности, даже если степень опасности может быть высокой. Например, сравним предложения:
- Робот ударил меня кулаком.
- Робот меня изрубил.
Первое предложение может указывать на более высокую вероятность опасности, но второе может восприниматься как более серьезное с точки зрения насилия. Учитывая это, важно тщательно протестировать и оценить необходимый уровень блокировки для поддержки ваших основных сценариев использования, минимизируя при этом вред для конечных пользователей.
Фильтрация для обеспечения безопасности по запросу
Вы можете настроить параметры безопасности для каждого запроса к API. При отправке запроса контент анализируется и ему присваивается рейтинг безопасности. Рейтинг безопасности включает категорию и вероятность классификации вреда. Например, если контент был заблокирован из-за высокой вероятности категории «домогательства», возвращаемый рейтинг безопасности будет иметь категорию HARASSMENT и вероятность вреда, установленную на HIGH .
Ввиду присущей модели безопасности, дополнительные фильтры по умолчанию отключены . Если вы решите включить их, вы сможете настроить систему на блокировку контента в зависимости от вероятности его небезопасности. Поведение модели по умолчанию охватывает большинство сценариев использования, поэтому следует изменять эти настройки только в том случае, если это постоянно требуется для вашего приложения.
В следующей таблице описаны параметры блокировки, которые можно настроить для каждой категории. Например, если вы установите параметр блокировки « Блокировать немного» для категории «Разжигание ненависти» , будет заблокирован весь контент, имеющий высокую вероятность быть разжигающим ненависть. Но всё, что имеет более низкую вероятность, будет разрешено.
| Thredhold (Google AI Studio) | Пороговое значение (API) | Описание |
|---|---|---|
| Выключенный | OFF | Отключите защитный фильтр |
| Блокировать нет | BLOCK_NONE | Всегда показывайте контент, независимо от вероятности его наличия. |
| Блок несколько | BLOCK_ONLY_HIGH | Блокировка при высокой вероятности наличия небезопасного контента. |
| Заблокировать некоторые | BLOCK_MEDIUM_AND_ABOVE | Блокировка при средней или высокой вероятности наличия небезопасного контента. |
| Блокировать большинство | BLOCK_LOW_AND_ABOVE | Блокировка при низкой, средней или высокой вероятности наличия небезопасного контента. |
| Н/Д | HARM_BLOCK_THRESHOLD_UNSPECIFIED | Пороговое значение не указано, блокировка осуществляется с использованием порогового значения по умолчанию. |
Если пороговое значение не задано, по умолчанию для моделей Gemini 2.5 и 3 значение порога блокировки отключено .
Эти параметры можно установить для каждого запроса, отправляемого в генеративный сервис. Подробности см. в справочнике API HarmBlockThreshold .
Обратная связь по вопросам безопасности
generateContent возвращает объект GenerateContentResponse , который содержит информацию о безопасности.
Обратная связь по запросу включена в promptFeedback . Если задан promptFeedback.blockReason , это означает, что содержимое запроса было заблокировано.
Обратная связь от кандидата на ответ включена в Candidate.finishReason и Candidate.safetyRatings . Если содержимое ответа было заблокировано, а finishReason имел значение SAFETY , вы можете просмотреть safetyRatings для получения более подробной информации. Заблокированное содержимое не возвращается.
Настройте параметры безопасности
В этом разделе описано, как настроить параметры безопасности как в Google AI Studio, так и в вашем коде.
Google AI Studio
Вы можете настроить параметры безопасности в Google AI Studio.
В панели «Параметры запуска» в разделе «Дополнительные параметры» щелкните «Параметры безопасности» , чтобы открыть модальное окно « Параметры безопасности запуска» . В этом окне с помощью ползунков можно настроить уровень фильтрации контента по категориям безопасности:
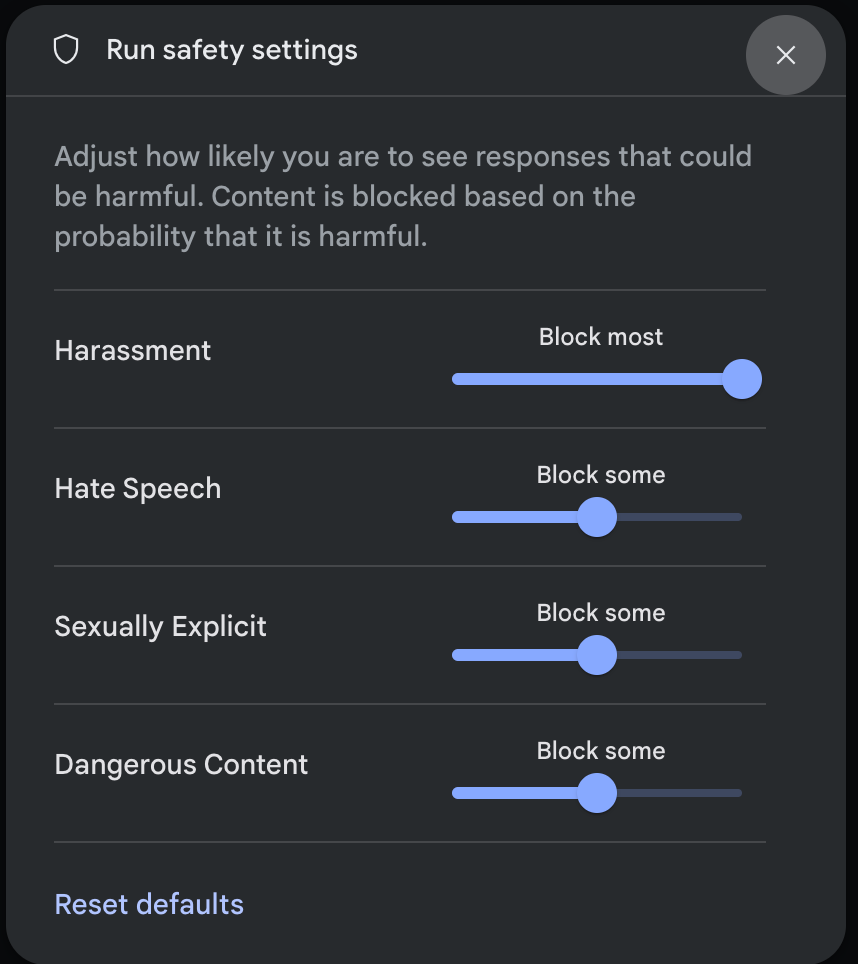
При отправке запроса (например, задавая модели вопрос) появляется «Содержание заблокировано» , если содержимое запроса заблокировано. Чтобы увидеть более подробную информацию, наведите указатель мыши на текст «Содержание заблокировано», чтобы увидеть категорию и вероятность классификации как причиняющего вред.
Примеры кода
Следующий фрагмент кода показывает, как установить параметры безопасности в вызове GenerateContent . Он задает пороговое значение для категории «Разжигание ненависти» ( HARM_CATEGORY_HATE_SPEECH ). Установка этого значения в категорию BLOCK_LOW_AND_ABOVE блокирует любой контент, который имеет низкую или высокую вероятность быть разжиганием ненависти. Чтобы понять параметры пороговых значений, см. раздел «Фильтрация безопасности для каждого запроса» .
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Идти
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Следующие шаги
- Для получения более подробной информации о полном API обратитесь к справочнику API .
- Ознакомьтесь с рекомендациями по технике безопасности , чтобы получить общее представление о мерах безопасности при разработке с использованием LLM-продуктов.
- Узнайте больше об оценке вероятности и тяжести от команды Jigsaw.
- Узнайте больше о продуктах, которые способствуют разработке решений в области безопасности, таких как API Perspective . * Вы можете использовать эти настройки безопасности для создания классификатора токсичности. См. пример классификации , чтобы начать работу.