
Einsatz spezieller Prozessoren wie GPUs, NPUs oder DSPs für Hardware Beschleunigung kann die Inferenzleistung erheblich verbessern (bis zu 10-mal schneller Inferenz) und die Nutzererfahrung Ihrer ML-fähigen Android- . Angesichts der Vielzahl von Hardware und Treibern, die Ihre Nutzer Die optimale Konfiguration der Hardwarebeschleunigung für jeden Nutzer kann eine echte Herausforderung sein. Außerdem wird die falsche Konfiguration auf einer kann aufgrund der hohen Latenz oder, in einigen seltenen Fällen, zu einer schlechten Nutzererfahrung führen. -Fällen, Laufzeitfehlern oder Genauigkeitsproblemen aufgrund von Hardware-Inkompatibilitäten.
Acceleration Service for Android ist eine API, mit der Sie
optimale Konfiguration der Hardwarebeschleunigung für ein bestimmtes Nutzergerät und Ihr
.tflite-Modell verwenden und gleichzeitig das Risiko von Laufzeitfehlern oder Genauigkeitsproblemen minimieren.
Acceleration Service wertet verschiedene Beschleunigungskonfigurationen auf Nutzer aus mit Ihrem LiteRT-Gerät durch Ausführen interner Inferenz-Benchmarks Modell. Diese Testläufe dauern in der Regel nur wenige Sekunden, je nachdem, Modell. Sie können die Benchmarks vor der Inferenz einmal auf jedem Nutzergerät ausführen speichern und bei der Inferenz verwenden. Diese Benchmarks werden Out-of-Process; Dadurch wird das Risiko von App-Abstürzen minimiert.
Geben Sie Ihr Modell, die Datenstichproben und die erwarteten Ergebnisse (goldene Eingaben und Ausgaben) und der Acceleration Service führt eine interne TFLite-Inferenz aus um Ihnen Hardwareempfehlungen geben zu können.
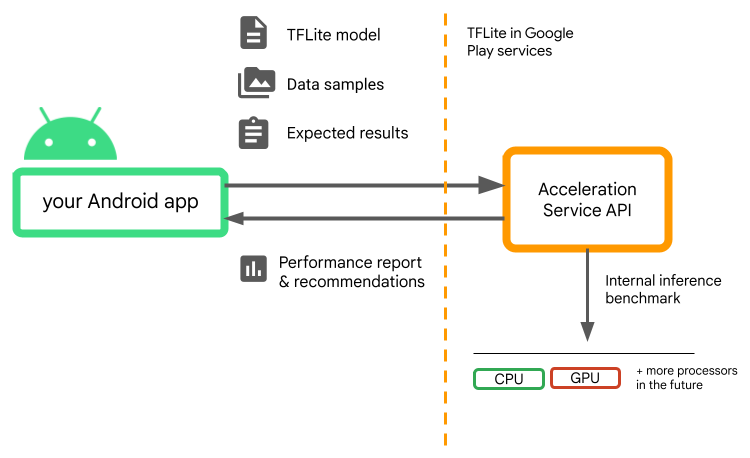
Acceleration Service ist Teil des benutzerdefinierten ML-Stacks von Android und funktioniert mit LiteRT in Google Play-Diensten
Abhängigkeiten zum Projekt hinzufügen
Fügen Sie der build.gradle-Datei Ihrer Anwendung die folgenden Abhängigkeiten hinzu:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
Die Acceleration Service API funktioniert mit LiteRT in Google Play. Dienste. Wenn Sie noch keine über die Play-Dienste bereitgestellte LiteRT-Laufzeit verwenden, müssen Ihre dependencies aktualisieren.
Acceleration Service API verwenden
Erstellen Sie zuerst die Konfiguration für die Beschleunigung, um den Acceleration Service zu verwenden
das Sie für Ihr Modell bewerten möchten (z. B. GPU mit OpenGL). Erstellen Sie dann
Validierungskonfiguration mit Ihrem Modell, einigen Beispieldaten und dem erwarteten
Modellausgabe. Rufen Sie schließlich validateConfig() auf und übergeben Sie
und Validierungskonfiguration.

Beschleunigungskonfigurationen erstellen
Beschleunigungskonfigurationen sind Darstellungen der Hardwarekonfigurationen die während der Ausführungszeit in Delegierte umgewandelt werden. Der Acceleration Service verwendet diese Konfigurationen dann intern Testinferenzen durchzuführen.
Im Moment können Sie mit dem Beschleunigungsdienst die GPU bewerten Konfigurationen (während der Ausführung in GPU-Delegate umgewandelt werden) mit dem GpuAccelerationConfig und CPU-Inferenz (mit CpuAccelerationConfig). Wir arbeiten daran, mehr Bevollmächtigten Zugriff auf andere Hardware in der in der Zukunft.
Konfiguration der GPU-Beschleunigung
Erstellen Sie so eine Konfiguration für die GPU-Beschleunigung:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Sie müssen angeben, ob Ihr Modell Quantisierung mit
setEnableQuantizedInference()
Konfiguration der CPU-Beschleunigung
Erstellen Sie die CPU-Beschleunigung so:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Verwenden Sie die Methode
setNumThreads()
Methode zum Definieren der Anzahl der Threads, die zum Auswerten der CPU verwendet werden sollen
Inferenz.
Validierungskonfigurationen erstellen
Mit Validierungskonfigurationen können Sie festlegen, wie die Beschleunigung Dienst zum Auswerten von Inferenzen. Sie verwenden sie, um Folgendes zu übergeben:
- Eingabestichproben,
- erwartete Ausgaben,
- Logik zur Validierung der Genauigkeit.
Stellen Sie unbedingt Eingabebeispiele bereit, für die Sie eine gute Leistung erwarten. Ihr Modell (auch als „goldene“ Beispiele bezeichnet).
Erstellen:
ValidationConfig
mit
CustomValidationConfig.Builder
wie folgt:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Geben Sie die Anzahl der goldenen Beispiele an mit
setBatchSize()
Übergeben Sie die Eingaben Ihrer goldenen Samples mit
setGoldenInputs()
Stellen Sie die erwartete Ausgabe für die mit übergebene Eingabe bereit
setGoldenOutputs()
Sie können eine maximale Inferenzzeit mit setInferenceTimeoutMillis() definieren
(standardmäßig 5.000 ms). Wenn die Inferenz länger dauert als
die von Ihnen definierte Zeit,
wird die Konfiguration abgelehnt.
Optional können Sie auch eine benutzerdefinierte AccuracyValidator erstellen.
wie folgt:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Definieren Sie eine Validierungslogik, die für Ihren Anwendungsfall funktioniert.
Wenn die Validierungsdaten bereits in Ihr Modell eingebettet sind, können Sie
EmbeddedValidationConfig
Validierungsausgaben generieren
Goldene Ausgaben sind optional. Solange Sie goldene Eingaben angeben,
Acceleration Service kann die goldenen Ausgaben intern generieren. Sie können auch
die Beschleunigungskonfiguration
zum Generieren dieser goldenen Ausgaben
setGoldenConfig() wird aufgerufen:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Beschleunigungskonfiguration validieren
Nachdem Sie eine Konfiguration für die Beschleunigung und eine Validierung erstellt haben, für Ihr Modell bewerten können.
Prüfen Sie, ob die Laufzeit von LiteRT mit Play-Diensten korrekt ist initialisiert wurde und der GPU-Delegate für das Gerät verfügbar ist. Führen Sie dazu folgenden Befehl aus:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
AccelerationService instanziieren
indem du AccelerationService.create() anrufst.
Anschließend können Sie die Konfiguration der Beschleunigung für Ihr Modell überprüfen, indem Sie folgenden Befehl aufrufen:
validateConfig():
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Sie können auch mehrere Konfigurationen validieren, indem Sie
validateConfigs()
und ein Iterable<AccelerationConfig>-Objekt als Parameter übergeben.
validateConfig()gibt Folgendes zurück:
Task<ValidatedAccelerationConfigResult>
über die Google Play-Dienste
Task-API, die Folgendes ermöglicht:
asynchrone Aufgaben.
Um das Ergebnis des Validierungsaufrufs zu erhalten, fügen Sie einen
addOnSuccessListener()
Callback des Nutzers an.
Validierte Konfiguration im Interpreter verwenden
Nachdem geprüft wurde, ob die ValidatedAccelerationConfigResult im
Callback gültig ist, können Sie die validierte Konfiguration als Beschleunigungskonfiguration festlegen.
für deinen Dolmetscher interpreterOptions.setAccelerationConfig().
Konfigurations-Caching
Die optimale Beschleunigungskonfiguration für Ihr Modell wird sich wahrscheinlich
auf dem Gerät. Sobald Sie eine
befriedigende Beschleunigungskonfiguration erhalten,
sollte es auf dem Gerät gespeichert werden.
erstellen Sie Ihre InterpreterOptions in den folgenden Sitzungen statt
eine weitere Validierung. Die Methoden serialize() und deserialize() in
ValidatedAccelerationConfigResult die Speicherung und den Abruf
einfacher zu machen.
Beispielanwendung
Informationen zur In-situ-Integration des Acceleration Service finden Sie in der Beispiel-App.
Beschränkungen
Für den Acceleration Service gelten derzeit die folgenden Einschränkungen:
- Derzeit werden nur Konfigurationen für die CPU- und GPU-Beschleunigung unterstützt.
- Es wird nur LiteRT in Google Play-Diensten unterstützt. wenn Sie die gebündelte Version von LiteRT nutzen.
- Acceleration Service SDK unterstützt nur API-Level 22 und höher.
Vorsichtsmaßnahmen
Lesen Sie die folgenden Hinweise sorgfältig durch, insbesondere wenn Sie um dieses SDK in der Produktion zu verwenden:
Vor dem Beenden der Betaversion und der Veröffentlichung der stabilen Version für die Acceleration Service API veröffentlichen wir ein neues SDK, im Vergleich zur aktuellen Betaversion. Damit Sie die müssen Sie zum neuen SDK migrieren zeitnah aktualisiert werden. Andernfalls kann es zu Ausfällen kommen, ist das Beta SDK nach der Umstellung möglicherweise nicht mehr mit den Google Play-Diensten kompatibel. etwas Zeit widmen.
Es gibt keine Garantie dafür, dass ein bestimmtes Feature innerhalb der Beschleunigung Die Service API oder die API insgesamt wird irgendwann allgemein verfügbar sein. Es kann auf unbestimmte Zeit in der Betaphase bleiben, eingestellt oder mit anderen zu Paketen zusammengefasst, die für bestimmte Entwicklerzielgruppen konzipiert sind. Einige mit der Acceleration Service API oder der gesamten API selbst allgemein verfügbar werden, aber es gibt keinen festen Zeitplan für dies.
Nutzungsbedingungen und Datenschutz
Nutzungsbedingungen
Die Nutzung der Acceleration Service APIs unterliegt den Nutzungsbedingungen für Google APIs
Dienst.
Die Acceleration Service APIs befinden sich derzeit in der Betaphase.
Wenn Sie es verwenden, erkennen Sie die potenziellen Probleme an, die in den
und bestätigen, dass der Acceleration Service
immer wie angegeben funktionieren.
Datenschutz
Wenn Sie die Acceleration Service APIs verwenden, wird die Verarbeitung der Eingabedaten (z.B.
Bilder, Videos, Texte) werden vollständig direkt auf dem Gerät übertragen. Der Acceleration Service
werden diese Daten nicht an Google-Server gesendet. Daher können Sie unsere APIs
zur Verarbeitung von Eingabedaten,
die das Gerät nicht verlassen dürfen.
Die Acceleration Service APIs können gelegentlich in
um Dinge wie Fehlerkorrekturen, aktualisierte Modelle und Hardwarebeschleuniger zu erhalten.
Informationen zur Kompatibilität. Die Acceleration Service APIs senden auch Messwerte zu
die Leistung und Nutzung der APIs in Ihrer App an Google zu senden. Google verwendet
um die Leistung zu messen, Fehler zu beheben, die APIs zu warten und zu verbessern,
und Missbrauch zu erkennen, wie in unserer Datenschutzerklärung
Richtlinien:
Du bist dafür verantwortlich, die Nutzer deiner App über die Verarbeitung durch Google zu informieren.
der Messwertdaten des Acceleration Service gemäß anwendbarem Recht.
Zu den von uns erhobenen Daten gehören:
- Geräteinformationen (z. B. Hersteller, Modell, Betriebssystemversion und Build) und verfügbaren ML-Hardwarebeschleunigern (GPU und DSP) Wird für Diagnosen und Nutzungsanalysen.
- App-Informationen (Paketname / Bundle-ID, App-Version). Verwendet für Diagnose- und Nutzungsanalysen.
- API-Konfiguration (z. B. Bildformat und -auflösung) Verwendet für Diagnose- und Nutzungsanalysen.
- Ereignistyp (z. B. „Initialisieren“, „Modell herunterladen“, „Aktualisieren“, „Ausführen“, „Erkennung“). Wird für Diagnosen und Nutzungsanalysen verwendet.
- Fehlercodes. Wird für Diagnosezwecke verwendet.
- Leistungsmesswerte Wird für Diagnosezwecke verwendet.
- Kennzeichnungen nach Installation, die Nutzer oder Nutzer nicht eindeutig identifizieren physisches Gerät Wird für den Betrieb der Remote-Konfiguration und -Nutzung verwendet Analytics.
- Absender-IP-Adressen der Netzwerkanfrage. Wird für die Remote-Konfiguration verwendet Diagnose. Erfasste IP-Adressen werden vorübergehend aufbewahrt.
Support und Feedback
Über den TensorFlow Issue Tracker können Sie Feedback geben und Unterstützung erhalten. Bitte melden Sie Probleme und Supportanfragen mithilfe der Problemvorlage für LiteRT in den Google Play-Diensten.