
Использование специализированных процессоров, таких как графические процессоры, NPU или DSP, для аппаратного ускорения может значительно улучшить производительность вывода (в некоторых случаях до 10 раз быстрее) и удобство использования вашего Android-приложения с поддержкой машинного обучения. Однако, учитывая разнообразие оборудования и драйверов, которые могут быть у ваших пользователей, выбор оптимальной конфигурации аппаратного ускорения для каждого устройства пользователя может оказаться сложной задачей. Более того, включение неправильной конфигурации на устройстве может ухудшить взаимодействие с пользователем из-за высокой задержки или, в некоторых редких случаях, ошибок во время выполнения или проблем с точностью, вызванных несовместимостью оборудования.
Служба ускорения для Android — это API, который помогает вам выбрать оптимальную конфигурацию аппаратного ускорения для данного пользовательского устройства и вашей модели .tflite , сводя при этом к минимуму риск ошибок во время выполнения или проблем с точностью.
Служба ускорения оценивает различные конфигурации ускорения на пользовательских устройствах, выполняя внутренние тесты вывода с вашей моделью LiteRT. Эти тестовые прогоны обычно выполняются за несколько секунд, в зависимости от вашей модели. Вы можете запустить тесты один раз на каждом пользовательском устройстве до времени вывода, кэшировать результат и использовать его во время вывода. Эти тесты выполняются вне процесса; что сводит к минимуму риск сбоев вашего приложения.
Предоставьте свою модель, образцы данных и ожидаемые результаты («золотые» входные и выходные данные), и служба ускорения запустит внутренний тест вывода TFLite, чтобы предоставить вам рекомендации по оборудованию.
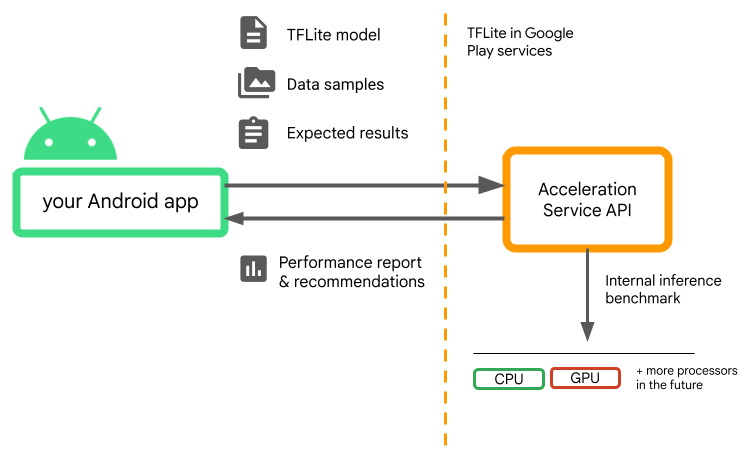
Служба ускорения является частью специального стека машинного обучения Android и работает с LiteRT в сервисах Google Play .
Добавьте зависимости в ваш проект
Добавьте следующие зависимости в файл build.gradle вашего приложения:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
API службы ускорения работает с LiteRT в сервисах Google Play . Если вы еще не используете среду выполнения LiteRT, предоставляемую через Play Services, вам необходимо обновить свои зависимости .
Как использовать API службы ускорения
Чтобы использовать службу ускорения, начните с создания конфигурации ускорения, которую вы хотите оценить для своей модели (например, графический процессор с OpenGL). Затем создайте конфигурацию проверки с вашей моделью, некоторыми примерами данных и ожидаемыми выходными данными модели. Наконец, вызовите validateConfig() , передав конфигурацию ускорения и конфигурацию проверки.

Создание конфигураций ускорения
Конфигурации ускорения — это представления конфигураций оборудования, которые преобразуются в делегаты во время выполнения. Служба ускорения затем будет использовать эти конфигурации внутри себя для выполнения тестовых выводов.
На данный момент служба ускорения позволяет вам оценивать конфигурации графического процессора (преобразованные в делегат графического процессора во время выполнения) с помощью GpuAccelerationConfig и вывода ЦП (с помощью CpuAccelerationConfig ). Мы работаем над тем, чтобы в будущем предоставить большему количеству делегатов доступ к другому оборудованию.
Конфигурация ускорения графического процессора
Создайте конфигурацию ускорения графического процессора следующим образом:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Вы должны указать, использует ли ваша модель квантование с помощью setEnableQuantizedInference() .
Конфигурация ускорения процессора
Создайте ускорение процессора следующим образом:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Используйте метод setNumThreads() , чтобы определить количество потоков, которые вы хотите использовать для оценки вывода ЦП.
Создание конфигураций проверки
Конфигурации проверки позволяют вам определить, как служба ускорения будет оценивать выводы. Вы будете использовать их для прохождения:
- входные образцы,
- ожидаемые результаты,
- логика проверки точности.
Обязательно предоставьте входные образцы, от которых вы ожидаете хорошей производительности вашей модели (также известные как «золотые» образцы).
Создайте ValidationConfig с помощью CustomValidationConfig.Builder следующим образом:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Укажите количество золотых образцов с помощью setBatchSize() . Передайте входные данные ваших золотых образцов с помощью setGoldenInputs() . Предоставьте ожидаемый результат для ввода, переданного с помощью setGoldenOutputs() .
Вы можете определить максимальное время вывода с помощью setInferenceTimeoutMillis() (по умолчанию 5000 мс). Если вывод занимает больше времени, чем вы определили, конфигурация будет отклонена.
При желании вы также можете создать собственный AccuracyValidator следующим образом:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Обязательно определите логику проверки, которая подходит для вашего варианта использования.
Обратите внимание: если данные проверки уже встроены в вашу модель, вы можете использовать EmbeddedValidationConfig .
Генерация результатов проверки
Золотые выходные данные не являются обязательными, и пока вы предоставляете золотые входные данные, Служба ускорения может генерировать золотые выходные данные самостоятельно. Вы также можете определить конфигурацию ускорения, используемую для генерации этих золотых результатов, вызвав setGoldenConfig() :
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Проверка конфигурации ускорения
После создания конфигурации ускорения и конфигурации проверки вы можете оценить их для своей модели.
Убедитесь, что среда выполнения LiteRT с Play Services правильно инициализирована и что делегат графического процессора доступен для устройства, выполнив:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Создайте AccelerationService , вызвав AccelerationService.create() .
Затем вы можете проверить конфигурацию ускорения для вашей модели, вызвав validateConfig() :
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Вы также можете проверить несколько конфигураций, вызвав validateConfigs() и передав объект Iterable<AccelerationConfig> в качестве параметра.
validateConfig() вернет Task< ValidatedAccelerationConfigResult > из Task API сервисов Google Play, который включает асинхронные задачи.
Чтобы получить результат вызова проверки, добавьте обратный вызов addOnSuccessListener() .
Используйте проверенную конфигурацию в вашем интерпретаторе
После проверки правильности ValidatedAccelerationConfigResult , возвращенного в обратном вызове, вы можете установить проверенную конфигурацию в качестве конфигурации ускорения для вашего интерпретатора, interpreterOptions.setAccelerationConfig() .
Кэширование конфигурации
Оптимальная конфигурация ускорения для вашей модели вряд ли изменится на устройстве. Поэтому, как только вы получите удовлетворительную конфигурацию ускорения, вам следует сохранить ее на устройстве и позволить приложению получить ее и использовать для создания InterpreterOptions во время следующих сеансов вместо запуска еще одной проверки. Методы serialize() и deserialize() в ValidatedAccelerationConfigResult упрощают процесс хранения и извлечения.
Образец заявления
Чтобы просмотреть интеграцию Службы ускорения на месте, ознакомьтесь с примером приложения .
Ограничения
На данный момент Служба ускорения имеет следующие ограничения:
- На данный момент поддерживаются только конфигурации ускорения CPU и GPU.
- Он поддерживает LiteRT только в сервисах Google Play, и вы не можете использовать его, если используете встроенную версию LiteRT.
- SDK службы ускорения поддерживает только уровень API 22 и выше.
Предостережения
Пожалуйста, внимательно ознакомьтесь со следующими предостережениями, особенно если вы планируете использовать этот SDK в рабочей среде:
Прежде чем выйти из бета-версии и выпустить стабильную версию API службы ускорения, мы опубликуем новый SDK, который может иметь некоторые отличия от текущей бета-версии. Чтобы продолжить использование службы ускорения, вам необходимо перейти на этот новый SDK и своевременно обновить свое приложение. Невыполнение этого требования может привести к сбоям, поскольку через некоторое время бета-версия SDK может стать несовместимой с сервисами Google Play.
Нет никакой гарантии, что конкретная функция API службы ускорения или API в целом когда-либо станет общедоступной. Он может оставаться в бета-версии на неопределенный срок, быть закрыт или объединен с другими функциями в пакеты, предназначенные для конкретной аудитории разработчиков. Некоторые функции API службы ускорения или весь API в конечном итоге могут стать общедоступными, но фиксированного графика для этого не существует.
Условия и конфиденциальность
Условия использования
Использование API-интерфейсов службы ускорения регулируется Условиями использования API Google .
Кроме того, API-интерфейсы службы ускорения в настоящее время находятся в стадии бета-тестирования, поэтому, используя их, вы признаете потенциальные проблемы, описанные в разделе «Предостережения» выше, и признаете, что служба ускорения не всегда может работать так, как указано.
Конфиденциальность
Когда вы используете API-интерфейсы службы ускорения, обработка входных данных (например, изображений, видео, текста) полностью происходит на устройстве, и служба ускорения не отправляет эти данные на серверы Google . В результате вы можете использовать наши API для обработки входных данных, которые не должны покидать устройство.
API-интерфейсы службы ускорения могут время от времени связываться с серверами Google, чтобы получать такие сведения, как исправления ошибок, обновленные модели и информацию о совместимости аппаратных ускорителей. API-интерфейсы службы ускорения также отправляют в Google показатели производительности и использования API-интерфейсов вашего приложения. Google использует эти метрические данные для измерения производительности, отладки, обслуживания и улучшения API, а также для выявления неправильного использования или злоупотреблений, как далее описано в нашей Политике конфиденциальности .
Вы несете ответственность за информирование пользователей вашего приложения об обработке Google данных показателей Службы ускорения в соответствии с требованиями применимого законодательства.
Данные, которые мы собираем, включают следующее:
- Информация об устройстве (например, производитель, модель, версия и сборка ОС) и доступных аппаратных ускорителях машинного обучения (GPU и DSP). Используется для диагностики и анализа использования.
- Информация о приложении (название пакета/идентификатор пакета, версия приложения). Используется для диагностики и анализа использования.
- Конфигурация API (например, формат и разрешение изображения). Используется для диагностики и анализа использования.
- Тип события (например, инициализация, модель загрузки, обновление, запуск, обнаружение). Используется для диагностики и анализа использования.
- Коды ошибок. Используется для диагностики.
- Показатели производительности. Используется для диагностики.
- Идентификаторы каждой установки, которые не идентифицируют однозначно пользователя или физическое устройство. Используется для удаленной настройки и анализа использования.
- IP-адреса отправителя сетевых запросов. Используется для удаленной диагностики конфигурации. Собранные IP-адреса сохраняются временно.
Поддержка и обратная связь
Вы можете оставить отзыв и получить поддержку через систему отслеживания проблем TensorFlow. Сообщайте о проблемах и отправляйте запросы в службу поддержки, используя шаблон проблемы для LiteRT в сервисах Google Play.