
Na tej stronie znajdziesz wskazówki dotyczące tworzenia modeli TensorFlow z myślą o przekształceniu ich w format modelu LiteRT. Modele uczenia maszynowego, których używasz w LiteRT, są pierwotnie tworzone i trenowane przy użyciu podstawowych bibliotek i narzędzi TensorFlow. Po utworzeniu modelu za pomocą TensorFlow Core możesz przekonwertować go na mniejszy i wydajniejszy format modelu ML o nazwie LiteRT.
Jeśli masz już model do przekonwertowania, zapoznaj się ze stroną Przekształcanie modeli, aby dowiedzieć się, jak to zrobić.
Tworzenie modelu
Jeśli tworzysz model niestandardowy do konkretnego przypadku użycia, zacznij od opracowania i wytrenowania modelu TensorFlow lub rozszerzenia istniejącego modelu.
Ograniczenia dotyczące projektu modelu
Zanim rozpoczniesz proces tworzenia modelu, zapoznaj się z ograniczeniami modeli LiteRT i twórz model z uwzględnieniem tych ograniczeń:
- Ograniczone możliwości obliczeniowe – w porównaniu z w pełni wyposażonymi serwerami z wieloma procesorami, dużą pojemnością pamięci i specjalistycznymi procesorami, takimi jak GPU i TPU, urządzenia mobilne i urządzenia brzegowe mają znacznie mniejsze możliwości. Chociaż ich moc obliczeniowa i kompatybilność ze specjalistycznym sprzętem rosną, modele i dane, które można za ich pomocą skutecznie przetwarzać, są nadal stosunkowo ograniczone.
- Rozmiar modeli – ogólna złożoność modelu, w tym logika wstępnego przetwarzania danych i liczba warstw w modelu, zwiększa rozmiar modelu w pamięci. Duży model może działać zbyt wolno lub po prostu nie mieścić się w pamięci urządzenia mobilnego lub brzegowego.
- Rozmiar danych – rozmiar danych wejściowych, które można skutecznie przetworzyć za pomocą modelu uczenia maszynowego, jest ograniczony na urządzeniu mobilnym lub brzegowym. Modele, które korzystają z dużych bibliotek danych, takich jak biblioteki językowe, biblioteki obrazów lub biblioteki klipów wideo, mogą nie zmieścić się na tych urządzeniach i mogą wymagać rozwiązań do przechowywania i uzyskiwania dostępu do danych poza urządzeniem.
- Obsługiwane operacje TensorFlow – środowiska wykonawcze LiteRT obsługują podzbiór operacji modelu uczenia maszynowego w porównaniu ze zwykłymi modelami TensorFlow. Podczas tworzenia modelu do użytku z LiteRT należy śledzić jego zgodność z możliwościami środowisk wykonawczych LiteRT.
Więcej informacji o tworzeniu skutecznych, kompatybilnych i wydajnych modeli na potrzeby LiteRT znajdziesz w artykule Sprawdzone metody dotyczące wydajności.
Opracowywanie modeli
Aby utworzyć model LiteRT, musisz najpierw utworzyć model za pomocą bibliotek podstawowych TensorFlow. Podstawowe biblioteki TensorFlow to biblioteki niższego poziomu, które udostępniają interfejsy API do tworzenia, trenowania i wdrażania modeli ML.
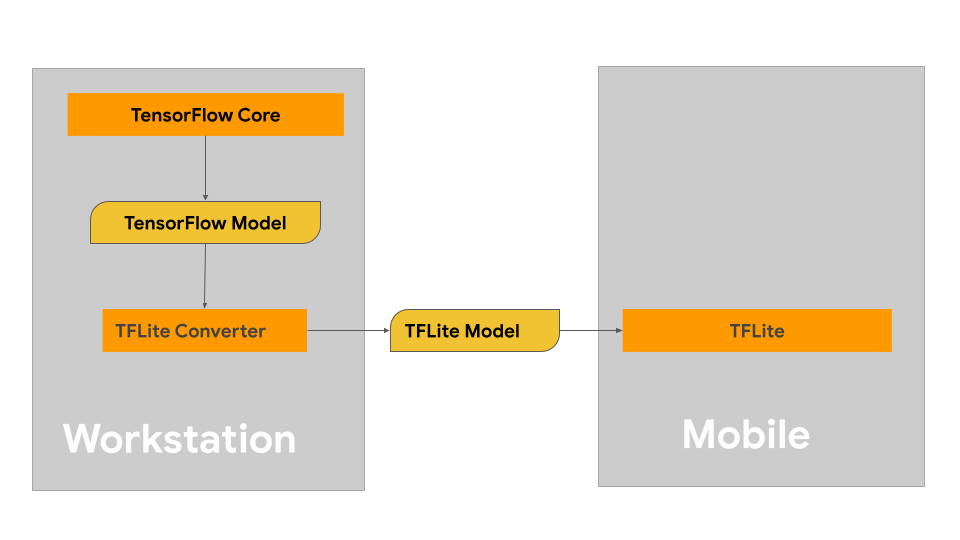
TensorFlow udostępnia 2 sposoby na to, jak to zrobić. Możesz opracować własny kod modelu niestandardowego lub zacząć od implementacji modelu dostępnej w Model Garden TensorFlow.
Baza modeli
Baza modeli TensorFlow zawiera implementacje wielu najnowocześniejszych modeli uczenia maszynowego do przetwarzania obrazów i języka naturalnego. Znajdziesz też narzędzia do przepływu pracy, które pozwolą Ci szybko konfigurować i uruchamiać te modele na standardowych zbiorach danych. Modele systemów uczących się w Model Garden zawierają pełny kod, dzięki czemu możesz je testować, trenować lub ponownie trenować przy użyciu własnych zbiorów danych.
Niezależnie od tego, czy chcesz porównać skuteczność znanego modelu, zweryfikować wyniki niedawno opublikowanych badań czy rozszerzyć istniejące modele, Model Garden pomoże Ci osiągnąć cele związane z uczeniem maszynowym.
Modele niestandardowe
Jeśli Twój przypadek użycia nie jest obsługiwany przez modele w Model Garden, możesz użyć biblioteki wysokiego poziomu, takiej jak Keras, aby opracować niestandardowy kod trenowania. Aby poznać podstawy TensorFlow, zapoznaj się z przewodnikiem po TensorFlow. Aby rozpocząć pracę z przykładami, zapoznaj się z omówieniem samouczków TensorFlow, które zawierają wskazówki dotyczące samouczków na poziomie od początkującego do zaawansowanego.
Ocena modelu
Po opracowaniu modelu należy ocenić jego wydajność i przetestować go na urządzeniach użytkowników. TensorFlow udostępnia kilka sposobów na to, jak to zrobić.
- TensorBoard to narzędzie do dostarczania pomiarów i wizualizacji potrzebnych w procesie uczenia maszynowego. Umożliwia śledzenie wskaźników eksperymentu, takich jak utrata i dokładność, wizualizację wykresu modelu, rzutowanie osadzeń na przestrzeń o mniejszej liczbie wymiarów i wiele innych.
- Narzędzia do testów porównawczych są dostępne na każdej obsługiwanej platformie, np. aplikacja do testów porównawczych na Androida i aplikacja do testów porównawczych na iOS. Używaj tych narzędzi do pomiaru i obliczania statystyk ważnych danych o skuteczności.
Optymalizacja modelu
Ze względu na ograniczenia dotyczące zasobów specyficznych dla modeli TensorFlow Lite optymalizacja modelu może pomóc w zapewnieniu jego dobrej wydajności i mniejszego zużycia zasobów obliczeniowych. Wydajność modelu uczenia maszynowego jest zwykle kompromisem między rozmiarem i szybkością wnioskowania a dokładnością. LiteRT obecnie obsługuje optymalizację za pomocą kwantyzacji, przycinania i klastrowania. Więcej informacji o tych technikach znajdziesz w artykule Optymalizacja modelu. TensorFlow udostępnia też zestaw narzędzi do optymalizacji modeli, który zawiera interfejs API implementujący te techniki.
Dalsze kroki
- Aby rozpocząć tworzenie własnego modelu, zapoznaj się z samouczkiem dla początkujących w dokumentacji podstawowej TensorFlow.
- Aby przekonwertować niestandardowy model TensorFlow, zapoznaj się z omówieniem konwertowania modeli.
- Zapoznaj się z przewodnikiem zgodności z operatorami, aby sprawdzić, czy Twój model jest zgodny z LiteRT, czy musisz wykonać dodatkowe czynności, aby go z nim połączyć.
- W przewodniku po sprawdzonych metodach dotyczących wydajności znajdziesz wskazówki, jak zwiększyć wydajność modeli LiteRT.
- W przewodniku po danych o skuteczności znajdziesz informacje o tym, jak mierzyć skuteczność modelu za pomocą narzędzi do testów porównawczych.