
Przegląd
Na tej stronie opisujemy projekt i kroki potrzebne do przekształcenia operacji złożonych w TensorFlow na operacje scalone w LiteRT. Ta infrastruktura jest ogólnego przeznaczenia i umożliwia przekształcanie dowolnej operacji złożonej w TensorFlow w odpowiednią operację scaloną w LiteRT.
Przykładem wykorzystania tej infrastruktury jest łączenie operacji RNN TensorFlow z LiteRT, co zostało szczegółowo opisane tutaj.
Czym są połączone operacje?

Operacje TensorFlow mogą być operacjami pierwotnymi, np. tf.add, lub mogą być złożone z innych operacji pierwotnych, np. tf.einsum. Operacja podstawowa jest wyświetlana jako pojedynczy węzeł na wykresie TensorFlow, a operacja złożona to zbiór węzłów na wykresie TensorFlow. Wykonanie operacji złożonej jest równoznaczne z wykonaniem każdej z jej składowych operacji podstawowych.
Operacja scalona odpowiada pojedynczej operacji, która obejmuje wszystkie obliczenia wykonywane przez każdą operację podstawową w odpowiedniej operacji złożonej.
Zalety połączonych operacji
Operacje scalone mają na celu zmaksymalizowanie wydajności implementacji bazowego jądra przez optymalizację ogólnych obliczeń i zmniejszenie śladu pamięci. Jest to bardzo przydatne, zwłaszcza w przypadku zadań wnioskowania z niskimi opóźnieniami i platform mobilnych o ograniczonych zasobach.
Operacje scalone zapewniają też interfejs wyższego poziomu do definiowania złożonych przekształceń, takich jak kwantyzacja, które w przeciwnym razie byłyby niewykonalne lub bardzo trudne do wykonania na bardziej szczegółowym poziomie.
LiteRT ma wiele przypadków połączonych operacji z powodów opisanych powyżej. Te połączone operacje zwykle odpowiadają operacjom złożonym w źródłowym programie TensorFlow. Przykłady operacji złożonych w TensorFlow, które są implementowane jako pojedyncza scalona operacja w LiteRT, obejmują różne operacje RNN, takie jak jednokierunkowe i dwukierunkowe sekwencje LSTM, konwolucje (conv2d, dodawanie wartości progowej, relu), w pełni połączone (matmul, dodawanie wartości progowej, relu) i inne. W LiteRT kwantyzacja LSTM jest obecnie zaimplementowana tylko w przypadku połączonych operacji LSTM.
Problemy z operacjami scalonymi
Konwertowanie operacji złożonych z TensorFlow na operacje scalone w LiteRT jest trudnym zadaniem. Dzieje się tak, ponieważ:
Operacje złożone są reprezentowane w grafie TensorFlow jako zestaw operacji pierwotnych bez dobrze zdefiniowanej granicy. Zidentyfikowanie podgrafu odpowiadającego takiej operacji złożonej (np. za pomocą dopasowywania wzorców) może być bardzo trudne.
Może istnieć więcej niż jedna implementacja TensorFlow kierowana na połączoną operację LiteRT. Na przykład w TensorFlow jest wiele implementacji LSTM (Keras, Babelfish/lingvo itp.), a każda z nich składa się z różnych operacji podstawowych, ale wszystkie można przekształcić w tę samą połączoną operację LSTM w LiteRT.
Z tego powodu konwersja połączonych operacji okazała się dość trudna.
Przekształcanie operacji złożonej w niestandardową operację TFLite (zalecane)
Umieść operację złożoną w tagu tf.function.
W wielu przypadkach część modelu można przypisać do jednej operacji w TFLite. Może to pomóc w zwiększeniu wydajności podczas pisania zoptymalizowanej implementacji dla określonych operacji. Aby utworzyć w TFLite operację połączoną, zidentyfikuj część wykresu, która reprezentuje operację połączoną, i zawiń ją w funkcję tf.function z atrybutem „experimental_implements” do tf.function, który ma wartość atrybutu tfl_fusable_op z wartością true. Jeśli operacja niestandardowa przyjmuje atrybuty, przekaż je w ramach tego samego parametru „experimental_implements”.
Przykład:
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
Pamiętaj, że nie musisz ustawiać atrybutu allow_custom_ops na konwerterze, ponieważ atrybut tfl_fusable_op już to oznacza.
Implementowanie niestandardowego operatora i rejestrowanie go w interpreterze TFLite
Zaimplementuj połączoną operację jako niestandardową operację TFLite – zobacz instrukcje.
Pamiętaj, że nazwa, pod którą rejestrujesz operację, powinna być podobna do nazwy podanej w atrybucie name w sygnaturze implements.
Przykładem operacji w tym przykładzie jest
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
Przekształcanie operacji złożonej w operację scaloną (zaawansowane)
Ogólna architektura konwertowania złożonych operacji TensorFlow na połączone operacje LiteRT jest przedstawiona poniżej:
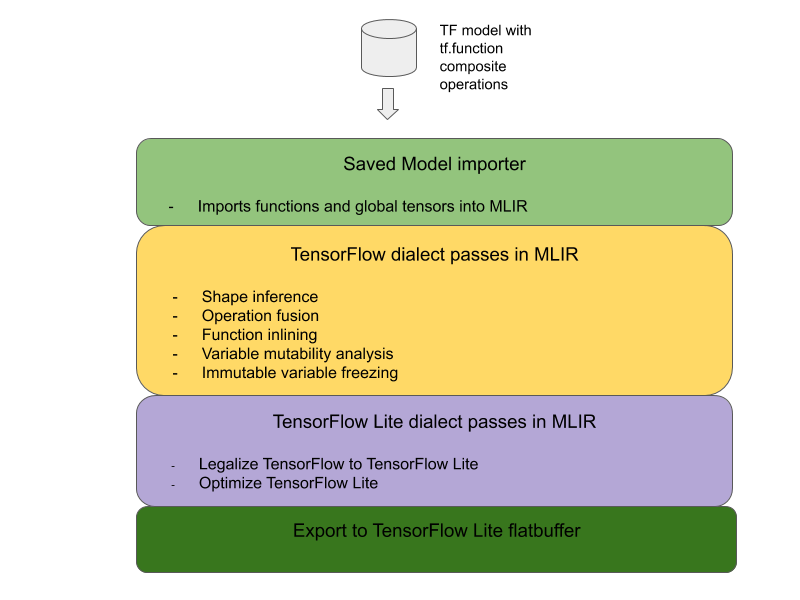
Umieść operację złożoną w tagu tf.function.
W kodzie źródłowym modelu TensorFlow zidentyfikuj i wyodrębnij operację złożoną do funkcji tf.function z adnotacją funkcji experimental_implements. Zobacz przykład wyszukiwania wektorów. Funkcja definiuje interfejs, a jej argumenty powinny być używane do implementowania logiki konwersji.
Pisanie kodu konwersji
Kod konwersji jest zapisywany zgodnie z interfejsem funkcji z adnotacją implements. Zobacz przykładowe połączenie w przypadku wyszukiwania wektora. Koncepcyjnie kod konwersji zastępuje złożoną implementację tego interfejsu implementacją scaloną.
W fazie prepare-composite-functions wstaw kod konwersji.
W bardziej zaawansowanych zastosowaniach można wdrażać złożone przekształcenia operandów operacji złożonej, aby uzyskać operandy operacji scalonej. Przykładem może być kod konwersji Keras LSTM.
Konwertowanie na LiteRT
Użyj interfejsu TFLiteConverter.from_saved_model API, aby przekonwertować model na LiteRT.
Dla zaawansowanych
Opisujemy teraz ogólne szczegóły projektu konwersji na połączone operacje w LiteRT.
Komponowanie operacji w TensorFlow
Użycie funkcji tf.function z atrybutem funkcji experimental_implements umożliwia użytkownikom jawne tworzenie nowych operacji za pomocą podstawowych operacji TensorFlow i określanie interfejsu, który implementuje wynikowa operacja złożona. Jest to bardzo przydatne, ponieważ zapewnia:
- Dobrze zdefiniowana granica operacji złożonej w bazowym grafie TensorFlow.
- Wyraźnie określ interfejs, który implementuje ta operacja. Argumenty funkcji tf.function odpowiadają argumentom tego interfejsu.
Rozważmy na przykład operację złożoną zdefiniowaną w celu wdrożenia wyszukiwania wektorów. Odpowiada to połączonej operacji w LiteRT.
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
Dzięki temu, że modele korzystają z operacji złożonych za pomocą funkcji tf.function, jak pokazano powyżej, można zbudować ogólną infrastrukturę do identyfikowania i przekształcania takich operacji w połączone operacje LiteRT.
Rozszerzanie konwertera LiteRT
Wydany w tym roku konwerter LiteRT obsługiwał tylko importowanie modeli TensorFlow jako wykresu, w którym wszystkie zmienne były zastępowane odpowiednimi wartościami stałymi. Nie działa to w przypadku łączenia operacji, ponieważ takie wykresy mają wszystkie funkcje wstawione w kodzie, dzięki czemu zmienne można przekształcić w stałe.
Aby podczas procesu konwersji korzystać z funkcji tf.function z funkcją experimental_implements, funkcje muszą być zachowane do późniejszego etapu procesu konwersji.
Wdrożyliśmy nowy proces importowania i konwertowania modeli TensorFlow w konwerterze, aby obsługiwać przypadek użycia fuzji operacji złożonych. Nowe funkcje to:
- Importowanie zapisanych modeli TensorFlow do MLIR
- łączyć operacje złożone
- analiza zmienności zmiennych,
- zamrozić wszystkie zmienne tylko do odczytu
Umożliwia to łączenie operacji za pomocą funkcji reprezentujących operacje złożone przed wstawieniem funkcji i zamrożeniem zmiennych.
Implementowanie łączenia operacji
Przyjrzyjmy się bliżej operacji łączenia. Ta karta wykonuje te czynności:
- Przejdź przez wszystkie funkcje w module MLIR.
- Jeśli funkcja ma atrybut tf._implements, na podstawie wartości atrybutu wywołuje odpowiednie narzędzie do łączenia operacji.
- Narzędzie do łączenia operacji działa na operandach i atrybutach funkcji (które służą jako interfejs konwersji) i zastępuje treść funkcji równoważną treścią funkcji zawierającą połączoną operację.
- W wielu przypadkach zastąpiony blok będzie zawierać operacje inne niż operacja scalona. Odpowiadają one niektórym statycznym przekształceniom operandów funkcji, które pozwalają uzyskać operandy połączonej operacji. Ponieważ wszystkie te obliczenia można złożyć w stałe, nie będą one obecne w wyeksportowanym buforze płaskim, w którym będzie istniała tylko połączona operacja.
Oto fragment kodu z karty pokazujący główny przepływ pracy:
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
Oto fragment kodu pokazujący mapowanie tej operacji złożonej na operację scaloną w LiteRT z wykorzystaniem funkcji jako interfejsu konwersji.
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}