
Operatorët e të mësuarit automatik (ML) që përdorni në modelin tuaj mund të ndikojnë në procesin e konvertimit të një modeli TensorFlow në formatin LiteRT. Konvertuesi LiteRT mbështet një numër të kufizuar operacionesh TensorFlow të përdorura në modelet e zakonshme të inferencës, që do të thotë se jo çdo model është i konvertueshëm drejtpërdrejt. Mjeti i konvertuesit ju lejon të përfshini operatorë shtesë, por konvertimi i një modeli në këtë mënyrë kërkon gjithashtu që ju të modifikoni mjedisin e ekzekutimit LiteRT që përdorni për të ekzekutuar modelin tuaj, gjë që mund të kufizojë aftësinë tuaj për të përdorur opsionet standarde të vendosjes në kohën e ekzekutimit, të tilla si shërbimet Google Play .
Konvertuesi LiteRT është projektuar për të analizuar strukturën e modelit dhe për të aplikuar optimizime në mënyrë që ta bëjë atë të pajtueshëm me operatorët e mbështetur drejtpërdrejt. Për shembull, në varësi të operatorëve ML në modelin tuaj, konvertuesi mund t'i shmangë ose t'i bashkojë këta operatorë në mënyrë që t'i hartëzojë ata me homologët e tyre LiteRT.
Edhe për operacionet e mbështetura, ndonjëherë priten modele specifike përdorimi, për arsye të performancës. Mënyra më e mirë për të kuptuar se si të ndërtohet një model TensorFlow që mund të përdoret me LiteRT është të shqyrtohet me kujdes se si konvertohen dhe optimizohen operacionet, së bashku me kufizimet e imponuara nga ky proces.
Operatorët e mbështetur
Operatorët e integruar të LiteRT janë një nëngrup i operatorëve që janë pjesë e bibliotekës kryesore të TensorFlow. Modeli juaj TensorFlow mund të përfshijë gjithashtu operatorë të personalizuar në formën e operatorëve të përbërë ose operatorëve të rinj të përcaktuar nga ju. Diagrama më poshtë tregon marrëdhëniet midis këtyre operatorëve.
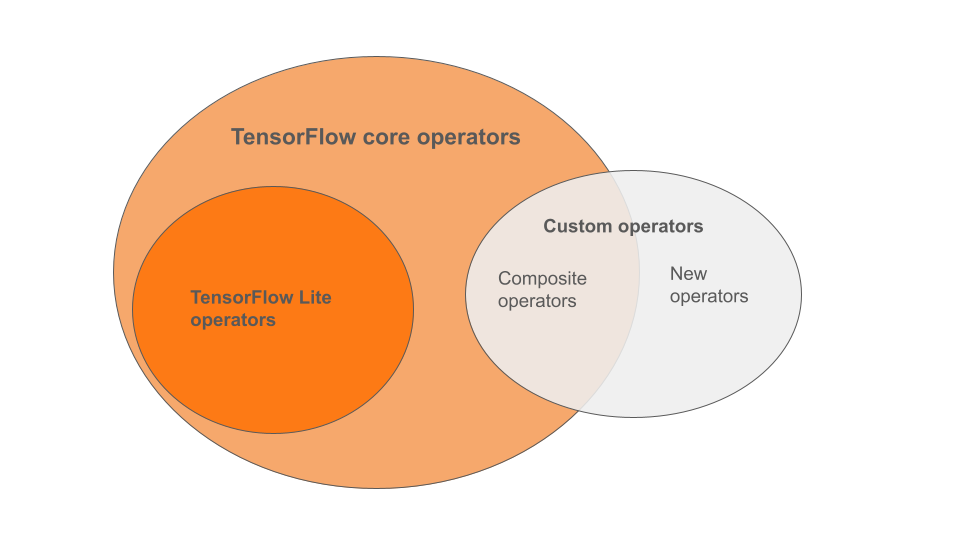
Nga kjo gamë e operatorëve të modelit ML, ekzistojnë 3 lloje modelesh të mbështetura nga procesi i konvertimit:
- Modele vetëm me operator të integruar LiteRT. ( I rekomanduar )
- Modele me operatorët e integruar dhe operatorë të zgjedhur bazë të TensorFlow.
- Modele me operatorët e integruar, operatorët bazë të TensorFlow dhe/ose operatorët e personalizuar.
Nëse modeli juaj përmban vetëm operacione që mbështeten në mënyrë native nga LiteRT, nuk keni nevojë për flamuj shtesë për ta konvertuar atë. Kjo është rruga e rekomanduar sepse ky lloj modeli do të konvertohet pa probleme dhe është më i thjeshtë për t'u optimizuar dhe ekzekutuar duke përdorur kohën e parazgjedhur të ekzekutimit të LiteRT. Gjithashtu keni më shumë opsione vendosjeje për modelin tuaj, siç janë shërbimet e Google Play . Mund të filloni me udhëzuesin e konvertuesit LiteRT . Shihni faqen e Operacioneve LiteRT për një listë të operatorëve të integruar.
Nëse duhet të përfshish operacionet e zgjedhura të TensorFlow nga biblioteka kryesore, duhet ta specifikosh këtë gjatë konvertimit dhe të sigurohesh që koha e ekzekutimit i përfshin ato operacione. Shih temën "Zgjidh operatorët e TensorFlow" për hapa të detajuar.
Sa herë që është e mundur, shmangni opsionin e fundit të përfshirjes së operatorëve të personalizuar në modelin tuaj të konvertuar. Operatorët e personalizuar janë ose operatorë të krijuar duke kombinuar shumë operatorë primitivë bazë TensorFlow ose duke përcaktuar një operator krejtësisht të ri. Kur operatorët e personalizuar konvertohen, ata mund të rrisin madhësinë e modelit të përgjithshëm duke shkaktuar varësi jashtë bibliotekës së integruar LiteRT. Operacionet e personalizuara, nëse nuk janë krijuar posaçërisht për vendosjen në celular ose në pajisje, mund të rezultojnë në performancë më të keqe kur vendosen në pajisje me burime të kufizuara krahasuar me një mjedis serveri. Së fundmi, ashtu si përfshirja e operatorëve të zgjedhur bazë TensorFlow, operatorët e personalizuar kërkojnë që ju të modifikoni mjedisin e ekzekutimit të modelit, gjë që ju kufizon nga shfrytëzimi i shërbimeve standarde të ekzekutimit, siç janë shërbimet Google Play .
Llojet e mbështetura
Shumica e operacioneve LiteRT synojnë si inferencën me pikë lundruese ( float32 ) ashtu edhe atë të kuantizuar ( uint8 , int8 ), por shumë operacione nuk e bëjnë këtë ende për lloje të tjera si tf.float16 dhe vargje.
Përveç përdorimit të versioneve të ndryshme të operacioneve, ndryshimi tjetër midis modeleve me pikë lundruese dhe atyre të kuantizuara është mënyra se si ato konvertohen. Konvertimi i kuantizuar kërkon informacion mbi diapazonin dinamik për tenzorët. Kjo kërkon "kuantizim të rremë" gjatë trajnimit të modelit, marrjen e informacionit mbi diapazonin nëpërmjet një grupi të dhënash kalibrimi ose kryerjen e një vlerësimi të menjëhershëm të diapazonit. Shih kuantizimin për më shumë detaje.
Konvertime të drejtpërdrejta, palosje dhe bashkim i vazhdueshëm
Një numër operacionesh TensorFlow mund të përpunohen nga LiteRT edhe pse nuk kanë ekuivalent të drejtpërdrejtë. Ky është rasti për operacionet që mund të hiqen thjesht nga grafiku ( tf.identity ), të zëvendësohen nga tenzorët ( tf.placeholder ) ose të bashkohen në operacione më komplekse ( tf.nn.bias_add ). Edhe disa operacione të mbështetura ndonjëherë mund të hiqen përmes njërit prej këtyre proceseve.
Ja një listë jo e plotë e operacioneve të TensorFlow që zakonisht hiqen nga grafiku:
-
tf.add -
tf.debugging.check_numerics -
tf.constant -
tf.div -
tf.divide -
tf.fake_quant_with_min_max_args -
tf.fake_quant_with_min_max_vars -
tf.identity -
tf.maximum -
tf.minimum -
tf.multiply -
tf.no_op -
tf.placeholder -
tf.placeholder_with_default -
tf.realdiv -
tf.reduce_max -
tf.reduce_min -
tf.reduce_sum -
tf.rsqrt -
tf.shape -
tf.sqrt -
tf.square -
tf.subtract -
tf.tile -
tf.nn.batch_norm_with_global_normalization -
tf.nn.bias_add -
tf.nn.fused_batch_norm -
tf.nn.relu -
tf.nn.relu6
Operacione Eksperimentale
Operacionet e mëposhtme LiteRT janë të pranishme, por jo gati për modelet e personalizuara:
-
CALL -
CONCAT_EMBEDDINGS -
CUSTOM -
EMBEDDING_LOOKUP_SPARSE -
HASHTABLE_LOOKUP -
LSH_PROJECTION -
SKIP_GRAM -
SVDF