
Pajisjet Edge shpesh kanë memorie ose fuqi llogaritëse të kufizuar. Optimizime të ndryshme mund të aplikohen në modele në mënyrë që ato të mund të funksionojnë brenda këtyre kufizimeve. Përveç kësaj, disa optimizime lejojnë përdorimin e pajisjeve të specializuara për nxjerrje të përshpejtuar të konkluzioneve.
LiteRT dhe TensorFlow Model Optimization Toolkit ofrojnë mjete për të minimizuar kompleksitetin e optimizimit të inferencës.
Rekomandohet që të merrni në konsideratë optimizimin e modelit gjatë procesit të zhvillimit të aplikacionit tuaj. Ky dokument përshkruan disa praktika më të mira për optimizimin e modeleve TensorFlow për vendosje në harduerin e skajeve.
Pse modelet duhet të optimizohen
Ekzistojnë disa mënyra kryesore se si optimizimi i modelit mund të ndihmojë në zhvillimin e aplikacioneve.
Zvogëlimi i madhësisë
Disa forma optimizimi mund të përdoren për të zvogëluar madhësinë e një modeli. Modelet më të vogla kanë përfitimet e mëposhtme:
- Madhësi më e vogël e ruajtjes: Modelet më të vogla zënë më pak hapësirë ruajtjeje në pajisjet e përdoruesve tuaj. Për shembull, një aplikacion Android që përdor një model më të vogël do të zërë më pak hapësirë ruajtjeje në pajisjen mobile të një përdoruesi.
- Madhësi më e vogël shkarkimi: Modelet më të vogla kërkojnë më pak kohë dhe bandwidth për t'u shkarkuar në pajisjet e përdoruesve.
- Më pak përdorim memorieje: Modelet më të vogla përdorin më pak RAM kur ekzekutohen, gjë që liron memorie për pjesë të tjera të aplikacionit tuaj dhe mund të përkthehet në performancë dhe stabilitet më të mirë.
Kuantizimi mund të zvogëlojë madhësinë e një modeli në të gjitha këto raste, potencialisht në kurriz të njëfarë saktësie. Shkurtimi dhe grupimi mund të zvogëlojnë madhësinë e një modeli për shkarkim duke e bërë atë më të lehtë për t'u kompresuar.
Reduktimi i latencës
Vonesa është sasia e kohës që duhet për të ekzekutuar një përfundim të vetëm me një model të caktuar. Disa forma të optimizimit mund të zvogëlojnë sasinë e llogaritjeve të nevojshme për të ekzekutuar përfundimin duke përdorur një model, duke rezultuar në një vonesë më të ulët. Vonesa gjithashtu mund të ketë ndikim në konsumin e energjisë.
Aktualisht, kuantizimi mund të përdoret për të zvogëluar latencën duke thjeshtuar llogaritjet që ndodhin gjatë nxjerrjes së përfundimeve, potencialisht në kurriz të njëfarë saktësie.
Pajtueshmëria e përshpejtuesit
Disa përshpejtues harduerësh, siç është Edge TPU , mund të ekzekutojnë inferencën jashtëzakonisht shpejt me modele që janë optimizuar saktë.
Në përgjithësi, këto lloje pajisjesh kërkojnë që modelet të kuantizohen në një mënyrë specifike. Shihni dokumentacionin e secilit përshpejtues hardueri për të mësuar më shumë rreth kërkesave të tyre.
Kompromise
Optimizimet mund të rezultojnë në ndryshime në saktësinë e modelit, të cilat duhet të merren në konsideratë gjatë procesit të zhvillimit të aplikacionit.
Ndryshimet e saktësisë varen nga modeli individual që po optimizohet dhe janë të vështira për t'u parashikuar paraprakisht. Në përgjithësi, modelet që janë optimizuar për madhësinë ose vonesën do të humbasin një sasi të vogël saktësie. Në varësi të aplikacionit tuaj, kjo mund të ndikojë ose jo në përvojën e përdoruesve tuaj. Në raste të rralla, modele të caktuara mund të fitojnë njëfarë saktësie si rezultat i procesit të optimizimit.
Llojet e optimizimit
LiteRT aktualisht mbështet optimizimin nëpërmjet kuantizimit, shkurtimit dhe grupimit.
Këto janë pjesë e TensorFlow Model Optimization Toolkit , i cili ofron burime për teknikat e optimizimit të modelit që janë të pajtueshme me TensorFlow Lite.
Kuantizimi
Kuantizimi funksionon duke zvogëluar saktësinë e numrave të përdorur për të përfaqësuar parametrat e një modeli, të cilët si parazgjedhje janë numra me pikë lundruese 32-bit. Kjo rezulton në një madhësi më të vogël të modelit dhe llogaritje më të shpejtë.
Llojet e mëposhtme të kuantizimit janë të disponueshme në LiteRT:
| Teknikë | Kërkesat për të dhëna | Zvogëlimi i madhësisë | Saktësia | Pajisjet e mbështetura |
|---|---|---|---|---|
| Kuantizimi float16 pas trajnimit | Pa të dhëna | Deri në 50% | Humbje e parëndësishme e saktësisë | CPU, GPU |
| Kuantizimi i diapazonit dinamik pas trajnimit | Pa të dhëna | Deri në 75% | Humbja më e vogël e saktësisë | CPU, GPU (Android) |
| Kuantizimi i numrave të plotë pas trajnimit | Mostër përfaqësuese e paetiketuar | Deri në 75% | Humbje e vogël e saktësisë | CPU, GPU (Android), EdgeTPU |
| Trajnim i vetëdijshëm për kuantizimin | Të dhëna të etiketuara të trajnimit | Deri në 75% | Humbja më e vogël e saktësisë | CPU, GPU (Android), EdgeTPU |
Pema e mëposhtme e vendimeve ju ndihmon të zgjidhni skemat e kuantizimit që mund të dëshironi të përdorni për modelin tuaj, thjesht bazuar në madhësinë dhe saktësinë e pritur të modelit.
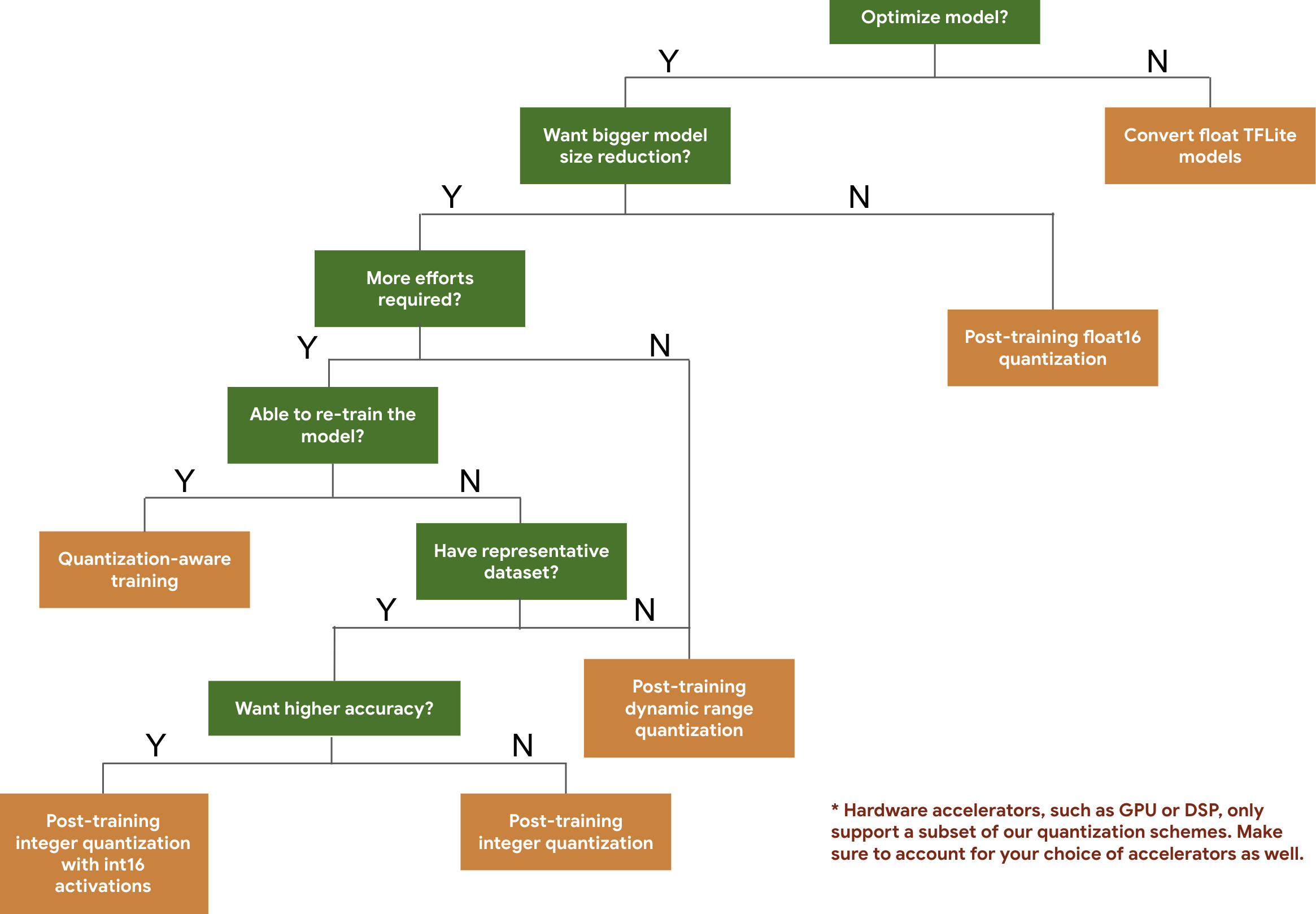
Më poshtë janë rezultatet e latencës dhe saktësisë për kuantizimin pas trajnimit dhe trajnimin e vetëdijshëm për kuantizimin në disa modele. Të gjithë numrat e latencës maten në pajisjet Pixel 2 duke përdorur një CPU të vetme me bërthamë të madhe. Ndërsa përmirësohet paketa e mjeteve, do të përmirësohen edhe numrat këtu:
| Model | Saktësia më e mirë 1 (Origjinale) | Saktësia më e mirë (e kuantizuar pas trajnimit) | Saktësia më e mirë (Trajnim i Ndërgjegjshëm për Kuantizimin) | Vonesa (Origjinale) (ms) | Latencia (e kuantizuar pas trajnimit) (ms) | Latencia (Trajnim i Ndërgjegjshëm për Kuantizimin) (ms) | Madhësia (Origjinale) (MB) | Madhësia (Optimizuar) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Fillimi_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
Kuantizim i plotë i numrave të plotë me aktivizime int16 dhe pesha int8
Kuantizimi me aktivizime int16 është një skemë kuantizimi me numra të plotë me aktivizime në int16 dhe pesha në int8. Kjo mënyrë mund të përmirësojë saktësinë e modelit të kuantizuar në krahasim me skemën e kuantizimit me numra të plotë me aktivizime dhe pesha në int8 duke mbajtur një madhësi të ngjashme të modelit. Rekomandohet kur aktivizimet janë të ndjeshme ndaj kuantizimit.
SHËNIM: Aktualisht, vetëm implementimet e kernelit referues jo të optimizuara janë të disponueshme në TFLite për këtë skemë kuantizimi, kështu që si parazgjedhje performanca do të jetë e ngadaltë krahasuar me kernelët int8. Përparësitë e plota të këtij modaliteti aktualisht mund të aksesohen nëpërmjet pajisjeve të specializuara ose softuerëve të personalizuar.
Më poshtë janë rezultatet e saktësisë për disa modele që përfitojnë nga kjo mënyrë. Model Lloji i metrikës së saktësisë Saktësia (aktivizimet float32) Saktësia (aktivizimet int8) Saktësia (aktivizime int16) Wav2letter WER 6.7% 7.7% 7.2% DeepSpeech 0.5.1 (i hapur) CER 6.13% 43.67% 6.52% YoloV3 mAP(IOU=0.5) 0.577 0.563 0.574 MobileNetV1 Saktësia më e mirë 0.7062 0.694 0.6936 MobileNetV2 Saktësia më e mirë 0.718 0.7126 0.7137 MobileBert F1 (Përputhje e saktë) 88.81(81.23) 2.08(0) 88.73(81.15)
Krasitje
Shkurtimi funksionon duke hequr parametrat brenda një modeli që kanë vetëm një ndikim të vogël në parashikimet e tij. Modelet e shkurtuara kanë të njëjtën madhësi në disk dhe kanë të njëjtën vonesë në kohën e ekzekutimit, por mund të kompresohen në mënyrë më efektive. Kjo e bën shkurtimin një teknikë të dobishme për zvogëlimin e madhësisë së shkarkimit të modelit.
Në të ardhmen, LiteRT do të ofrojë reduktim të latencës për modelet e shkurtuara.
Grumbullimi
Grupimi funksionon duke grupuar peshat e secilës shtresë në një model në një numër të paracaktuar grupimesh, dhe më pas duke ndarë vlerat e qendrës për peshat që i përkasin secilit grupim individual. Kjo zvogëlon numrin e vlerave unike të peshave në një model, duke zvogëluar kështu kompleksitetin e tij.
Si rezultat, modelet e grupuara mund të kompresohen në mënyrë më efektive, duke ofruar përfitime të vendosjes të ngjashme me shkurtimin.
Fluksi i punës së zhvillimit
Si pikënisje, kontrolloni nëse modelet në modelet e hostuara mund të funksionojnë për aplikacionin tuaj. Nëse jo, ne rekomandojmë që përdoruesit të fillojnë me mjetin e kuantizimit pas trajnimit, pasi ky është gjerësisht i zbatueshëm dhe nuk kërkon të dhëna trajnimi.
Për rastet kur objektivat e saktësisë dhe latencës nuk arrihen, ose mbështetja e përshpejtuesit të harduerit është e rëndësishme, trajnimi i vetëdijshëm për kuantizimin është opsioni më i mirë. Shihni teknikat shtesë të optimizimit në TensorFlow Model Optimization Toolkit .
Nëse doni ta zvogëloni më tej madhësinë e modelit tuaj, mund të provoni shkurtimin dhe/ose grupimin përpara se të kuantizoni modelet tuaja.