
ตัวดำเนินการแมชชีนเลิร์นนิง (ML) ที่คุณใช้ในโมเดลอาจส่งผลต่อกระบวนการ แปลงโมเดล TensorFlow เป็นรูปแบบ LiteRT ตัวแปลง LiteRT รองรับ การดำเนินการ TensorFlow จำนวนจำกัดที่ใช้ในโมเดลการอนุมานทั่วไป ซึ่ง หมายความว่าไม่ใช่ทุกโมเดลที่จะแปลงได้โดยตรง เครื่องมือแปลงช่วยให้คุณรวมตัวดำเนินการเพิ่มเติมได้ แต่การแปลงโมเดลด้วยวิธีนี้ยังกำหนดให้คุณต้องแก้ไขสภาพแวดล้อมรันไทม์ LiteRT ที่ใช้เพื่อเรียกใช้โมเดล ซึ่งอาจจำกัดความสามารถในการใช้ตัวเลือกการติดตั้งใช้งานรันไทม์มาตรฐาน เช่น บริการของ Google Play
LiteRT Converter ออกแบบมาเพื่อวิเคราะห์โครงสร้างโมเดลและใช้การเพิ่มประสิทธิภาพ เพื่อให้เข้ากันได้กับตัวดำเนินการที่รองรับโดยตรง เช่น ตัวแปลงอาจละเว้นหรือรวมตัวดำเนินการเหล่านั้นเพื่อ จับคู่กับตัวดำเนินการที่เทียบเท่าใน LiteRT ทั้งนี้ขึ้นอยู่กับตัวดำเนินการ ML ในโมเดล
แม้แต่สำหรับการดำเนินการที่รองรับ บางครั้งระบบก็คาดหวังรูปแบบการใช้งานที่เฉพาะเจาะจงด้วยเหตุผลด้านประสิทธิภาพ วิธีที่ดีที่สุดในการทำความเข้าใจวิธีสร้างโมเดล TensorFlow ที่ใช้กับ LiteRT ได้คือการพิจารณาอย่างรอบคอบว่าการดำเนินการจะ แปลงและเพิ่มประสิทธิภาพอย่างไร รวมถึงข้อจำกัดที่กระบวนการนี้กำหนด
โอเปอเรเตอร์ที่รองรับ
โอเปอเรเตอร์ในตัวของ LiteRT เป็นส่วนย่อยของโอเปอเรเตอร์ที่เป็นส่วนหนึ่งของ ไลบรารีหลักของ TensorFlow โมเดล TensorFlow อาจมีโอเปอเรเตอร์ที่กำหนดเอง ในรูปแบบของโอเปอเรเตอร์แบบคอมโพสิตหรือโอเปอเรเตอร์ใหม่ที่คุณกำหนด แผนภาพ ด้านล่างแสดงความสัมพันธ์ระหว่างโอเปอเรเตอร์เหล่านี้
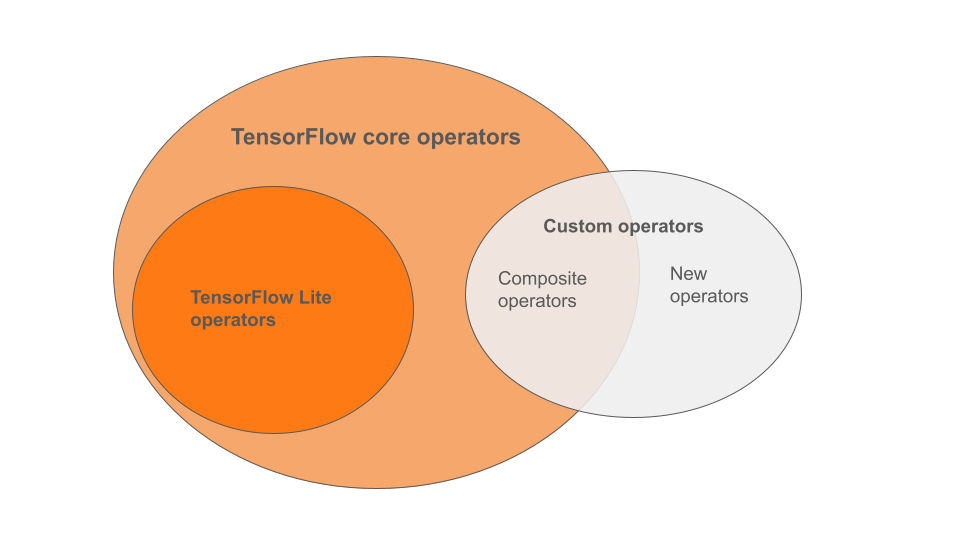
จากช่วงของตัวดำเนินการโมเดล ML นี้ มีโมเดล 3 ประเภทที่กระบวนการ Conversion รองรับ ดังนี้
- โมเดลที่มีเฉพาะโอเปอเรเตอร์ LiteRT ในตัว (แนะนำ)
- โมเดลที่มีโอเปอเรเตอร์ในตัวและเลือกโอเปอเรเตอร์หลักของ TensorFlow
- โมเดลที่มีตัวดำเนินการในตัว ตัวดำเนินการหลักของ TensorFlow และ/หรือตัวดำเนินการที่กำหนดเอง
หากโมเดลมีเฉพาะการดำเนินการที่ LiteRT รองรับโดยเนทีฟ คุณก็ไม่จำเป็นต้องใช้แฟล็กเพิ่มเติมเพื่อแปลงโมเดล นี่คือเส้นทางที่แนะนำ เนื่องจากโมเดลประเภทนี้จะแปลงได้อย่างราบรื่น และเพิ่มประสิทธิภาพและ เรียกใช้ได้ง่ายกว่าโดยใช้รันไทม์ LiteRT เริ่มต้น นอกจากนี้ คุณยังมีตัวเลือกการติดตั้งใช้งานเพิ่มเติมสำหรับโมเดล เช่น บริการ Google Play คุณเริ่มต้นใช้งานได้โดยอ่านคู่มือตัวแปลง LiteRT ดูรายการตัวดำเนินการในตัวได้ที่หน้า LiteRT Ops
หากต้องการรวมการดำเนินการ TensorFlow บางรายการจากไลบรารีหลัก คุณต้องระบุที่ Conversion และตรวจสอบว่ารันไทม์รวมการดำเนินการเหล่านั้น ดูขั้นตอนโดยละเอียดได้ที่หัวข้อเลือกโอเปอเรเตอร์ TensorFlow
หลีกเลี่ยงตัวเลือกสุดท้ายของการรวมโอเปอเรเตอร์ที่กำหนดเองในโมเดลที่แปลงแล้วทุกครั้งที่เป็นไปได้ โอเปอเรเตอร์ที่กำหนดเอง คือโอเปอเรเตอร์ที่สร้างขึ้นโดยการรวมโอเปอเรเตอร์หลักของ TensorFlow หลายรายการ หรือกำหนดโอเปอเรเตอร์ใหม่ทั้งหมด เมื่อแปลงตัวดำเนินการที่กำหนดเอง ตัวดำเนินการดังกล่าวจะเพิ่มขนาดของโมเดลโดยรวมได้ด้วยการทำให้เกิดการอ้างอิง ภายนอกไลบรารี LiteRT ในตัว การดำเนินการที่กำหนดเอง หากไม่ได้สร้างขึ้นมาโดยเฉพาะ สำหรับการติดตั้งใช้งานบนอุปกรณ์เคลื่อนที่หรืออุปกรณ์ อาจส่งผลให้ประสิทธิภาพแย่ลงเมื่อติดตั้งใช้งาน ในอุปกรณ์ที่มีข้อจำกัดด้านทรัพยากรเมื่อเทียบกับสภาพแวดล้อมของเซิร์ฟเวอร์ สุดท้ายนี้ เช่นเดียวกับการรวมโอเปอเรเตอร์หลักของ TensorFlow บางรายการ โอเปอเรเตอร์ที่กำหนดเองกำหนดให้คุณต้องแก้ไขสภาพแวดล้อมรันไทม์ของโมเดล ซึ่งจำกัดไม่ให้คุณใช้ประโยชน์จากบริการรันไทม์มาตรฐาน เช่น บริการของ Google Play
ประเภทที่รองรับ
การดำเนินการ LiteRT ส่วนใหญ่กำหนดเป้าหมายทั้งการอนุมานแบบจุดลอยตัว (float32) และแบบควอนไทซ์
(uint8, int8) แต่การดำเนินการหลายอย่างยังไม่รองรับการอนุมานประเภทอื่นๆ เช่น tf.float16 และสตริง
นอกเหนือจากการใช้การดำเนินการเวอร์ชันต่างๆ แล้ว ความแตกต่างอื่นๆ ระหว่างโมเดลแบบจุดลอยและโมเดลที่แปลงเป็นจำนวนเต็มคือวิธีการแปลง Conversion ที่มีการวัดปริมาณต้องมีข้อมูลช่วงไดนามิกสำหรับเทนเซอร์ ซึ่งต้องใช้ "การจำลองควอนไทเซชัน" ระหว่างการฝึกโมเดล รับข้อมูลช่วง ผ่านชุดข้อมูลการปรับเทียบ หรือทำการประมาณช่วง "แบบเรียลไทม์" ดูรายละเอียดเพิ่มเติมได้ที่ การควอนไทซ์
การแปลงแบบตรงไปตรงมา การพับแบบคงที่ และการหลอมรวม
LiteRT สามารถประมวลผลการดำเนินการ TensorFlow จำนวนมากได้แม้ว่าจะไม่มีการดำเนินการที่เทียบเท่าโดยตรงก็ตาม
กรณีนี้เกิดขึ้นกับการดำเนินการที่สามารถนำออกจากกราฟ (tf.identity) แทนที่ด้วยเทนเซอร์ (tf.placeholder) หรือรวมเข้ากับการดำเนินการที่ซับซ้อนมากขึ้น (tf.nn.bias_add) ได้อย่างง่ายดาย แม้แต่การดำเนินการบางอย่างที่รองรับก็อาจถูกนำออกผ่านกระบวนการเหล่านี้ในบางครั้ง
ต่อไปนี้เป็นรายการการดำเนินการ TensorFlow โดยสังเขปที่มักจะถูกนำออกจากกราฟ
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
การดำเนินการทดลอง
การดำเนินการ LiteRT ต่อไปนี้มีอยู่ แต่ยังไม่พร้อมใช้งานกับโมเดลที่กำหนดเอง
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF