Imagen คือโมเดลการสร้างรูปภาพที่มีความเที่ยงตรงสูงของ Google ซึ่งสามารถสร้าง รูปภาพที่สมจริงและมีคุณภาพสูงจากพรอมต์ข้อความ รูปภาพที่สร้างขึ้นทั้งหมด จะมีลายน้ำ SynthID ดูข้อมูลเพิ่มเติมเกี่ยวกับโมเดล Imagen ที่มีให้ใช้งานได้ในส่วนเวอร์ชันของโมเดล
สร้างรูปภาพโดยใช้โมเดล Imagen
ตัวอย่างนี้แสดงการสร้างรูปภาพด้วยโมเดล Imagen
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

การกำหนดค่า Imagen
ปัจจุบัน Imagen รองรับเฉพาะพรอมต์ภาษาอังกฤษและพารามิเตอร์ต่อไปนี้
numberOfImages: จำนวนรูปภาพที่จะสร้าง ตั้งแต่ 1 ถึง 4 (รวม) ค่าเริ่มต้นคือ 4imageSize: ขนาดของรูปภาพที่สร้างขึ้น ฟีเจอร์นี้รองรับเฉพาะรุ่น Standard และ Ultra ค่าที่รองรับคือ1Kและ2Kค่าเริ่มต้นคือ1KaspectRatio: เปลี่ยนสัดส่วนภาพของรูปภาพที่สร้างขึ้น ค่าที่รองรับคือ"1:1","3:4","4:3","9:16"และ"16:9"ค่าเริ่มต้นคือ"1:1"personGeneration: อนุญาตให้โมเดลสร้างรูปภาพบุคคล ค่าที่รองรับมีดังนี้"dont_allow": บล็อกการสร้างรูปภาพบุคคล"allow_adult": สร้างรูปภาพของผู้ใหญ่ แต่ไม่ใช่เด็ก ซึ่งเป็นค่าเริ่มต้น"allow_all": สร้างรูปภาพที่มีผู้ใหญ่และเด็ก
คู่มือการใช้พรอมต์ Imagen
ส่วนนี้ของคำแนะนำเกี่ยวกับ Imagen จะแสดงให้เห็นว่าการแก้ไขพรอมต์ข้อความเป็นรูปภาพ สามารถสร้างผลลัพธ์ที่แตกต่างกันได้อย่างไร พร้อมตัวอย่างรูปภาพที่คุณสร้างได้
ข้อมูลเบื้องต้นเกี่ยวกับการเขียนพรอมต์
พรอมต์ที่ดีควรสื่อความหมายและชัดเจน รวมถึงใช้คีย์เวิร์ดและตัวแก้ไขที่มีความหมาย เริ่มจากการคิดถึงตัวแบบ บริบท และสไตล์

เรื่อง: สิ่งแรกที่ต้องคิดถึงเมื่อใช้พรอมต์คือเรื่อง ซึ่งก็คือวัตถุ บุคคล สัตว์ หรือทิวทัศน์ที่คุณต้องการให้เป็นรูปภาพ
บริบทและพื้นหลัง: พื้นหลังหรือบริบท ที่วางวัตถุมีความสำคัญไม่แพ้กัน ลองวางวัตถุในพื้นหลังที่หลากหลาย เช่น สตูดิโอที่มีพื้นหลังสีขาว กลางแจ้ง หรือ สภาพแวดล้อมในร่ม
สไตล์: สุดท้าย ให้เพิ่มสไตล์ของรูปภาพที่ต้องการ สไตล์อาจเป็นแบบทั่วไป (ภาพวาด ภาพถ่าย ภาพร่าง) หรือเฉพาะเจาะจงมาก (ภาพวาดสีพาสเทล ภาพวาด ถ่าน ภาพ 3 มิติแบบไอโซเมตริก) นอกจากนี้ คุณยังรวมสไตล์ได้ด้วย
หลังจากเขียนพรอมต์เวอร์ชันแรกแล้ว ให้ปรับแต่งพรอมต์โดยเพิ่มรายละเอียด เพิ่มเติมจนกว่าจะได้รูปภาพที่ต้องการ การทำซ้ำเป็นสิ่งสำคัญ เริ่มต้นด้วยการกำหนดแนวคิดหลัก จากนั้นปรับแต่งและขยายแนวคิดหลักนั้นจนกว่ารูปภาพที่สร้างขึ้นจะใกล้เคียงกับวิสัยทัศน์ของคุณ

|

|

|
โมเดล Imagen สามารถเปลี่ยนไอเดียของคุณให้กลายเป็นรูปภาพที่มีรายละเอียด ไม่ว่าพรอมต์ของคุณจะสั้นหรือยาวและมีรายละเอียดก็ตาม ปรับแต่งวิสัยทัศน์ของคุณ ผ่านการป้อนพรอมต์แบบวนซ้ำ โดยเพิ่มรายละเอียดจนกว่าจะได้ผลลัพธ์ที่สมบูรณ์แบบ
|
พรอมต์แบบสั้นช่วยให้คุณสร้างรูปภาพได้อย่างรวดเร็ว 
|
พรอมต์ที่ยาวขึ้นจะช่วยให้คุณเพิ่มรายละเอียดที่เฉพาะเจาะจงและสร้างรูปภาพได้ 
|
คำแนะนำเพิ่มเติมสำหรับการเขียนพรอมต์ของ Imagen
- ใช้ภาษาที่สื่อความหมาย: ใช้คำคุณศัพท์และคำกริยาวิเศษณ์โดยละเอียดเพื่อ วาดภาพที่ชัดเจนสำหรับ Imagen
- ระบุบริบท: หากจำเป็น ให้ระบุข้อมูลพื้นฐานเพื่อช่วยให้ AI เข้าใจ
- อ้างอิงศิลปินหรือสไตล์ที่เฉพาะเจาะจง: หากคุณมีสุนทรียะที่เฉพาะเจาะจงในใจ การอ้างอิงศิลปินหรือขบวนการศิลปะที่เฉพาะเจาะจงอาจเป็นประโยชน์
- ใช้เครื่องมือวิศวกรรมพรอมต์: ลองสำรวจเครื่องมือหรือแหล่งข้อมูลวิศวกรรมพรอมต์ เพื่อช่วยปรับแต่งพรอมต์และให้ได้ผลลัพธ์ที่ดีที่สุด
- การปรับปรุงรายละเอียดใบหน้าในรูปภาพส่วนตัวและรูปภาพกลุ่ม: ระบุรายละเอียดใบหน้าเป็นจุดโฟกัสของรูปภาพ (เช่น ใช้คำว่า "ภาพบุคคล" ในพรอมต์)
สร้างข้อความในรูปภาพ
โมเดล Imagen สามารถเพิ่มข้อความลงในรูปภาพได้ ซึ่งจะช่วยเปิดโอกาสในการสร้างรูปภาพที่สร้างสรรค์มากขึ้น คำแนะนำต่อไปนี้จะช่วยให้คุณใช้ประโยชน์จากฟีเจอร์นี้ได้มากที่สุด
- ทำซ้ำได้อย่างมั่นใจ: คุณอาจต้องสร้างรูปภาพใหม่จนกว่าจะได้ รูปลักษณ์ที่ต้องการ การผสานรวมข้อความของ Imagen ยังคง พัฒนาต่อไป และบางครั้งการลองหลายๆ ครั้งอาจให้ผลลัพธ์ที่ดีที่สุด
- เขียนให้กระชับ: จำกัดข้อความให้มีอักขระไม่เกิน 25 ตัวเพื่อการสร้างที่เหมาะสมที่สุด
หลายวลี: ทดลองใช้วลีที่แตกต่างกัน 2-3 วลีเพื่อ ให้ข้อมูลเพิ่มเติม หลีกเลี่ยงการใช้คำมากกว่า 3 คำเพื่อให้ องค์ประกอบมีความชัดเจนยิ่งขึ้น

พรอมต์: โปสเตอร์ที่มีข้อความ "Summerland" เป็นตัวหนาเป็น ชื่อ และมีสโลแกน "Summer never felt so good" อยู่ใต้ข้อความนี้ คำแนะนำในการจัดวาง: แม้ว่า Imagen จะพยายามจัดวางข้อความตามที่สั่ง แต่ก็อาจมีการเปลี่ยนแปลงบ้างในบางครั้ง เรากำลังปรับปรุงฟีเจอร์นี้อย่างต่อเนื่อง
รูปแบบแบบอักษรที่สร้างแรงบันดาลใจ: ระบุรูปแบบแบบอักษรทั่วไปเพื่อมีอิทธิพลต่อตัวเลือกของ Imagen อย่างละเอียด อย่าพึ่งพาการจำลองแบบอักษรที่แม่นยำ แต่คาดหวังการตีความเชิงสร้างสรรค์
ขนาดแบบอักษร: ระบุขนาดแบบอักษรหรือข้อบ่งชี้ทั่วไปเกี่ยวกับขนาด (เช่น เล็ก ปานกลาง ใหญ่) เพื่อกำหนดการสร้างขนาดแบบอักษร
การกำหนดพารามิเตอร์ของพรอมต์
คุณอาจพบว่าการกำหนดพารามิเตอร์อินพุตเป็น Imagen จะช่วยให้ควบคุมผลลัพธ์ได้ดียิ่งขึ้น ตัวอย่างเช่น สมมติว่าคุณต้องการให้ลูกค้าสร้างโลโก้สำหรับธุรกิจของตนได้ และต้องการให้มั่นใจว่าระบบจะสร้างโลโก้บนพื้นหลังสีทึบเสมอ นอกจากนี้ คุณยังอาจต้องการจำกัดตัวเลือกที่ไคลเอ็นต์เลือกได้จากเมนูด้วย
ในตัวอย่างนี้ คุณสามารถสร้างพรอมต์ที่มีพารามิเตอร์คล้ายกับพรอมต์ต่อไปนี้ได้
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.ในอินเทอร์เฟซผู้ใช้ที่กำหนดเอง ลูกค้าจะป้อนพารามิเตอร์โดยใช้เมนูได้ และค่าที่เลือกจะป้อนลงในพรอมต์ที่ Imagen ได้รับ
เช่น
พรอมต์:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
พรอมต์:
A modern logo for a software company on a solid color background. Include the text Silo.
พรอมต์:
A traditional logo for a baking company on a solid color background. Include the text Seed.
เทคนิคการเขียนพรอมต์ขั้นสูง
ใช้ตัวอย่างต่อไปนี้เพื่อสร้างพรอมต์ที่เฉพาะเจาะจงมากขึ้นโดยอิงตามแอตทริบิวต์ เช่น คำอธิบายการถ่ายภาพ รูปร่างและวัสดุ ขบวนการศิลปะในประวัติศาสตร์ และตัวแก้ไขคุณภาพของรูปภาพ
การถ่ายภาพ
- พรอมต์มีข้อความว่า "รูปภาพของ..."
หากต้องการใช้สไตล์นี้ ให้เริ่มต้นด้วยการใช้คีย์เวิร์ดที่บอก Imagen อย่างชัดเจนว่าคุณกำลังมองหารูปถ่าย เริ่มต้นพรอมต์ด้วย "รูปภาพของ . " เช่น

|

|

|
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 4
ตัวปรับแต่งการถ่ายภาพ
ในตัวอย่างต่อไปนี้ คุณจะเห็นตัวแก้ไขและพารามิเตอร์เฉพาะการถ่ายภาพหลายรายการ คุณรวมตัวแก้ไขหลายรายการเพื่อควบคุมได้อย่างแม่นยำยิ่งขึ้น
ระยะใกล้ของกล้อง - ถ่ายจากระยะไกลในระยะใกล้

พรอมต์: รูปภาพระยะใกล้ของเมล็ดกาแฟ 
พรอมต์: รูปภาพซูมออกของถุงเล็กๆ ที่ใส่
เมล็ดกาแฟในครัวที่รกตำแหน่งกล้อง - มุมสูงจากด้านล่าง

พรอมต์: ภาพถ่ายทางอากาศของเมืองที่มีตึกสูง 
พรอมต์: ภาพหลังคาป่าที่มีท้องฟ้าสีฟ้าจากด้านล่าง แสง - ธรรมชาติ สื่ออารมณ์ อบอุ่น เย็น

พรอมต์: ภาพถ่ายสตูดิโอของอาร์มแชร์สมัยใหม่ การปรับแสงแบบธรรมชาติ 
พรอมต์: ภาพถ่ายอาร์มแชร์สมัยใหม่ในสตูดิโอ การจัดแสงที่น่าทึ่ง การตั้งค่ากล้อง - เบลอการเคลื่อนไหว โฟกัสแบบนุ่ม โบเก้ ภาพบุคคล

พรอมต์: รูปภาพเมืองที่มีตึกระฟ้าจากภายในรถยนต์ที่มีภาพเบลอจากการเคลื่อนไหว 
พรอมต์: ซอฟต์โฟกัสภาพถ่ายสะพานในเมืองยามค่ำคืน ประเภทเลนส์ - 35 มม., 50 มม., ฟิชอาย, มุมกว้าง, มาโคร

พรอมต์: ภาพใบไม้ เลนส์มาโคร 
พรอมต์: ภาพถ่ายบนท้องถนน, นิวยอร์กซิตี้, เลนส์ฟิชอาย ประเภทฟิล์ม - ขาวดำ โพลารอยด์

พรอมต์: ภาพถ่ายบุคคลแบบโพลารอยด์ของสุนัขที่สวมแว่นกันแดด 
พรอมต์: ภาพขาวดำของสุนัขที่ใส่แว่นกันแดด
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 4
ภาพและศิลปะ
- พรอมต์มีข้อความว่า "painting ของ..." "sketch ของ..."
สไตล์ศิลปะมีตั้งแต่สไตล์ขาวดำ เช่น ภาพสเก็ตช์ดินสอ ไปจนถึงศิลปะดิจิทัลที่สมจริงอย่างมาก ตัวอย่างเช่น รูปภาพต่อไปนี้ใช้พรอมต์เดียวกันแต่มีสไตล์แตกต่างกัน
"[art style or creation technique]ของรถซีดานไฟฟ้าสปอร์ตแบบเหลี่ยมที่มีตึกระฟ้าเป็นฉากหลัง"

|

|

|

|

|

|
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 2
รูปร่างและวัสดุ
- พรอมต์มีข้อความต่อไปนี้ "...ทำจาก..." "...ในรูปของ..."
จุดแข็งอย่างหนึ่งของเทคโนโลยีนี้คือคุณสามารถสร้างภาพที่ ทำได้ยากหรือทำไม่ได้เลยหากไม่มีเทคโนโลยีนี้ เช่น คุณสามารถสร้างโลโก้บริษัทใหม่ในวัสดุและพื้นผิวต่างๆ

|

|

|
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 4
ข้อมูลอ้างอิงเกี่ยวกับศิลปะในประวัติศาสตร์
- พรอมต์มีข้อความว่า "...ในสไตล์ของ..."
สไตล์บางอย่างกลายเป็นสัญลักษณ์ที่โดดเด่นในช่วงหลายปีที่ผ่านมา ต่อไปนี้คือไอเดีย ภาพวาดหรือสไตล์ศิลปะในประวัติศาสตร์ที่คุณลองใช้ได้
"สร้างรูปภาพในสไตล์ของ [art period or movement] : กังหันลม"

|

|

|
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 4
ตัวแก้ไขคุณภาพของรูปภาพ
คีย์เวิร์ดบางคำจะช่วยให้โมเดลทราบว่าคุณกำลังมองหาชิ้นงานคุณภาพสูง ตัวอย่างตัวปรับคุณภาพมีดังนี้
- ตัวดัดแปลงทั่วไป - คุณภาพสูง สวยงาม มีสไตล์
- รูปภาพ - 4K, HDR, รูปภาพสตูดิโอ
- ภาพวาด ภาพประกอบ - โดยมืออาชีพ มีรายละเอียด
ต่อไปนี้คือตัวอย่างพรอมต์บางส่วนที่ไม่มีตัวปรับแต่งคุณภาพและพรอมต์เดียวกันที่มีตัวปรับแต่งคุณภาพ

|

photo of a corn stalk taken by a professional photographer |
แหล่งที่มาของรูปภาพ: รูปภาพแต่ละรูปสร้างขึ้นโดยใช้พรอมต์ข้อความที่เกี่ยวข้องกับโมเดล Imagen 4
สัดส่วนภาพ
การสร้างรูปภาพด้วย Imagen ช่วยให้คุณกำหนดสัดส่วนภาพที่แตกต่างกัน 5 แบบได้
- สี่เหลี่ยมจัตุรัส (1:1, ค่าเริ่มต้น) - รูปภาพสี่เหลี่ยมจัตุรัสมาตรฐาน การใช้งานทั่วไปสำหรับ สัดส่วนภาพนี้ ได้แก่ โพสต์ในโซเชียลมีเดีย
เต็มหน้าจอ (4:3) - สัดส่วนภาพนี้มักใช้ในสื่อหรือภาพยนตร์ นอกจากนี้ยังเป็นสัดส่วนของทีวีรุ่นเก่า (ที่ไม่ใช่ไวด์สกรีน) และกล้องฟอร์แมตขนาดกลางส่วนใหญ่ด้วย โดยจะจับภาพฉากในแนวนอนได้มากขึ้น (เมื่อเทียบกับ 1:1) จึงเป็นสัดส่วนภาพที่ต้องการสำหรับการถ่ายภาพ

พรอมต์: ภาพนิ้วมือของนักดนตรีในระยะใกล้ กำลังเล่นเปียโน ฟิล์มขาวดำ วินเทจ (สัดส่วนภาพ 4:3) 
พรอมต์: ภาพถ่ายในสตูดิโอระดับมืออาชีพของ เฟรนช์ฟรายสำหรับร้านอาหารระดับไฮเอนด์ ในสไตล์ของนิตยสารอาหาร (สัดส่วนภาพ 4:3) เต็มหน้าจอแนวตั้ง (3:4) - นี่คือสัดส่วนภาพแบบเต็มหน้าจอที่หมุน 90 องศา ซึ่งช่วยให้จับภาพฉากในแนวตั้งได้มากขึ้นเมื่อเทียบกับสัดส่วนภาพ 1:1

พรอมต์: ผู้หญิงเดินป่า ภาพระยะใกล้ของ รองเท้าบูทที่สะท้อนในแอ่งน้ำ ภูเขาขนาดใหญ่เป็นฉากหลัง ใน สไตล์โฆษณา มุมที่น่าทึ่ง (สัดส่วนภาพ 3:4) 
พรอมต์: ภาพมุมสูงของแม่น้ำที่ไหล ขึ้นไปในหุบเขาลึกลับ (สัดส่วนภาพ 3:4) จอกว้าง (16:9) - อัตราส่วนนี้มาแทนที่ 4:3 และปัจจุบันเป็นอัตราส่วนที่พบมากที่สุด สำหรับทีวี จอภาพ และหน้าจอโทรศัพท์มือถือ (แนวนอน) ใช้สัดส่วนภาพนี้เมื่อต้องการบันทึกภาพพื้นหลังให้มากขึ้น (เช่น ทิวทัศน์ที่สวยงาม)

พรอมต์: ชายสวมเสื้อผ้าสีขาวทั้งหมดนั่งอยู่บนชายหาด ถ่ายภาพระยะใกล้ แสงสีช่วงเวลาแสงสีทอง (สัดส่วนภาพ 16:9) แนวตั้ง (9:16) - อัตราส่วนนี้เป็นจอกว้างแต่หมุน อัตราส่วนภาพนี้เป็นอัตราส่วนภาพที่ค่อนข้างใหม่ซึ่งได้รับความนิยมจากแอปวิดีโอแบบสั้น (เช่น YouTube Shorts) ใช้สำหรับวัตถุสูงที่มีการวางแนวตั้งที่ชัดเจน เช่น อาคาร ต้นไม้ น้ำตก หรือวัตถุอื่นๆ ที่คล้ายกัน

พรอมต์: ภาพเรนเดอร์ดิจิทัลของตึกระฟ้าขนาดใหญ่ ทันสมัย ยิ่งใหญ่ อลังการ โดยมีภาพพระอาทิตย์ตกที่สวยงามเป็นพื้นหลัง (สัดส่วนภาพ 9:16)
รูปภาพสมจริง
โมเดลการสร้างรูปภาพเวอร์ชันต่างๆ อาจให้ผลลัพธ์ทั้งแบบศิลปะและแบบสมจริง ใช้คำต่อไปนี้ในพรอมต์เพื่อสร้างเอาต์พุตที่สมจริงมากขึ้นตามวัตถุ ที่คุณต้องการสร้าง
| กรณีการใช้งาน | ประเภทเลนส์ | ความยาวโฟกัส | รายละเอียดเพิ่มเติม |
|---|---|---|---|
| ผู้คน (ภาพบุคคล) | ไพรม์ ซูม | 24-35 มม. | ฟิล์มขาวดำ, ฟิล์มนัวร์, ระยะชัดลึก, ดูโอโทน (ระบุ 2 สี) |
| อาหาร แมลง พืช (วัตถุ ภาพหุ่นนิ่ง) | มาโคร | 60-105 มม. | รายละเอียดสูง โฟกัสแม่นยำ แสงที่ควบคุมได้ |
| กีฬา สัตว์ป่า (การเคลื่อนไหว) | ซูมเทเลโฟโต้ | 100-400 มม. | ความเร็วชัตเตอร์สูง การติดตามการเคลื่อนไหวหรือการเคลื่อนที่ |
| ดาราศาสตร์, ภูมิทัศน์ (มุมกว้าง) | ไวด์ | 10-24 มม. | เวลาเปิดรับแสงนาน โฟกัสคมชัด เปิดรับแสงนาน น้ำหรือเมฆเรียบ |
ภาพพอร์เทรต
| กรณีการใช้งาน | ประเภทเลนส์ | ความยาวโฟกัส | รายละเอียดเพิ่มเติม |
|---|---|---|---|
| ผู้คน (ภาพบุคคล) | ไพรม์ ซูม | 24-35 มม. | ฟิล์มขาวดำ, ฟิล์มนัวร์, ระยะชัดลึก, ดูโอโทน (ระบุ 2 สี) |
Imagen สามารถสร้างภาพบุคคลต่อไปนี้ได้โดยใช้คีย์เวิร์ดหลายคำจากตาราง

|

|

|

|
พรอมต์: ภาพบุคคลผู้หญิง 35 มม. ดูโอโทนสีน้ำเงินและเทา
โมเดล: imagen-4.0-generate-001

|

|

|

|
พรอมต์: ภาพบุคคลผู้หญิงขนาด 35 มม. ฟิล์มนัวร์
โมเดล: imagen-4.0-generate-001
วัตถุ
| กรณีการใช้งาน | ประเภทเลนส์ | ความยาวโฟกัส | รายละเอียดเพิ่มเติม |
|---|---|---|---|
| อาหาร แมลง พืช (วัตถุ ภาพหุ่นนิ่ง) | มาโคร | 60-105 มม. | รายละเอียดสูง โฟกัสแม่นยำ แสงที่ควบคุมได้ |
เมื่อใช้คีย์เวิร์ดหลายคำจากตาราง Imagen จะสร้างรูปภาพออบเจ็กต์ต่อไปนี้ได้

|

|

|

|
พรอมต์: ใบของต้นอธิษฐาน เลนส์มาโคร 60 มม.
โมเดล: imagen-4.0-generate-001

|

|

|

|
พรอมต์: จานพาสต้า เลนส์มาโคร 100 มม.
โมเดล: imagen-4.0-generate-001
การเคลื่อนไหว
| กรณีการใช้งาน | ประเภทเลนส์ | ความยาวโฟกัส | รายละเอียดเพิ่มเติม |
|---|---|---|---|
| กีฬา สัตว์ป่า (การเคลื่อนไหว) | ซูมเทเลโฟโต้ | 100-400 มม. | ความเร็วชัตเตอร์สูง การติดตามการเคลื่อนไหวหรือการเคลื่อนที่ |
เมื่อใช้คีย์เวิร์ดหลายคำจากตาราง Imagen จะ สร้างภาพเคลื่อนไหวต่อไปนี้ได้

|

|
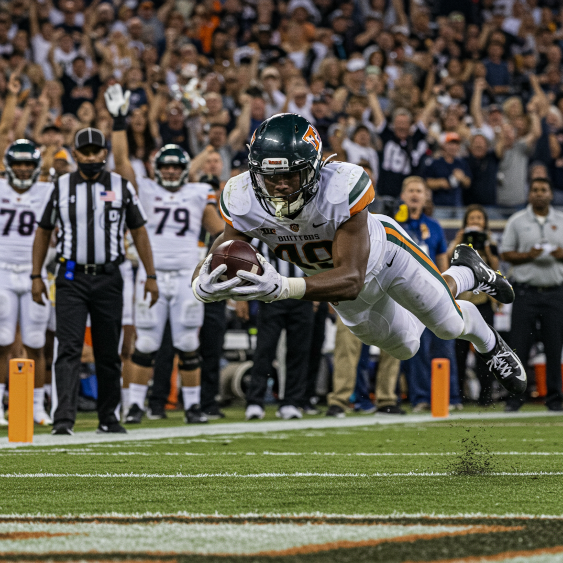
|

|
พรอมต์: ทัชดาวน์ที่ชนะ ความเร็วชัตเตอร์สูง การติดตามการเคลื่อนไหว
โมเดล: imagen-4.0-generate-001

|

|

|

|
พรอมต์: กวางวิ่งในป่า ความเร็วชัตเตอร์สูง การติดตามการเคลื่อนไหว
โมเดล: imagen-4.0-generate-001
ไวด์
| กรณีการใช้งาน | ประเภทเลนส์ | ความยาวโฟกัส | รายละเอียดเพิ่มเติม |
|---|---|---|---|
| ดาราศาสตร์, ภูมิทัศน์ (มุมกว้าง) | ไวด์ | 10-24 มม. | เวลาเปิดรับแสงนาน โฟกัสคมชัด เปิดรับแสงนาน น้ำหรือเมฆเรียบ |
Imagen สามารถสร้างรูปภาพมุมกว้างต่อไปนี้ได้โดยใช้คีย์เวิร์ดหลายคำจากตาราง

|

|

|

|
พรอมต์: เทือกเขากว้างใหญ่ มุมกว้าง 10 มม.
โมเดล: imagen-4.0-generate-001

|

|

|

|
พรอมต์: รูปภาพดวงจันทร์ การถ่ายภาพดวงดาว มุมกว้าง 10 มม.
โมเดล: imagen-4.0-generate-001
เวอร์ชันของโมเดล
Imagen 4
| พร็อพเพอร์ตี้ | คำอธิบาย |
|---|---|
| รหัสโมเดล |
Gemini API
|
| ประเภทข้อมูลที่รองรับ |
อินพุต ข้อความ เอาต์พุต รูปภาพ |
| ขีดจำกัดของโทเค็น[*] |
ขีดจำกัดโทเค็นอินพุต 480 โทเค็น (ข้อความ) รูปภาพเอาต์พุต 1 ถึง 4 (Ultra/Standard/Fast) |
| การอัปเดตล่าสุด | มิถุนายน 2025 |
Imagen 3
ปิดโมเดล Imagen 3 แล้ว