
边缘设备的内存或计算能力通常有限。您可以对模型应用各种优化,以便在这些限制条件下运行模型。此外,某些优化允许使用专用硬件来加速推理。
LiteRT 和 TensorFlow 模型优化工具包提供了一些工具,可最大限度地降低优化推断的复杂性。
建议您在应用开发过程中考虑模型优化。本文档概述了针对部署到边缘硬件优化 TensorFlow 模型的一些最佳实践。
为何应优化模型
模型优化可通过多种主要方式帮助进行应用开发。
缩小尺寸
某些形式的优化可用于缩减模型的大小。较小的模型具有以下优势:
- 存储空间占用量更小:较小的模型在用户设备上占用的存储空间更少。例如,使用较小模型的 Android 应用会占用用户移动设备上较少的存储空间。
- 下载大小更小:较小的模型需要更少的时间和带宽才能下载到用户设备。
- 内存用量更少:较小的模型在运行时使用的 RAM 更少,这会释放内存供应用的其他部分使用,从而提高性能和稳定性。
在所有这些情况下,量化都可以减小模型的大小,但可能会牺牲一定的准确率。剪枝和聚类可以使模型更易于压缩,从而减小模型的大小以便下载。
减少延迟
延迟时间是指使用给定模型运行单次推理所需的时间。某些形式的优化可以减少使用模型运行推理所需的计算量,从而缩短延迟时间。延迟时间也会影响能耗。
目前,量化可以通过简化推理期间发生的计算来缩短延迟时间,但可能会牺牲一些准确性。
加速器兼容性
某些硬件加速器(例如 Edge TPU)可以利用经过正确优化的模型极快地运行推理。
一般来说,这类设备需要以特定方式对模型进行量化。如需详细了解每种硬件加速器的要求,请参阅其文档。
权衡因素
优化可能会导致模型准确率发生变化,在应用开发过程中必须考虑到这一点。
准确率变化取决于所优化的具体模型,很难提前预测。一般来说,针对大小或延迟时间进行优化的模型会损失少量准确率。根据您的应用,这可能会影响用户体验,也可能不会。在极少数情况下,某些模型可能会因优化过程而提高准确性。
优化类型
LiteRT 目前支持通过量化、剪枝和聚类进行优化。
这些是 TensorFlow 模型优化工具包的一部分,该工具包可为与 TensorFlow Lite 兼容的模型优化技术提供资源。
量化
量化通过降低用于表示模型参数的数字的精度(默认情况下为 32 位浮点数)来发挥作用。这样可以减小模型大小并加快计算速度。
LiteRT 中提供以下量化类型:
| 技术 | 数据要求 | 缩小尺寸 | 准确率 | 支持的硬件 |
|---|---|---|---|---|
| 训练后 float16 量化 | 无数据 | 高达 50% | 准确率损失不明显 | CPU、GPU |
| 训练后动态范围量化 | 无数据 | 最高可达 75% | 准确度损失最小 | CPU、GPU (Android) |
| 训练后整数量化 | 无标签代表性样本 | 最高可达 75% | 准确度损失较小 | CPU、GPU (Android)、EdgeTPU |
| 量化感知训练 | 已加标签的训练数据 | 最高可达 75% | 准确度损失最小 | CPU、GPU (Android)、EdgeTPU |
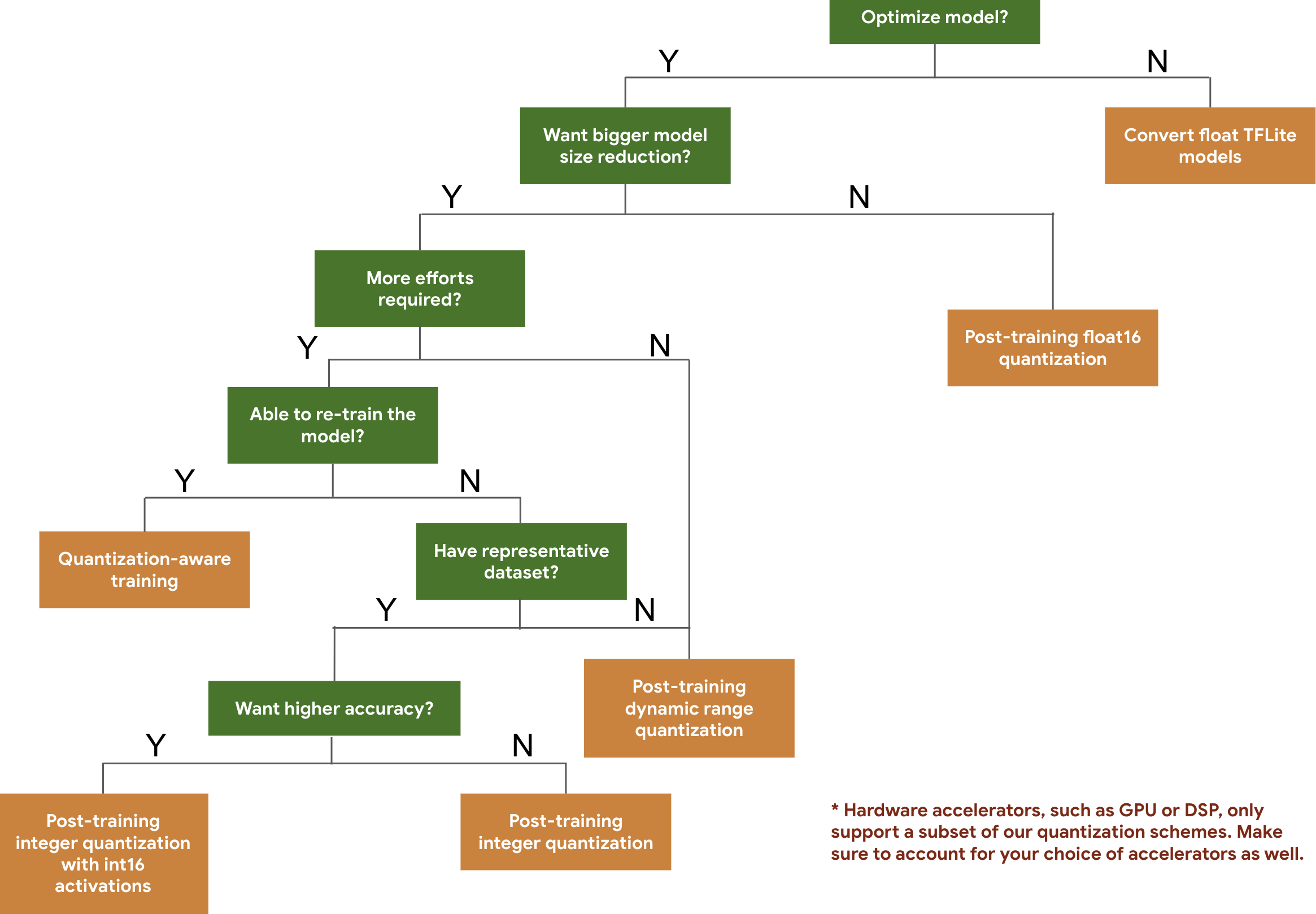
以下决策树可帮助您根据预期的模型大小和准确度,选择可能要用于模型的量化方案。
下表列出了对几个模型进行训练后量化和量化感知训练的延迟时间和准确率结果。所有延迟时间数据都是在 Pixel 2 设备上使用单个大核心 CPU 测量的。随着工具包的改进,此处的数字也会随之变化:
| 型号 | Top-1 准确率(原始) | Top-1 准确率(训练后量化) | Top-1 准确率(量化感知训练) | 延迟时间(原始)(毫秒) | 延迟时间(训练后量化)(毫秒) | 延迟时间(量化感知训练)(毫秒) | 大小(原始)(MB) | 大小(优化后)(以 MB 为单位) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | 不适用 | 3973 | 2868 | 不适用 | 178.3 | 44.9 |
使用 int16 激活函数和 int8 权重的全整数量化
使用 int16 激活函数的量化是一种全整数量化方案,其中激活函数为 int16,权重为 int8。与激活和权重均为 int8 的全整数量化方案相比,此模式可以提高量化模型的准确率,同时保持相似的模型大小。当激活对量化敏感时,建议使用此函数。
注意:目前,TFLite 中仅提供此量化方案的非优化参考内核实现,因此默认情况下,与 int8 内核相比,性能会较慢。目前,您可以通过专用硬件或自定义软件充分利用此模式的优势。
以下是部分受益于此模式的模型的准确率结果。
| 型号 | 准确率指标类型 | 准确率(float32 激活) | 准确率(int8 激活) | 准确率(int16 激活函数) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1(展开) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | Top-1 准确率 | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | Top-1 准确率 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(完全匹配) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
修剪
剪枝通过移除模型中对预测结果影响较小的参数来发挥作用。剪枝后的模型在磁盘上占用的大小相同,并且具有相同的运行时延迟,但可以更有效地进行压缩。因此,剪枝是一种可用于减小模型下载大小的实用技术。
未来,LiteRT 将为剪枝模型提供延迟时间缩短功能。
聚簇
聚类通过以下方式运作:将模型中每一层的权重分组成预定数量的聚类,然后共享属于每个聚类的权重的形心值。这样可以减少模型中唯一权重值的数量,从而降低其复杂性。
因此,聚类模型可以更有效地压缩,从而提供与剪枝类似的部署优势。
开发工作流程
首先,检查托管模型中的模型是否适用于您的应用。否则,我们建议用户先使用训练后量化工具,因为该工具适用范围广,且不需要训练数据。
如果无法达到准确率和延迟时间目标,或者硬件加速器支持非常重要,那么量化感知训练是更好的选择。如需了解其他优化技巧,请参阅 TensorFlow 模型优化工具包。