
LiteRT 是 Google 的设备端框架,用于在边缘平台上部署高性能 ML 和 GenAI。
高效的转化、运行时和优化,适用于设备端机器学习。
基于经过实战检验的 TensorFlow Lite 基础构建
LiteRT 不仅是新产品,还是全球部署最广泛的机器学习运行时的新一代产品。它为数以十亿计的设备提供支持,让您每天使用的应用能够以低延迟和高隐私保护的方式运行。
深受最关键的 Google 应用的信赖
超过 10 万款应用,数十亿全球用户
LiteRT 亮点

跨平台就绪

释放生成式 AI 的强大功能
简化硬件加速

多框架支持



选择您的开发路径
使用 LiteRT 将 AI 部署到任何地方,从高性能移动应用到资源受限的 IoT 设备。
现有 TFLite 用户
迁移到 LiteRT,以利用增强的性能和跨平台(Android、桌面设备、Web)的统一 API。
自带模型 (BYOM)
拥有 PyTorch 模型,希望实现设备端视觉或音频体验。
部署生成式 AI 模型
使用经过优化的开放权重生成式 AI 模型(例如 Gemma 或其他开放权重模型)创建复杂的设备端聊天机器人。
[高级] 模型专家
编写自定义模型或针对特定硬件 CPU/GPU/NPU 进行深度优化,以实现最佳性能。
示例、模型和演示

查看 GitHub 上的 LiteRT 示例应用
完整的端到端示例应用。

查看生成式 AI 模型
经过预先训练的开箱即用生成式 AI 模型。

观看演示 - Google AI Edge Gallery 应用
一个展示使用 LiteRT 的设备端 ML/GenAI 用例的库。
博客和公告
及时了解 LiteRT 团队发布的最新公告、深度技术研究和性能基准。

利用 LiteRT 和 NPU 构建实用的设备端 AI
了解行业领先企业如何使用 LiteRT 和 NPU 构建高性能的实际设备端 AI 应用。
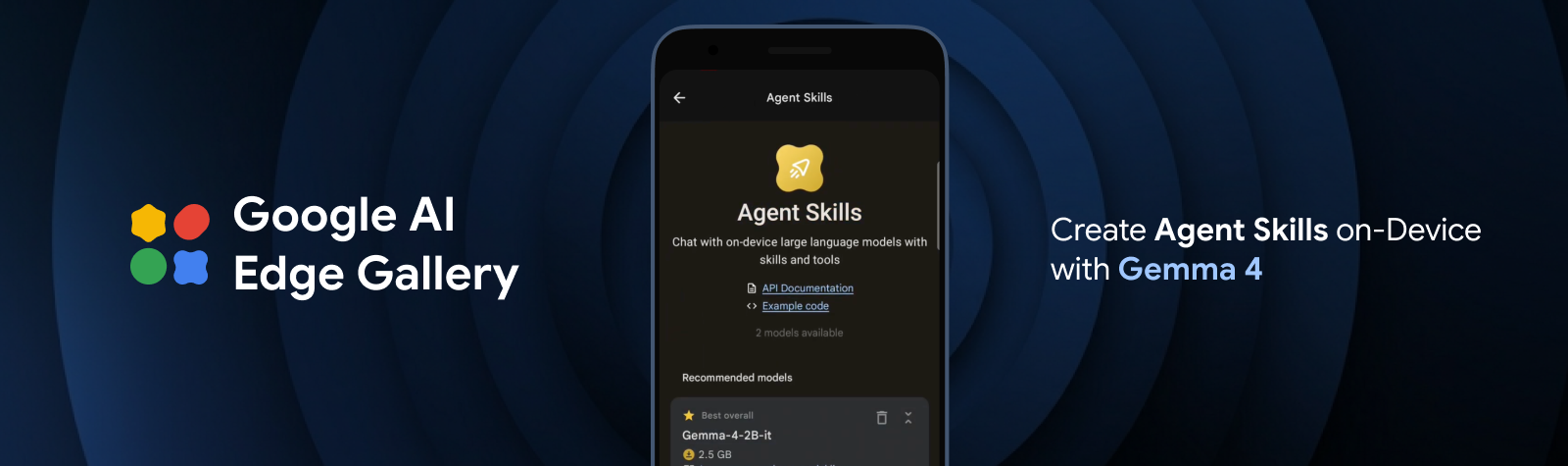
借助 Gemma 4,在边缘设备上实现先进的智能体技能
借助全新的 Gemma 4 系列和 LiteRT,完全在设备上部署智能体和多步规划功能。

LiteRT:适用于设备端 AI 的通用框架
Google 的统一设备端机器学习框架,从 TFLite 演变而来,可实现高性能部署。
MediaTek NPU 和 LiteRT:为下一代设备端 AI 提供支持
将 NPU 加速支持扩展到 MediaTek 芯片组,以实现高效的 AI。
利用 LiteRT 充分发挥 Qualcomm NPU 的性能
在 Qualcomm 神经处理单元上实现生成式 AI 的突破性性能。

LiteRT:最大限度提升性能,简化操作
推出 CompiledModel API,用于自动选择硬件和异步执行。
在 Chrome、Chromebook Plus 和 Pixel Watch 中使用 LiteRT-LM 实现设备端生成式 AI
使用 LiteRT-LM 在穿戴式设备和基于浏览器的平台上部署语言模型。

Google AI Edge 小语言模型、多模态和函数调用
有关边缘端语言模型的 RAG、多模态和函数调用的最新见解
加入社群
LiteRT GitHub 社区
直接为项目做出贡献,并与核心开发者协作。

Hugging Face Hub
在 Hugging Face Hub 上访问优化后的开放权重模型。