Imagen 是 Google 的高保真图片生成模型,能够根据文本提示生成逼真且高质量的图片。生成的所有图片都包含 SynthID 水印。如需详细了解可用的 Imagen 模型变体,请参阅模型版本部分。
使用 Imagen 模型生成图片
此示例演示了如何使用 Imagen 模型生成图片:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen 配置
Imagen 目前仅支持英语提示和以下参数:
numberOfImages:要生成的图片数量,范围为 1 到 4(含)。 默认值为 4。imageSize:生成的图片的大小。仅 Standard 和 Ultra 模型支持此功能。支持的值为1K和2K。 默认值为1K。aspectRatio:更改所生成图片的宽高比。支持的值包括"1:1"、"3:4"、"4:3"、"9:16"和"16:9"。默认值为"1:1"。personGeneration:允许模型生成人物图片。支持以下值:"dont_allow":禁止生成人物图片。"allow_adult":生成成人的图像,但不生成儿童的图像。这是默认值。"allow_all":生成包含成人和儿童的图片。
Imagen 提示指南
本部分 Imagen 指南介绍了修改文本转图片提示会如何产生不同的结果,并举例说明了您可以创建的图片。
提示撰写的基础知识
好的提示应具有描述性、清晰明了,并使用有意义的关键字和修饰符。首先,请考虑主题、背景和风格。

主体:对于任何提示,首先要考虑的都是主体:对象、人物、动物或场景。
背景和环境:与主体所处的背景或环境一样重要。请尝试将主体置于各种背景下。例如,白色背景、户外或室内环境下的工作室。
样式:最后,添加所需图片的样式。样式可以是常规内容(绘画、照片、草图),也可以是非常具体的内容(色粉画、木炭画、无透视三维绘图)。您还可以组合使用多种样式。
在撰写第一版提示后,请通过添加更多详细信息来优化提示,直到您获得所需的图片为止。迭代很重要。首先确定核心概念,然后在此核心概念的基础上进行优化和扩展,直到生成的图片接近您的构想为止。

|

|

|
无论您的提示是简短的还是较长且详细的,Imagen 模型都可以将您的想法转换为详细的图片。通过迭代提示和添加详细信息来优化您的构想,直到您获得理想的结果。
|
您可以使用短提示快速生成图片。 
|
您可以使用较长提示添加具体详细信息并构建图片。 
|
关于 Imagen 提示撰写的其他建议:
- 使用描述性语言:使用详细的形容词和副词,为 Imagen 描绘清晰的画面。
- 提供背景信息:根据需要,添加背景信息以帮助 AI 理解。
- 参考特定艺术家或风格:如果您有特定的审美观,参考特定艺术家或艺术运动可能会有所帮助。
- 使用提示工程工具:可考虑探索提示工程工具或资源,以帮助您优化提示并实现最佳结果。
- 增强个人和群组图片中的面部细节:指定面部细节作为照片的焦点(例如,在提示中使用“portrait”一词)。
在图片中生成文本
Imagen 模型可以在图片中添加文字,从而为创造性图片生成提供了更多可能性。请按照以下指南来充分利用此功能:
- 自信地迭代:您可能需要重新生成图片,直到实现所需的外观为止。Imagen 的文本集成仍在不断发展,有时多次尝试才能获得最佳结果。
- 简短明了:为获得最佳生成效果,请将文本长度限制在 25 个字符以内。
多个短语:尝试使用两三个不同的词组来提供更多信息。为了让组合更清晰,请避免超过三个短语。

提示:A poster with the text "Summerland" in bold font as a title, underneath this text is the slogan "Summer never felt so good" 指导放置:虽然 Imagen 可以尝试按指示放置文本,但您应该预料到偶尔会出现一些变化。此功能正在不断改进。
启发性字体样式:指定一种常规字体样式,以巧妙地影响 Imagen 的选择。不要依赖精确的字体复制,而是期待富有创意的诠释。
字体大小:指定字体大小或有关大小的一般指示(例如,小、中、大)以影响字体大小生成。
提示参数化
为了更好地控制输出结果,将发送给 Imagen 的输入参数化可能会有所帮助。例如,假设您希望客户能够为自己的企业生成徽标,并且希望确保徽标始终在纯色背景上生成。您还想限制客户端可以从菜单中选择的选项。
在此示例中,您可以创建一个类似于以下内容的参数化提示:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.在自定义界面中,客户可以使用菜单输入参数,并且他们选择的值会填充 Imagen 收到的提示。
例如:
提示:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
提示:
A modern logo for a software company on a solid color background. Include the text Silo.
提示:
A traditional logo for a baking company on a solid color background. Include the text Seed.
高级提示撰写技术
使用以下示例根据属性(例如摄影描述符、形状和材料、历史艺术运动和图像质量修饰符)创建更具体的提示。
摄影
- 提示包括:“...的照片”
如需使用此风格,请先使用关键字,明确告诉 Imagen 您所需要的是照片。提示开头是“一张. . . 的照片”。例如:

|

|

|
图片来源:每张图片都是使用相应的文本提示通过 Imagen 4 模型生成的。
摄影修饰符
在以下示例中,您可以看到多个专用于照片的修饰符和参数。您可以组合使用多个修饰符,以便更精确地控制。
相机邻近性 - 特写,从远处拍摄

提示:A close-up photo of coffee beans 
提示:A zoomed out photo of a small bag of
coffee beans in a messy kitchen相机位置 - 航拍、仰拍

提示:aerial photo of urban city with skyscrapers 
提示:A photo of a forest canopy with blue skies from below 光线 - 自然、舞台、暖、冷

提示:studio photo of a modern arm chair, natural lighting 
提示:studio photo of a modern arm chair, dramatic lighting 相机设置 - 运动模糊、柔焦、焦外成像、人像

提示:photo of a city with skyscrapers from the inside of a car with motion blur 
提示:柔焦 photograph of a bridge in an urban city at night 镜头类型 - 35 毫米、50 毫米、鱼眼、广角、微距

提示:叶子的照片,微距镜头 
提示:街道摄影、纽约市、鱼眼镜头 胶片类型 - 黑白、拍立得

提示:a polaroid portrait of a dog wearing sunglasses 
提示:black and white photo of a dog wearing sunglasses
图片来源:每张图片都是使用相应的文本提示通过 Imagen 4 模型生成的。
插图和艺术
- 提示包括:“...的 painting”、“...的 sketch”
艺术风格各不相同,从铅笔素描等单色风格到超现实的数字艺术均有。例如,以下图片使用相同提示而使用不同风格:
一辆背景是摩天大楼的棱角分明的运动型电动轿车的 [art style or creation technique]

|

|

|

|

|

|
图片来源:每张图片都是使用相应的文本提示通过 Imagen 2 模型生成的。
形状和材料
- 提示包括:“...制作的...”、“...形状的…”
这项技术的一大优势是您可以创建以其他方式难以实现或无法实现的图像。例如,您可以用不同的材料和纹理重新创建公司徽标。

|

|

|
图片来源:每张图片都是使用相应的文本提示通过 Imagen 4 模型生成的。
历史艺术参考
- 提示包括:“...风格的...”
多年来,某些风格已经成为标志。以下是一些您可以尝试的历史绘图或艺术风格想法。
“generate an image in the style of [art period or movement] : a wind farm”

|

|

|
图片来源:每张图片都是使用相应的文本提示通过 Imagen 4 模型生成的。
图片质量修饰符
某些关键字可使模型知道您正在寻找高质量的资源。质量修饰符的示例包括:
- 常规修饰符 - 高品质、精美、风格化
- 照片 - 4K、HDR、摄影棚照片
- 艺术、插图 - 由专业的、详细的
以下是几个不带质量修饰符的提示以及带有质量修饰符的相同提示的示例。

|

photo of a corn stalk taken by a professional photographer |
图片来源:每张图片都是使用相应的文本提示通过 Imagen 4 模型生成的。
宽高比
借助 Imagen 图片生成,您可以设置五种不同的图片宽高比。
- 方形(1:1,默认值)- 标准方形照片。这种宽高比的常见用途包括社交媒体帖子。
全屏 (4:3) - 这种宽高比通常用于媒体或电影。它也是大多数旧款(非宽屏)电视和中等格式相机的尺寸。它可水平拍摄更多场景(与 1:1 相比),因而成为摄影的首选宽高比。

提示:close up of a musician's fingers playing the piano, black and white film, vintage (4:3 aspect ratio) 
提示:高档餐厅的炸薯条的专业工作室照片,采用美食杂志的风格(宽高比为 4:3) 纵向全屏 (3:4) - 这是旋转 90 度的全屏宽高比。与 1:1 宽高比相比,这种宽高比可垂直拍摄更多场景。

提示:一位徒步旅行的女士,靴子的近处倒映在水坑中,背景是大山,广告风格,戏剧性的角度(宽高比为 3:4) 
提示:aerial shot of a river flowing up a mystical valley (3:4 aspect ratio) 宽屏 (16:9) - 此宽高比已取代 4:3,现在是电视、显示器和手机屏幕(横向)的最常用宽高比。如果您想拍摄更多背景(例如风景),请使用这种宽高比。

提示:a man wearing all white clothing sitting on the beach, close up, golden hour lighting (16:9 aspect ratio) 纵向 (9:16) - 这种宽高比是宽屏,但进行了旋转。这是一种相对较新的宽高比,深受短视频应用(例如 YouTube Shorts)的欢迎。可将这种宽高比用于具有强烈垂直方向的较高对象,例如建筑物、树、瀑布或其他类似对象。

提示:a digital render of a massive skyscraper, modern, grand, epic with a beautiful sunset in the background (9:16 aspect ratio)
逼真图片
图片生成模型的不同版本可以同时提供具有艺术效果的输出和逼真的输出。根据要生成的主题,在提示中使用以下措辞,以生成更逼真的输出。
| 使用场景 | 镜头类型 | 焦距 | 其他详情 |
|---|---|---|---|
| 人物(人像) | 定焦、变焦 | 24-35 毫米 | 黑白胶片、黑色电影、景深、双色调(提及两种颜色) |
| 食品、昆虫、植物(物体、静物) | 宏 | 60-105 毫米 | 高精度、精准聚焦、控制照明 |
| 体育运动、野生动物(运动) | 远摄变焦 | 100-400 毫米 | 高速快门、动作或运动追踪 |
| 天文、风光(广角) | 广角 | 10-24 毫米 | 长曝光、清晰对焦、长曝光、平滑的水或云 |
人像
| 使用场景 | 镜头类型 | 焦距 | 其他详情 |
|---|---|---|---|
| 人物(人像) | 定焦、变焦 | 24-35 毫米 | 黑白胶片、黑色电影、景深、双色调(提及两种颜色) |
使用表中的多个关键字,Imagen 可以生成以下人像图片:

|

|

|

|
提示:A woman, 35mm portrait, blue and grey duotones
模型:imagen-4.0-generate-001

|

|

|

|
提示:A woman, 35mm portrait, film noir
模型:imagen-4.0-generate-001
对象
| 使用场景 | 镜头类型 | 焦距 | 其他详情 |
|---|---|---|---|
| 食品、昆虫、植物(物体、静物) | 宏 | 60-105 毫米 | 高精度、精准聚焦、控制照明 |
使用表中的多个关键字,Imagen 可以生成以下静物图片:

|

|

|

|
提示:竹芋的叶子、微距镜头、60 毫米
模型:imagen-4.0-generate-001

|

|

|

|
提示:一盘意大利面、100 毫米微距镜头
模型:imagen-4.0-generate-001
动画
| 使用场景 | 镜头类型 | 焦距 | 其他详情 |
|---|---|---|---|
| 体育运动、野生动物(运动) | 远摄变焦 | 100-400 毫米 | 高速快门、动作或运动追踪 |
使用表中的多个关键字,Imagen 可以生成以下运动图片:

|

|
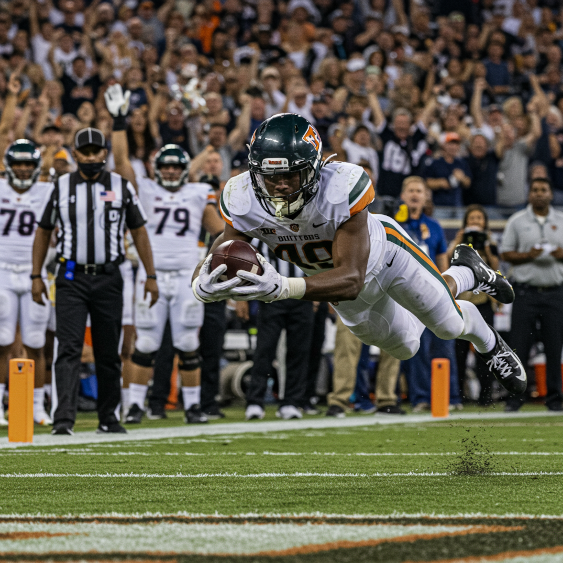
|

|
提示:a winning touchdown, fast 快门速度, movement tracking
模型:imagen-4.0-generate-001

|

|

|

|
提示:森林中奔跑的鹿、高速快门速度、运动追踪
模型:imagen-4.0-generate-001
广角
| 使用场景 | 镜头类型 | 焦距 | 其他详情 |
|---|---|---|---|
| 天文、风光(广角) | 广角 | 10-24 毫米 | 长曝光、清晰对焦、长曝光、平滑的水或云 |
使用表中的多个关键字,Imagen 可以生成以下广角图片:

|

|

|

|
提示:广阔的山脉、10 毫米风光广角
模型:imagen-4.0-generate-001

|

|

|

|
提示:月亮的照片、天文摄影、10 毫米广角
模型:imagen-4.0-generate-001