
Kuantizimi pas trajnimit është një teknikë konvertimi që mund të zvogëlojë madhësinë e modelit, ndërkohë që përmirëson edhe latencën e përshpejtuesit të CPU-së dhe harduerit, me pak përkeqësim në saktësinë e modelit. Ju mund të kuantizoni një model TensorFlow me lundrim tashmë të trajnuar kur e konvertoni atë në formatin LiteRT duke përdorur Konvertuesin LiteRT .
Metodat e Optimizimit
Ekzistojnë disa opsione kuantizimi pas trajnimit për të zgjedhur. Ja një tabelë përmbledhëse e zgjedhjeve dhe përfitimeve që ato ofrojnë:
| Teknikë | Përfitimet | Pajisje |
|---|---|---|
| Kuantizimi i diapazonit dinamik | 4 herë më i vogël, 2 herë më i shpejtë | CPU |
| Kuantizimi i plotë i numrave të plotë | 4 herë më i vogël, mbi 3 herë më i shpejtë | CPU, Edge TPU, Mikrokontrollues |
| Kuantizimi Float16 | 2 herë më i vogël, përshpejtim GPU | CPU, GPU |
Pema e mëposhtme e vendimeve mund të ndihmojë në përcaktimin se cila metodë kuantizimi pas trajnimit është më e mira për rastin tuaj të përdorimit:
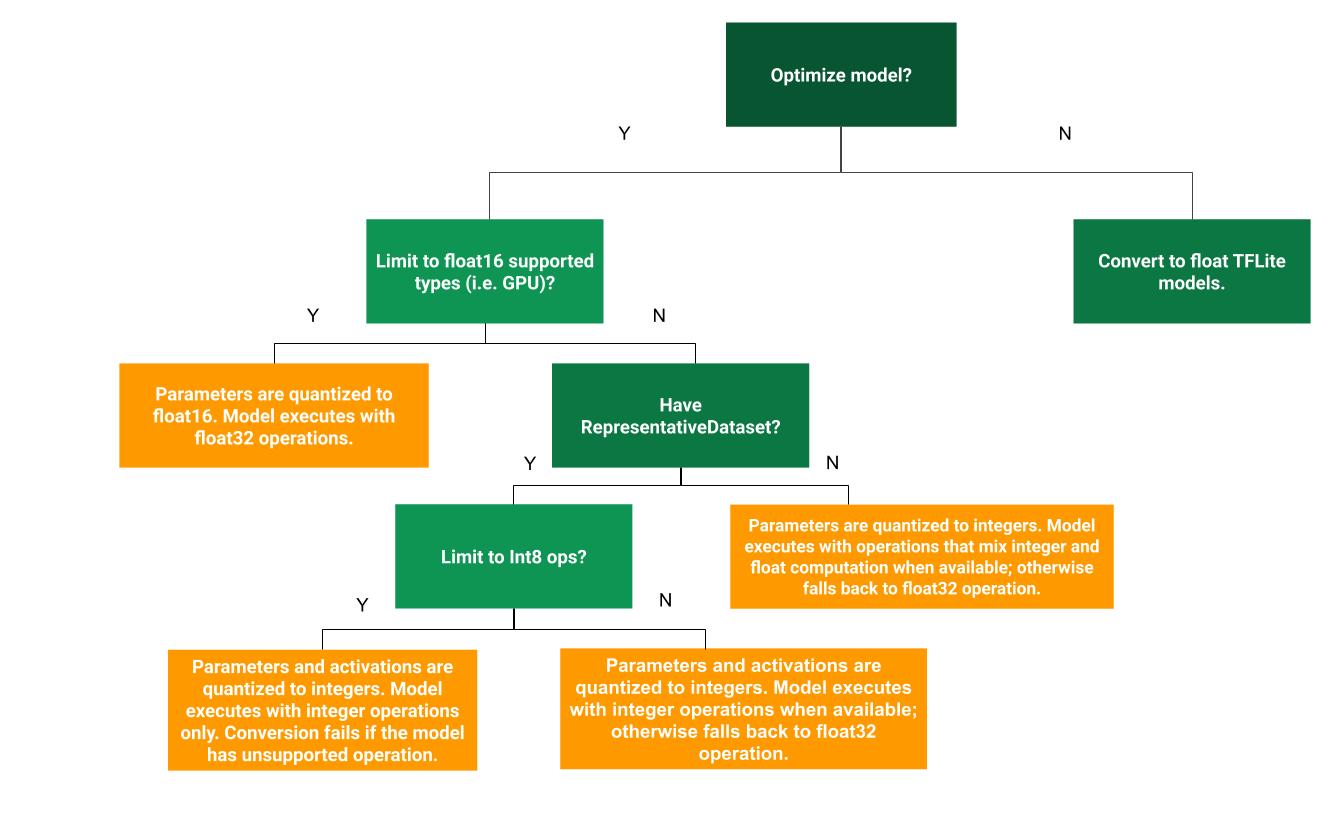
Pa kuantizim
Konvertimi në një model TFLite pa kuantizim është një pikënisje e rekomanduar. Kjo do të gjenerojë një model TFLite me funksion lundrues.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Ne ju rekomandojmë që ta bëni këtë si një hap fillestar për të verifikuar që operatorët e modelit origjinal TF janë të pajtueshëm me TFLite dhe mund të përdoren gjithashtu si një bazë për të debuguar gabimet e kuantizimit të futura nga metodat pasuese të kuantizimit pas trajnimit. Për shembull, nëse një model i kuantizuar TFLite prodhon rezultate të papritura, ndërsa modeli TFLite float është i saktë, ne mund ta ngushtojmë problemin në gabimet e futura nga versioni i kuantizuar i operatorëve TFLite.
Kuantizimi i diapazonit dinamik
Kuantizimi i diapazonit dinamik siguron përdorim të reduktuar të memories dhe llogaritje më të shpejtë pa pasur nevojë të jepni një grup të dhënash përfaqësues për kalibrim. Ky lloj kuantizimi, kuantizon statikisht vetëm peshat nga pika lundruese në numër të plotë në kohën e konvertimit, gjë që siguron saktësi 8-bitëshe:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Për të ulur më tej vonesën gjatë nxjerrjes së përfundimeve, operatorët e "diapazonit dinamik" kuantizojnë dinamikisht aktivizimet bazuar në diapazonin e tyre në 8-bit dhe kryejnë llogaritje me pesha dhe aktivizime 8-bit. Ky optimizim ofron vonesa afër nxjerrjeve të përfundimeve plotësisht me pikë fikse. Megjithatë, rezultatet ruhen ende duke përdorur pikë lundruese, kështu që shpejtësia e rritur e operacioneve me diapazon dinamik është më e vogël se një llogaritje e plotë me pikë fikse.
Kuantizimi i plotë i numrave të plotë
Mund të arrini përmirësime të mëtejshme të latencës, ulje të përdorimit maksimal të memories dhe përputhshmëri me pajisjet ose përshpejtuesit harduerikë vetëm me numra të plotë duke u siguruar që të gjitha llogaritjet e modelit janë të kuantizuara në numra të plotë.
Për kuantizim të plotë të numrave të plotë, duhet të kalibroni ose vlerësoni diapazonin, d.m.th., (min, max) të të gjithë tensorëve me pikë lundruese në model. Ndryshe nga tensorët konstantë si peshat dhe paragjykimet, tensorët variabëlë si hyrja e modelit, aktivizimet (daljet e shtresave të ndërmjetme) dhe dalja e modelit nuk mund të kalibrohen nëse nuk ekzekutojmë disa cikle inference. Si rezultat, konvertuesi kërkon një grup të dhënash përfaqësues për t'i kalibruar ato. Ky grup të dhënash mund të jetë një nëngrup i vogël (rreth ~100-500 mostra) i të dhënave të trajnimit ose validimit. Referojuni funksionit representative_dataset() më poshtë.
Nga versioni TensorFlow 2.7, mund të specifikoni të dhënat përfaqësuese përmes një nënshkrimi si shembulli i mëposhtëm:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Nëse ka më shumë se një nënshkrim në modelin e dhënë TensorFlow, mund të specifikoni të dhënat e shumëfishta duke specifikuar çelësat e nënshkrimit:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Ju mund të gjeneroni të dhënat përfaqësuese duke ofruar një listë tensorësh hyrës:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Që nga versioni TensorFlow 2.7, ne rekomandojmë përdorimin e qasjes së bazuar në nënshkrime në vend të qasjes së bazuar në listën e tenzorëve të hyrjes, sepse renditja e tenzorëve të hyrjes mund të ndryshohet lehtësisht.
Për qëllime testimi, mund të përdorni një grup të dhënash artificial si më poshtë:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Numër i plotë me rezervë me vlerë notuese (duke përdorur hyrjen/daljen e parazgjedhur me vlerë notuese)
Për të kuantizuar plotësisht një model me numër të plotë, por për të përdorur operatorë notues kur ata nuk kanë një implementim të numrit të plotë (për të siguruar që konvertimi të ndodhë pa probleme), përdorni hapat e mëposhtëm:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Vetëm numër i plotë
Krijimi i modeleve vetëm me numra të plotë është një rast i zakonshëm përdorimi për LiteRT për mikrokontrolluesit dhe TPU-të Coral Edge .
Për më tepër, për të siguruar përputhshmëri me pajisjet vetëm me numra të plotë (siç janë mikrokontrolluesit 8-bitësh) dhe përshpejtuesit (siç është Coral Edge TPU), mund të zbatoni kuantizimin e plotë të numrave të plotë për të gjitha operacionet, përfshirë hyrjen dhe daljen, duke përdorur hapat e mëposhtëm:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Kuantizimi Float16
Mund ta zvogëloni madhësinë e një modeli me pikë lundruese duke kuantizuar peshat në float16, standardi IEEE për numrat me pikë lundruese 16-bitëshe. Për të aktivizuar kuantizimin e peshave me float16, përdorni hapat e mëposhtëm:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Përparësitë e kuantizimit float16 janë si më poshtë:
- Zvogëlon madhësinë e modelit deri në gjysmën (meqenëse të gjitha peshat bëhen gjysma e madhësisë së tyre origjinale).
- Shkakton humbje minimale të saktësisë.
- Mbështet disa delegatë (p.sh. delegati i GPU-së) të cilët mund të veprojnë drejtpërdrejt në të dhënat float16, duke rezultuar në ekzekutim më të shpejtë sesa llogaritjet float32.
Disavantazhet e kuantizimit float16 janë si më poshtë:
- Nuk e zvogëlon latencën aq sa një kuantizim në matematikën e pikës fikse.
- Si parazgjedhje, një model i kuantizuar float16 do t'i "dekuantizojë" vlerat e peshave në float32 kur ekzekutohet në CPU. (Vini re se delegati i GPU-së nuk do ta kryejë këtë dekuantizim, pasi mund të funksionojë me të dhëna float16.)
Vetëm numër i plotë: aktivizime 16-bitëshe me pesha 8-bitëshe (eksperimentale)
Kjo është një skemë kuantizimi eksperimental. Është e ngjashme me skemën "vetëm numër i plotë", por aktivizimet kuantizohen bazuar në diapazonin e tyre deri në 16-bit, peshat kuantizohen në numër të plotë 8-bit dhe polarizimi kuantizohet në numër të plotë 64-bit. Kjo quhet më tej kuantizim 16x8.
Avantazhi kryesor i këtij kuantizimi është se mund të përmirësojë ndjeshëm saktësinë, por vetëm paksa të rrisë madhësinë e modelit.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Nëse kuantizimi 16x8 nuk mbështetet për disa operatorë në model, atëherë modeli mund të kuantizohet ende, por operatorët e pambështetur mbahen në gjendje pezull. Opsioni i mëposhtëm duhet të shtohet në target_spec për ta lejuar këtë.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Shembuj të rasteve të përdorimit ku përmirësimet e saktësisë të ofruara nga kjo skemë kuantizimi përfshijnë:
- super-rezolucion,
- përpunimi i sinjalit audio siç është anulimi i zhurmës dhe formimi i rrezes,
- heqja e zhurmës së imazhit,
- Rindërtimi HDR nga një imazh i vetëm.
Disavantazhi i këtij kuantizimi është:
- Aktualisht, përfundimi është dukshëm më i ngadaltë se numri i plotë 8-bit për shkak të mungesës së implementimit të optimizuar të kernelit.
- Aktualisht është i papajtueshëm me delegatët ekzistues TFLite të përshpejtuar nga hardueri.
Një tutorial për këtë modalitet kuantizimi mund të gjendet këtu .
Saktësia e modelit
Meqenëse peshat kuantizohen pas trajnimit, mund të ketë një humbje të saktësisë, veçanërisht për rrjetet më të vogla. Modele të kuantizuara plotësisht të para-trajnuara ofrohen për rrjete specifike në Modelet Kaggle . Është e rëndësishme të kontrollohet saktësia e modelit të kuantizuar për të verifikuar që çdo degradim në saktësi është brenda kufijve të pranueshëm. Ekzistojnë mjete për të vlerësuar saktësinë e modelit LiteRT .
Si alternativë, nëse rënia e saktësisë është shumë e lartë, merrni në konsideratë përdorimin e trajnimit të vetëdijshëm për kuantizimin . Megjithatë, kjo kërkon modifikime gjatë trajnimit të modelit për të shtuar nyje të rreme kuantizimi, ndërsa teknikat e kuantizimit pas trajnimit në këtë faqe përdorin një model ekzistues të para-trajnuar.
Përfaqësimi për tenzorët e kuantizuar
Kuantizimi 8-bitësh i përafron vlerat me pikë lundruese duke përdorur formulën e mëposhtme.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Përfaqësimi ka dy pjesë kryesore:
Peshat për bosht (të njohura edhe si për kanal) ose për tensor të përfaqësuara nga vlerat e komplementit të int8 me dy në diapazonin [-127, 127] me pikë zero të barabartë me 0.
Aktivizimet/hyrjet për tensor të përfaqësuara nga vlerat e komplementit të int8 me dy në diapazonin [-128, 127], me një pikë zero në diapazonin [-128, 127].
Për një pamje të detajuar të skemës sonë të kuantizimit, ju lutemi shihni specifikimet tona të kuantizimit . Shitësit e pajisjeve që duan të lidhen me ndërfaqen e delegatëve të TensorFlow Lite inkurajohen të zbatojnë skemën e kuantizimit të përshkruar atje.