
Mjetet e referencës LiteRT matin dhe llogaritin statistikat për metrikat e mëposhtme të rëndësishme të performancës:
- Koha e inicializimit
- Koha e nxjerrjes së gjendjes së ngrohjes
- Koha e nxjerrjes së përfundimit të gjendjes së qëndrueshme
- Përdorimi i memories gjatë kohës së inicializimit
- Përdorimi i përgjithshëm i memories
Mjetet e krahasimit janë të disponueshme si aplikacione krahasimi për Android dhe iOS dhe si skedarë binare të parapërgatitur të linjës së komandës, dhe të gjitha ndajnë të njëjtën logjikë kryesore të matjes së performancës. Vini re se opsionet dhe formatet e daljes në dispozicion janë paksa të ndryshme për shkak të ndryshimeve në mjedisin e ekzekutimit.
Aplikacioni i referencës për Android
Gjithashtu ofrohet një aplikacion për testimin e benchmark-ut për Android bazuar në API-në v1 Interpreter. Ky është një matës më i mirë se si do të performonte modeli në një aplikacion Android. Numrat nga mjeti i testimit të benchmark-ut do të ndryshojnë pak nga kur ekzekutohet inferenca me modelin në aplikacionin aktual.
Ky aplikacion për testimin e performancës Android nuk ka ndërfaqe përdoruesi. Instalojeni dhe ekzekutojeni duke përdorur komandën adb dhe merrni rezultatet duke përdorur komandën adb logcat .
Shkarkoni ose ndërtoni aplikacionin
Shkarkoni aplikacionet e parapërgatitura të testimit për Android çdo natë duke përdorur lidhjet e mëposhtme:
Sa i përket aplikacioneve të testimit Android që mbështesin operacionet TF nëpërmjet delegatit Flex , përdorni lidhjet më poshtë:
Mund ta ndërtoni aplikacionin edhe nga burimi duke ndjekur këto udhëzime .
Përgatitni pikën referuese
Para se të ekzekutoni aplikacionin e krahasimit, instaloni aplikacionin dhe shkarkoni skedarin e modelit në pajisje si më poshtë:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Ekzekutoni pikën referuese
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph është një parametër i kërkuar.
-
graph:string
Shtegu për në skedarin e modelit TFLite.
Mund të specifikoni më shumë parametra opsionalë për ekzekutimin e pikës referuese.
-
num_threads:int(parazgjedhur=1)
Numri i fijeve që do të përdoren për ekzekutimin e interpretuesit TFLite. -
use_gpu:bool(parazgjedhur=e gabuar)
Përdorni delegatin e GPU-së . -
use_xnnpack:bool(parazgjedhur =false)
Përdorni delegatin XNNPACK .
Në varësi të pajisjes që po përdorni, disa nga këto opsione mund të mos jenë të disponueshme ose të mos kenë efekt. Referojuni parametrave për më shumë parametra të performancës që mund të ekzekutoni me aplikacionin e testimit të performancës.
Shikoni rezultatet duke përdorur komandën logcat :
adb logcat | grep "Inference timings"
Rezultatet e krahasimit raportohen si më poshtë:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Aplikacioni i krahasimit iOS
Për të ekzekutuar teste standarde në një pajisje iOS, duhet ta ndërtoni aplikacionin nga burimi . Vendosni skedarin e modelit LiteRT në direktorinë benchmark_data të pemës burimore dhe modifikoni skedarin benchmark_params.json . Këto skedarë paketohen në aplikacion dhe aplikacioni lexon të dhëna nga direktoria. Vizitoni aplikacionin e testeve standarde iOS për udhëzime të hollësishme.
Standardet e performancës për modelet e njohura
Ky seksion rendit standardet e performancës së LiteRT kur ekzekutohen modele të njohura në disa pajisje Android dhe iOS.
Standardet e performancës së Android
Këta numra të pikës së referencës së performancës u gjeneruan me skedarin binar të pikës së referencës vendase .
Për testet e Android, afiniteti i CPU-së është vendosur të përdorë bërthama të mëdha në pajisje për të zvogëluar variancën (shih detajet ).
Supozon se modelet janë shkarkuar dhe ç'zipuar në direktorinë /data/local/tmp/tflite_models . Skedari binar i referencës ndërtohet duke përdorur këto udhëzime dhe supozohet të jetë në direktorinë /data/local/tmp .
Për të ekzekutuar pikën referuese:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Për të ekzekutuar me delegatin e GPU-së, vendosni --use_gpu=true .
Vlerat e performancës më poshtë janë matur në Android 10.
| Emri i modelit | Pajisja | CPU, 4 fije | GPU |
|---|---|---|---|
| Mobilenet_1.0_224 (notues) | Pixel 3 | 23.9 ms | 6.45 ms |
| Pixel 4 | 14.0 ms | 9.0 ms | |
| Mobilenet_1.0_224 (sasi) | Pixel 3 | 13.4 ms | --- |
| Pixel 4 | 5.0 ms | --- | |
| NASNet celular | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34.5 ms | --- | |
| SqueezeNet | Pixel 3 | 35.8 ms | 9.5 ms |
| Pixel 4 | 23.9 ms | 11.1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99.8 ms |
| Pixel 4 | 272.6 ms | 87.2 ms | |
| Fillimi_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324.1 ms | 97.6 ms |
Standardet e performancës së iOS
Këto numra të performancës së testimit u gjeneruan me aplikacionin e testimit të performancës iOS .
Për të ekzekutuar testet e referencës për iOS, aplikacioni i testit të referencës u modifikua për të përfshirë modelin e duhur dhe benchmark_params.json u modifikua për të vendosur num_threads në 2. Për të përdorur delegatin e GPU-së, në benchmark_params.json u shtuan edhe opsionet "use_gpu" : "1" dhe "gpu_wait_type" : "aggressive" .
| Emri i modelit | Pajisja | CPU, 2 fije | GPU |
|---|---|---|---|
| Mobilenet_1.0_224 (notues) | iPhone XS | 14.8 ms | 3.4 ms |
| Mobilenet_1.0_224 (sasi) | iPhone XS | 11 ms | --- |
| NASNet celular | iPhone XS | 30.4 ms | --- |
| SqueezeNet | iPhone XS | 21.1 ms | 15.5 ms |
| Inception_ResNet_V2 | iPhone XS | 261.1 ms | 45.7 ms |
| Fillimi_V4 | iPhone XS | 309 ms | 54.4 ms |
Pjesët e brendshme të Trace LiteRT
Gjurmoni pjesët e brendshme të LiteRT në Android
Ngjarjet e brendshme nga interpretuesi LiteRT i një aplikacioni Android mund të kapen nga mjetet e gjurmimit të Android . Ato janë të njëjtat ngjarje me API-në Android Trace , kështu që ngjarjet e kapura nga kodi Java/Kotlin shihen së bashku me ngjarjet e brendshme të LiteRT.
Disa shembuj të ngjarjeve janë:
- Thirrja e operatorit
- Modifikimi i grafikut nga delegatët
- Alokimi i tensorit
Midis opsioneve të ndryshme për kapjen e gjurmëve, ky udhëzues mbulon Android Studio CPU Profiler dhe aplikacionin System Tracing. Referojuni mjetit të komandës Perfetto ose mjetit të komandës Systrace për opsione të tjera.
Shtimi i ngjarjeve të gjurmimit në kodin Java
Ky është një fragment kodi nga aplikacioni shembull i Klasifikimit të Imazheve . Interpretuesi LiteRT ekzekutohet në seksionin recognizeImage/runInference . Ky hap është opsional, por është i dobishëm për të ndihmuar në vërejtjen se ku bëhet thirrja e inferencës.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Aktivizo gjurmimin e LiteRT
Për të aktivizuar gjurmimin LiteRT, caktoni veçorinë e sistemit Android debug.tflite.trace në 1 përpara se të nisni aplikacionin Android.
adb shell setprop debug.tflite.trace 1
Nëse kjo veti është vendosur kur inicializohet interpretuesi LiteRT, ngjarjet kryesore (p.sh., thirrja e operatorit) nga interpretuesi do të gjurmohen.
Pasi të keni kapur të gjitha gjurmët, çaktivizoni gjurmimin duke vendosur vlerën e vetisë në 0.
adb shell setprop debug.tflite.trace 0
Profilizuesi i CPU-së i Android Studio
Kapni gjurmët me Android Studio CPU Profiler duke ndjekur hapat më poshtë:
Zgjidhni Ekzekuto > Profili 'app' nga menytë kryesore.
Klikoni kudo në vijën kohore të CPU-së kur të shfaqet dritarja e Profiler-it.
Zgjidhni 'Gjurmimi i Thirrjeve të Sistemit' midis modaliteteve të Profilizimit të CPU-së.
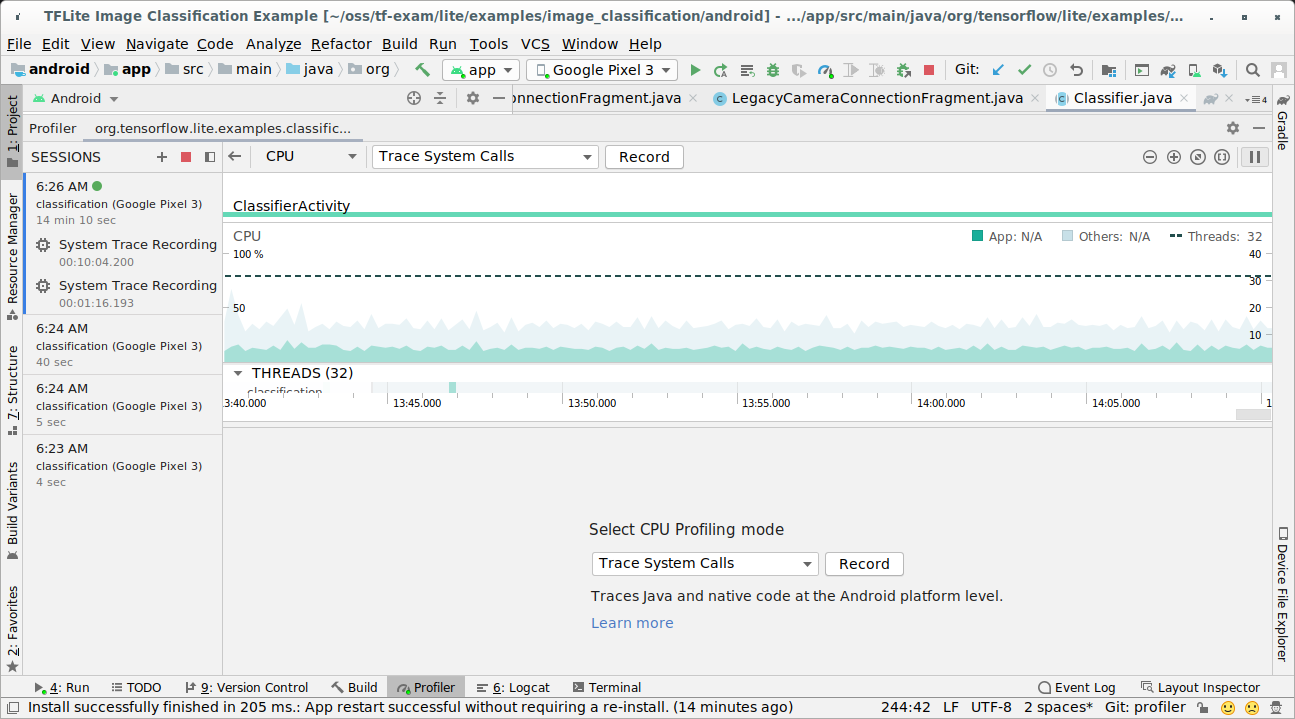
Shtypni butonin 'Regjistro'.
Shtypni butonin 'Ndalo'.
Hetoni rezultatin e gjurmës.
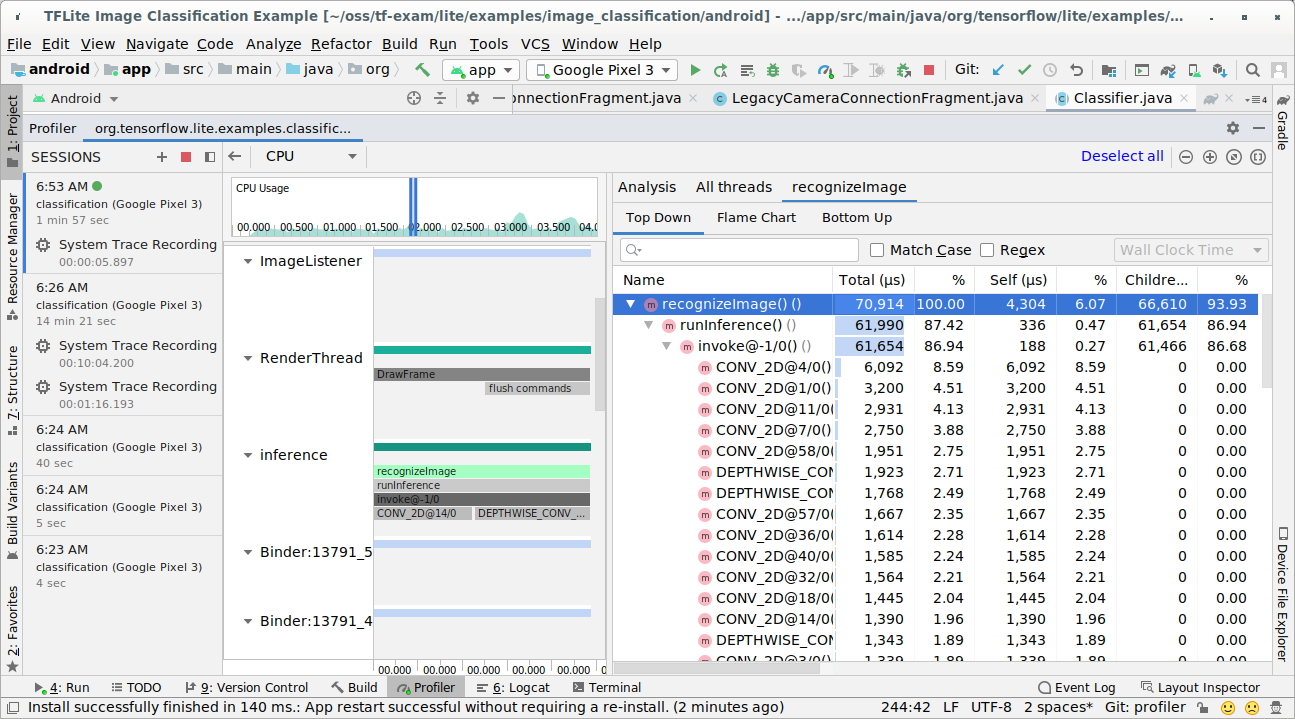
Në këtë shembull, mund të shihni hierarkinë e ngjarjeve në një fije pune dhe statistikat për çdo kohë të operatorit dhe gjithashtu të shihni rrjedhën e të dhënave të të gjithë aplikacionit midis fijeve pune.
Aplikacioni i Gjurmimit të Sistemit
Kapni gjurmët pa Android Studio duke ndjekur hapat e detajuar në aplikacionin System Tracing .
Në këtë shembull, të njëjtat ngjarje TFLite u kapën dhe u ruajtën në formatin Perfetto ose Systrace në varësi të versionit të pajisjes Android. Skedarët e gjurmimit të kapura mund të hapen në ndërfaqen e përdoruesit Perfetto .
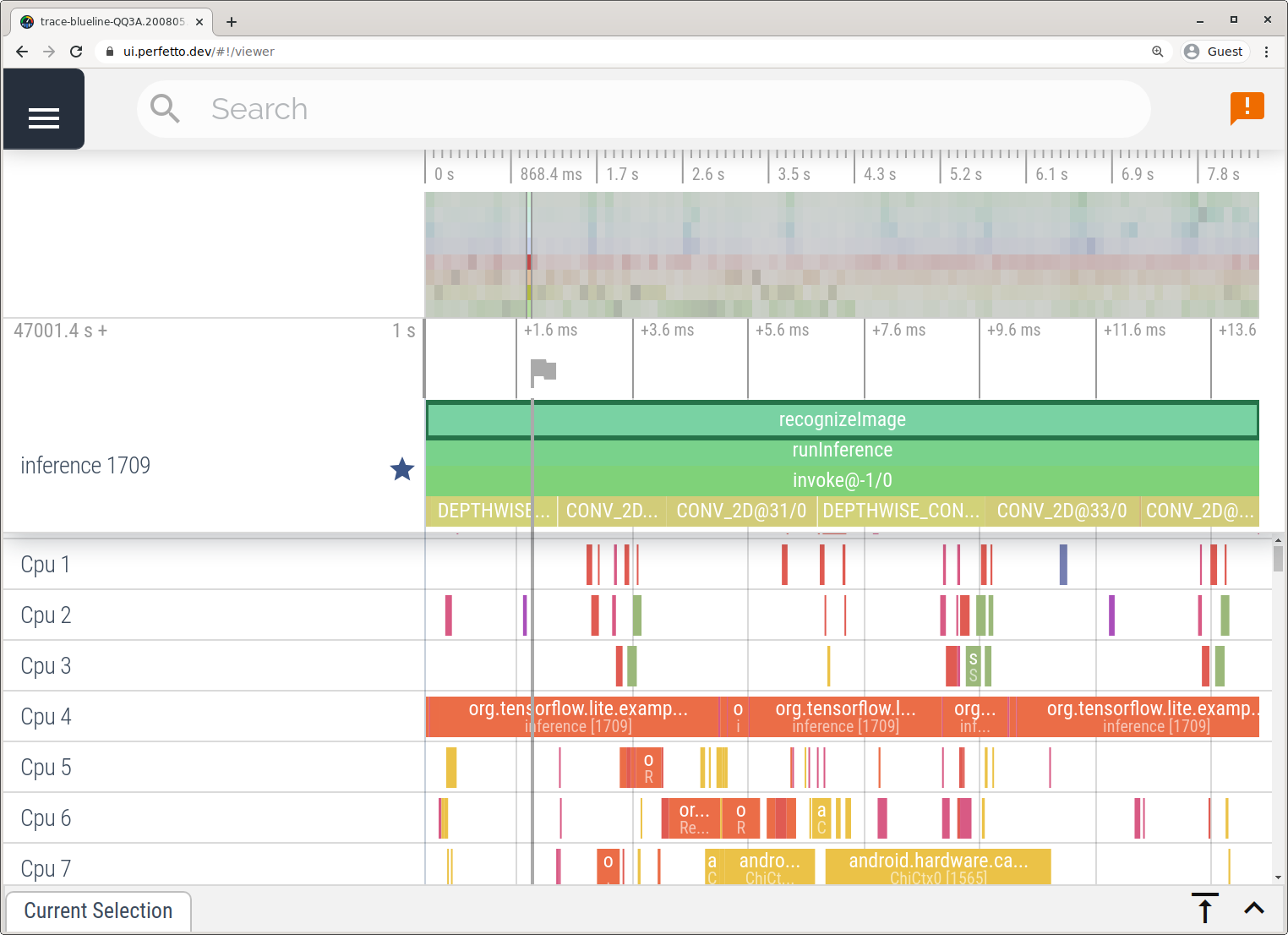
Gjurmimi i pjesëve të brendshme të LiteRT në iOS
Ngjarjet e brendshme nga interpretuesi LiteRT i një aplikacioni iOS mund të kapen nga mjeti Instruments i përfshirë me Xcode. Ato janë ngjarjet sinjalizuese të iOS, kështu që ngjarjet e kapura nga kodi Swift/Objective-C shihen së bashku me ngjarjet e brendshme të LiteRT.
Disa shembuj të ngjarjeve janë:
- Thirrja e operatorit
- Modifikimi i grafikut nga delegatët
- Alokimi i tensorit
Aktivizo gjurmimin e LiteRT
Vendosni variablin e mjedisit debug.tflite.trace duke ndjekur hapat më poshtë:
Zgjidhni Produkt > Skemë > Modifiko Skemën... nga menutë kryesore të Xcode.
Klikoni 'Profili' në panelin e majtë.
Hiqni zgjedhjen nga kutia e kontrollit 'Përdor argumentet dhe variablat e mjedisit të veprimit Ekzekuto'.
Shto
debug.tflite.tracenën seksionin 'Variablat e Mjedisit'.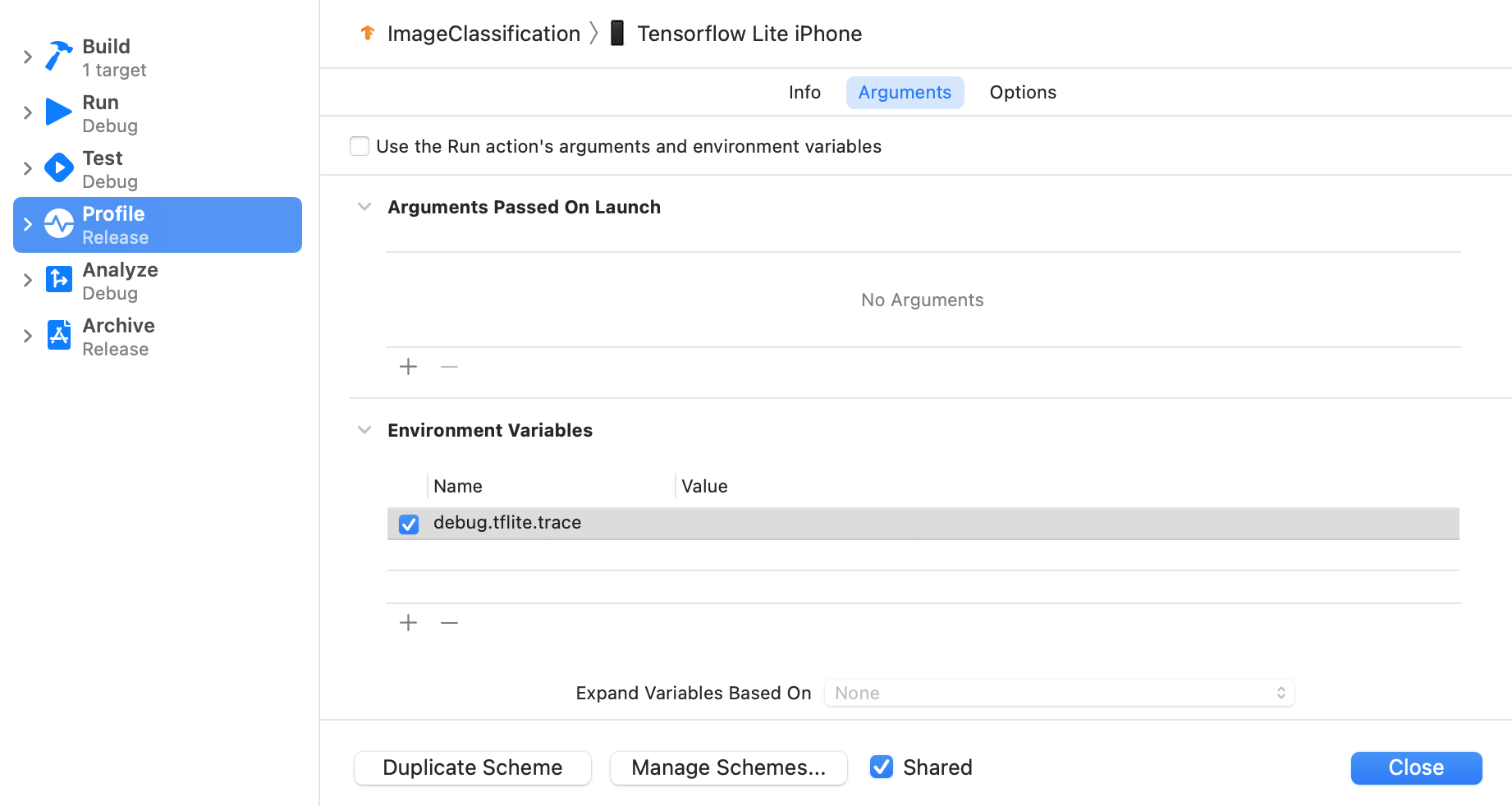
Nëse doni të përjashtoni ngjarjet LiteRT kur profilizoni aplikacionin iOS, çaktivizoni gjurmimin duke hequr variablin e mjedisit.
Instrumentet XCode
Kapni gjurmët duke ndjekur hapat më poshtë:
Zgjidhni Produkt > Profil nga menutë kryesore të Xcode.
Klikoni te Regjistrimi midis shablloneve të profilizimit kur të hapet mjeti Instrumente.
Shtypni butonin 'Fillimi'.
Shtypni butonin 'Ndalo'.
Klikoni 'os_signpost' për të zgjeruar artikujt e nënsistemit të Regjistrimit të Sistemit Operativ.
Klikoni nënsistemin e regjistrimit të sistemit operativ 'org.tensorflow.lite'.
Hetoni rezultatin e gjurmës.
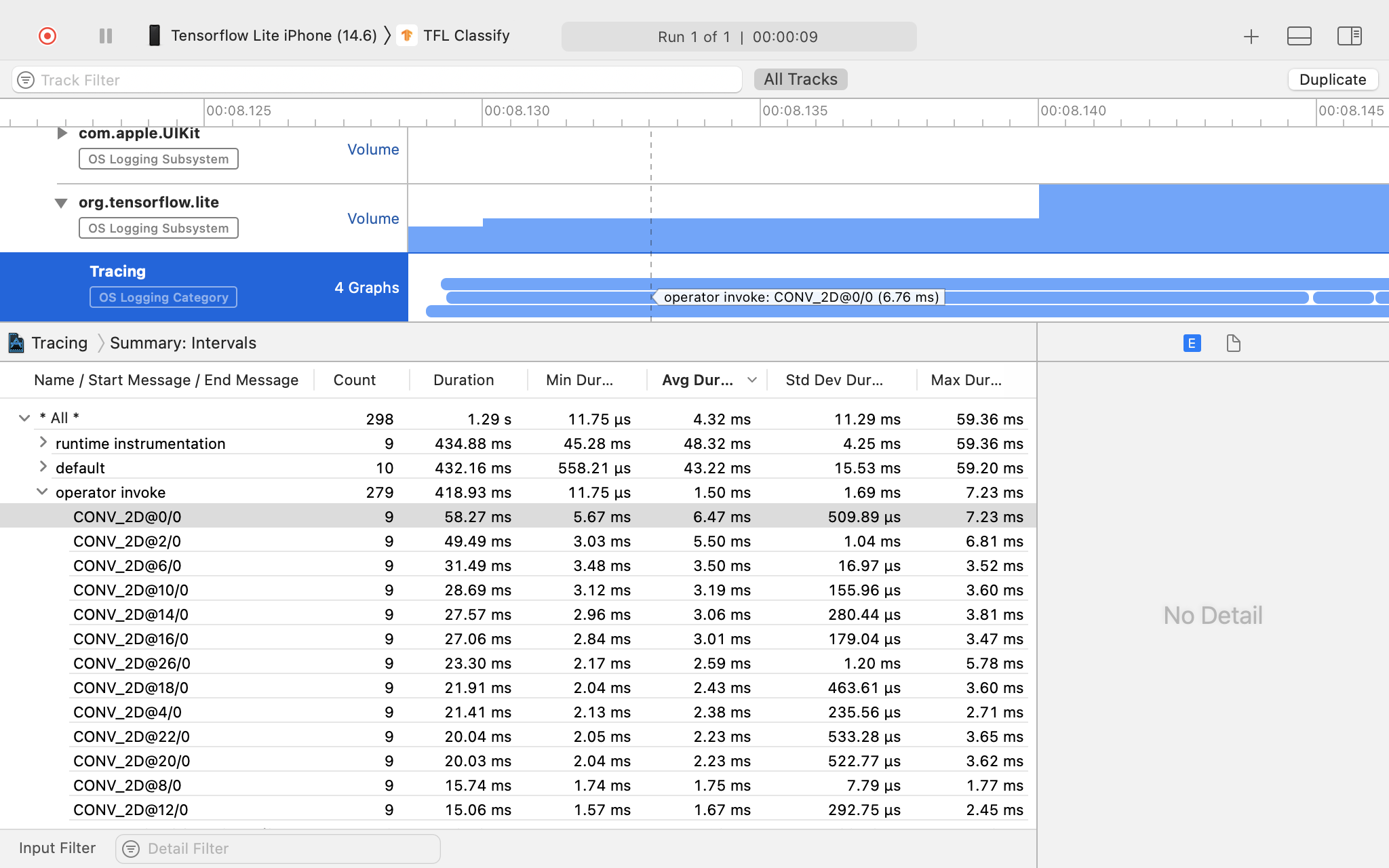
Në këtë shembull, mund të shihni hierarkinë e ngjarjeve dhe statistikave për çdo kohë të operatorit.
Duke përdorur të dhënat e gjurmimit
Të dhënat e gjurmimit ju lejojnë të identifikoni pengesat e performancës.
Ja disa shembuj të njohurive që mund të merrni nga profilizuesi dhe zgjidhjeve të mundshme për të përmirësuar performancën:
- Nëse numri i bërthamave të disponueshme të CPU-së është më i vogël se numri i fijeve të nxjerrjes së përfundimit, atëherë mbingarkesa e planifikimit të CPU-së mund të çojë në performancë nën nivelin e duhur. Ju mund të riplanifikoni detyra të tjera që kërkojnë shumë CPU në aplikacionin tuaj për të shmangur mbivendosjen me nxjerrjen e përfundimit të modelit tuaj ose për të ndryshuar numrin e fijeve të interpretuesit.
- Nëse operatorët nuk delegohen plotësisht, atëherë disa pjesë të grafikut të modelit ekzekutohen në CPU në vend të përshpejtuesit të pritur të harduerit. Mund t'i zëvendësoni operatorët e pambështetur me operatorë të ngjashëm të mbështetur.