
Metadane LiteRT zapewniają standard opisów modeli. Metadane są ważnym źródłem informacji o tym, co robi model, oraz o jego danych wejściowych i wyjściowych. Metadane składają się z tych elementów:
- czytelne dla człowieka fragmenty, które przekazują sprawdzone metody korzystania z modelu,
- części odczytywane przez maszyny, które mogą być wykorzystywane przez generatory kodu, takie jak generator kodu LiteRT na Androida i funkcja powiązań ML w Android Studio.
Wszystkie modele obrazów opublikowane na Kaggle Models zawierają metadane.
Model z formatem metadanych
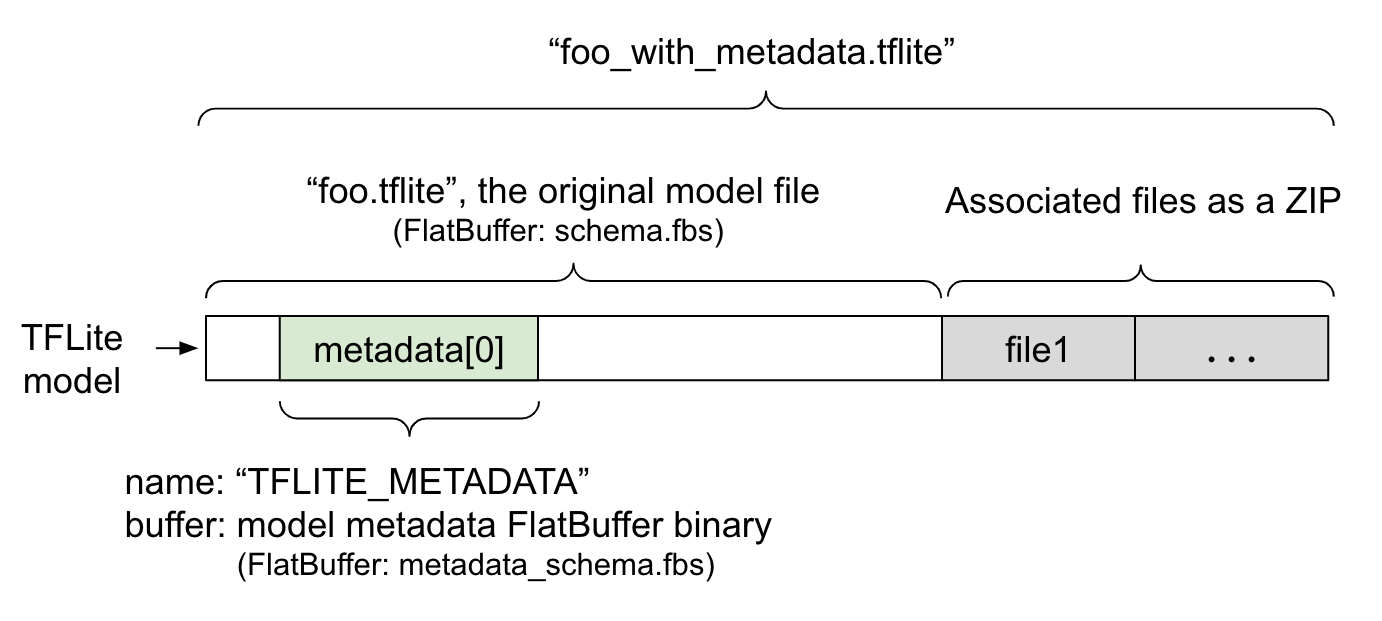
Metadane modelu są zdefiniowane w pliku metadata_schema.fbs, który jest plikiem FlatBuffer. Jak pokazano na rysunku 1, jest on przechowywany w polu metadata schematu modelu TFLite pod nazwą "TFLITE_METADATA". Niektóre modele mogą zawierać powiązane pliki, takie jak pliki etykiet klasyfikacji.
Te pliki są dołączane na końcu oryginalnego pliku modelu jako plik ZIP za pomocą trybu „append” ('a') w klasie ZipFile. Interpreter TFLite może używać nowego formatu pliku w taki sam sposób jak wcześniej. Więcej informacji znajdziesz w artykule Pakowanie powiązanych plików.
Poniżej znajdziesz instrukcje dotyczące wypełniania, wizualizowania i odczytywania metadanych.
Konfigurowanie narzędzi do metadanych
Zanim dodasz metadane do modelu, musisz skonfigurować środowisko programowania w Pythonie do uruchamiania TensorFlow. Szczegółowy przewodnik dotyczący konfiguracji znajdziesz tutaj.
Po skonfigurowaniu środowiska programowania w Pythonie musisz zainstalować dodatkowe narzędzia:
pip install tflite-support
Narzędzia do metadanych LiteRT obsługują język Python 3.
Dodawanie metadanych za pomocą interfejsu Flatbuffers Python API
Metadane modelu w schemacie składają się z 3 części:
- Informacje o modelu – ogólny opis modelu oraz elementy takie jak warunki licencji. Zobacz ModelMetadata. 2. Informacje wejściowe – opis danych wejściowych i wymagane przetwarzanie wstępne, np. normalizacja. Zobacz SubGraphMetadata.input_tensor_metadata. 3. Informacje o danych wyjściowych – opis danych wyjściowych i wymagane przetwarzanie końcowe, np. mapowanie na etykiety. Zobacz SubGraphMetadata.output_tensor_metadata.
Ponieważ LiteRT obsługuje obecnie tylko pojedynczy podgraf, generator kodu LiteRT i funkcja ML Binding w Android Studio będą używać symboli ModelMetadata.name i ModelMetadata.description zamiast SubGraphMetadata.name i SubGraphMetadata.description podczas wyświetlania metadanych i generowania kodu.
Obsługiwane typy wejść i wyjść
Metadane LiteRT dla danych wejściowych i wyjściowych nie są projektowane z myślą o konkretnych typach modeli, ale o typach danych wejściowych i wyjściowych. Nie ma znaczenia, co robi model, o ile typy danych wejściowych i wyjściowych składają się z tych typów lub ich kombinacji. W takim przypadku metadane TensorFlow Lite są obsługiwane:
- Cechy – liczby, które są niepodpisanymi liczbami całkowitymi lub liczbami zmiennoprzecinkowymi 32-bitowymi.
- Obraz – metadane obsługują obecnie obrazy RGB i w skali szarości.
- Ramka ograniczająca – ramki ograniczające w kształcie prostokąta. Schemat obsługuje różne schematy numerowania.
Pakowanie powiązanych plików
Modele LiteRT mogą mieć różne powiązane pliki. Na przykład modele języka naturalnego mają zwykle pliki słownictwa, które mapują części słów na identyfikatory słów, a modele klasyfikacji mogą mieć pliki etykiet wskazujące kategorie obiektów. Bez powiązanych plików (jeśli takie istnieją) model nie będzie działać prawidłowo.
Powiązane pliki można teraz dołączyć do modelu za pomocą biblioteki metadanych w Pythonie. Nowy model LiteRT staje się plikiem ZIP, który zawiera zarówno model, jak i powiązane z nim pliki. Można go rozpakować za pomocą popularnych narzędzi do obsługi plików ZIP. Ten nowy format modelu nadal używa tego samego rozszerzenia pliku, .tflite. Jest on zgodny z obecną strukturą TFLite i interpreterem. Więcej informacji znajdziesz w artykule Pakowanie metadanych i powiązanych plików w modelu.
Informacje o powiązanym pliku można zapisać w metadanych. W zależności od typu pliku i miejsca, do którego jest on dołączony (np. ModelMetadata, SubGraphMetadata i TensorMetadata), generator kodu LiteRT na Androida może automatycznie zastosować odpowiednie przetwarzanie wstępne lub końcowe do obiektu. Więcej informacji znajdziesz w sekcji <Codegen usage> w każdym typie powiązanego pliku w schemacie.
Parametry normalizacji i kwantyzacji
Normalizacja to popularna technika wstępnego przetwarzania danych w systemach uczących się. Celem normalizacji jest przekształcenie wartości do wspólnej skali bez zniekształcania różnic w zakresach wartości.
Kwantyzacja modelu to technika, która umożliwia zmniejszenie precyzji reprezentacji wag i opcjonalnie aktywacji na potrzeby przechowywania i obliczeń.
W przypadku przetwarzania wstępnego i końcowego normalizacja i kwantyzacja to 2 niezależne kroki. Oto szczegóły:
| Normalizacja | Kwantyzacja | |
|---|---|---|
Przykładowe wartości parametrów obrazu wejściowego w modelu MobileNet dla modeli zmiennoprzecinkowych i skwantyzowanych. |
Model zmiennoprzecinkowy: - średnia: 127,5 - odchylenie standardowe: 127,5 Model kwantowy: - średnia: 127,5 - odchylenie standardowe: 127,5 |
Model zmiennoprzecinkowy: - zeroPoint: 0 - scale: 1.0 Model kwantowy: - zeroPoint: 128.0 - scale:0.0078125f |
Kiedy wywołać? |
Dane wejściowe: jeśli dane wejściowe są normalizowane podczas trenowania, dane wejściowe wnioskowania muszą być odpowiednio znormalizowane. Dane wyjściowe: dane wyjściowe nie będą na ogół normalizowane. |
Modele zmiennoprzecinkowe nie wymagają kwantyzacji. Skwantowany model może wymagać kwantyzacji w procesie wstępnym lub końcowym, ale nie musi. Zależy to od typu danych tensorów wejściowych i wyjściowych. - tensory zmiennoprzecinkowe: nie jest wymagana kwantyzacja w ramach przetwarzania wstępnego ani końcowego. Operacje kwantyzacji i dekwantyzacji są wbudowane w graf modelu. - tensory int8/uint8: wymagają kwantyzacji w przetwarzaniu wstępnym/końcowym. |
Formuła |
normalized_input = (input - mean) / std |
Kwantyzacja danych wejściowych:
q = f / scale + zeroPoint Dequantize for outputs: f = (q - zeroPoint) * scale |
Gdzie znajdują się parametry |
Wypełnione przez twórcę modelu i przechowywane w metadanych modelu jakoNormalizationOptions |
Wypełniane automatycznie przez konwerter TFLite i przechowywane w pliku modelu TFLite. |
| Jak uzyskać parametry? | Za pomocą interfejsu API MetadataExtractor[2]
|
Za pomocą interfejsu TFLite
Tensor API [1] lub
za pomocą interfejsu
MetadataExtractor API
[2] |
| Czy modele zmiennoprzecinkowe i kwantowe mają tę samą wartość? | Tak, modele zmiennoprzecinkowe i skwantyzowane mają te same parametry normalizacji. | Nie, model zmiennoprzecinkowy nie wymaga kwantyzacji. |
| Czy generator kodu TFLite lub powiązanie Android Studio ML automatycznie generuje go podczas przetwarzania danych? | Tak |
Tak |
[1] LiteRT Java API i LiteRT C++ API.
[2] Biblioteka do wyodrębniania metadanych
Podczas przetwarzania danych obrazu na potrzeby modeli uint8 normalizacja i kwantyzacja są czasami pomijane. Można to zrobić, gdy wartości pikseli mieszczą się w zakresie [0, 255]. Ogólnie jednak zawsze należy przetwarzać dane zgodnie z parametrami normalizacji i kwantyzacji, jeśli ma to zastosowanie.
Przykłady
Przykłady wypełniania metadanych w przypadku różnych typów modeli znajdziesz tutaj:
Klasyfikacja obrazów
Pobierz skrypt tutaj, który wypełnia metadane w pliku mobilenet_v1_0.75_160_quantized.tflite. Uruchom skrypt w ten sposób:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Aby wypełnić metadane innych modeli klasyfikacji obrazów, dodaj do skryptu specyfikacje modelu, np. takie. W dalszej części tego przewodnika wyróżnimy niektóre kluczowe sekcje w przykładzie klasyfikacji obrazów, aby zilustrować najważniejsze elementy.
Szczegółowa analiza przykładu klasyfikacji obrazów
Informacje o modelu
Metadane zaczynają się od utworzenia nowych informacji o modelu:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informacje o danych wejściowych i wyjściowych
W tej sekcji dowiesz się, jak opisać sygnaturę wejściową i wyjściową modelu. Te metadane mogą być używane przez automatyczne generatory kodu do tworzenia kodu przetwarzania wstępnego i końcowego. Aby utworzyć informacje o tensorze wejściowym lub wyjściowym:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Obraz wejściowy
Obraz jest typowym rodzajem danych wejściowych w przypadku uczenia maszynowego. Metadane LiteRT obsługują informacje takie jak przestrzeń kolorów i informacje o wstępnym przetwarzaniu, np. normalizacja. Wymiar obrazu nie wymaga ręcznego określania, ponieważ jest już podany przez kształt tensora wejściowego i może być automatycznie wywnioskowany.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Dane wyjściowe etykiety
Etykietę można zmapować na tensor wyjściowy za pomocą powiązanego pliku przy użyciu
TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Tworzenie metadanych Flatbuffers
Ten kod łączy informacje o modelu z informacjami wejściowymi i wyjściowymi:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Pakowanie metadanych i powiązanych plików w modelu
Po utworzeniu metadanych Flatbuffers metadane i plik etykiet są zapisywane w pliku TFLite za pomocą metody populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Do modelu możesz spakować dowolną liczbę powiązanych plików za pomocą funkcjiload_associated_files. Wymagane jest jednak spakowanie co najmniej tych plików, które są udokumentowane w metadanych. W tym przykładzie spakowanie pliku etykiety jest obowiązkowe.
Wyświetlanie metadanych
Możesz użyć Netron, aby wizualizować metadane, lub odczytać metadane z modelu LiteRT do formatu JSON za pomocą tego kodu:MetadataDisplayer
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio obsługuje też wyświetlanie metadanych za pomocą funkcji Android Studio ML Binding.
Obsługa wersji metadanych
Schemat metadanych jest wersjonowany zarówno za pomocą numeru wersji semantycznej, który śledzi zmiany w pliku schematu, jak i identyfikatora pliku Flatbuffers, który wskazuje prawdziwą zgodność wersji.
Numer wersji semantycznej
Schemat metadanych jest wersjonowany za pomocą numeru wersji semantycznej, np. GŁÓWNA.PODRZĘDNA.POPRAWKA. Śledzi zmiany schematu zgodnie z zasadami opisanymi tutaj.
Zobacz historię pól dodanych po wersji 1.0.0.
Identyfikacja pliku Flatbuffers
Wersjonowanie semantyczne gwarantuje zgodność, jeśli przestrzegane są reguły, ale nie oznacza prawdziwej niezgodności. Zwiększenie numeru GŁÓWNEGO nie musi oznaczać, że zgodność wsteczna została przerwana. Dlatego używamy identyfikatora pliku Flatbuffers, file_identifier, aby oznaczyć prawdziwą zgodność schematu metadanych. Identyfikator pliku ma dokładnie 4 znaki. Jest on powiązany z określonym schematem metadanych i nie może być zmieniany przez użytkowników. Jeśli z jakiegoś powodu trzeba będzie przerwać zgodność wsteczną schematu metadanych, identyfikator pliku zostanie zwiększony, np. z „M001” na „M002”. Oczekuje się, że identyfikator pliku będzie zmieniany znacznie rzadziej niż wersja metadanych.
Minimalna wymagana wersja parsera metadanych
Minimalna niezbędna wersja parsera metadanych to minimalna wersja parsera metadanych (kod wygenerowany przez Flatbuffers), która może w pełni odczytać metadane Flatbuffers. Wersja jest w praktyce największym numerem wersji spośród wersji wszystkich wypełnionych pól i najmniejszą zgodną wersją wskazaną przez identyfikator pliku. Minimalna niezbędna wersja parsera metadanych jest wypełniana automatycznie przez MetadataPopulator, gdy metadane są wypełniane w modelu TFLite. Więcej informacji o tym, jak jest używana minimalna niezbędna wersja analizatora metadanych, znajdziesz w sekcji ekstraktor metadanych.
Odczytywanie metadanych z modeli
Biblioteka Metadata Extractor to wygodne narzędzie do odczytywania metadanych i powiązanych plików z modeli na różnych platformach (zobacz wersję w języku Java i wersję w języku C++). Możesz utworzyć własne narzędzie do wyodrębniania metadanych w innych językach, korzystając z biblioteki Flatbuffers.
Odczytywanie metadanych w Javie
Aby używać biblioteki Metadata Extractor w aplikacji na Androida, zalecamy korzystanie z pliku AAR metadanych LiteRT hostowanego w MavenCentral.
Zawiera klasę MetadataExtractor oraz powiązania FlatBuffers Java ze schematem metadanych i schematem modelu.
Możesz to określić w zależnościach build.gradle w ten sposób:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Aby korzystać z nocnych migawek, musisz dodać repozytorium migawek Sonatype.
Możesz zainicjować obiekt MetadataExtractor za pomocą obiektu ByteBuffer, który wskazuje model:
public MetadataExtractor(ByteBuffer buffer);
Wartość ByteBuffer musi pozostać niezmieniona przez cały okres istnienia obiektu MetadataExtractor. Inicjowanie może się nie udać, jeśli identyfikator pliku Flatbuffers metadanych modelu nie pasuje do identyfikatora analizatora metadanych. Więcej informacji znajdziesz w sekcji wersjonowanie metadanych.
Dzięki pasującym identyfikatorom plików ekstraktor metadanych będzie mógł odczytywać metadane wygenerowane na podstawie wszystkich schematów z przeszłości i przyszłości ze względu na mechanizm zgodności Flatbuffers z wcześniejszymi i późniejszymi wersjami. Pól z przyszłych schematów nie można jednak wyodrębnić za pomocą starszych ekstraktorów metadanych. Minimalna niezbędna wersja parsera metadanych wskazuje minimalną wersję parsera metadanych, która może w pełni odczytać metadane Flatbuffers. Aby sprawdzić, czy warunek minimalnej wymaganej wersji parsera jest spełniony, możesz użyć tej metody:
public final boolean isMinimumParserVersionSatisfied();
Przekazywanie modelu bez metadanych jest dozwolone. Wywoływanie metod, które odczytują metadane, spowoduje jednak błędy w czasie działania. Aby sprawdzić, czy model ma metadane, wywołaj metodę hasMetadata:
public boolean hasMetadata();
MetadataExtractor udostępnia wygodne funkcje do pobierania metadanych tensorów wejściowych i wyjściowych. Na przykład
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Chociaż schemat modelu LiteRT obsługuje wiele podgrafów, interpreter TFLite obsługuje obecnie tylko jeden podgraf. Dlatego MetadataExtractor pomija indeks podgrafu jako argument wejściowy w swoich metodach.
Odczytywanie powiązanych plików z modeli
Model LiteRT z metadanymi i powiązanymi plikami to w zasadzie plik ZIP, który można rozpakować za pomocą popularnych narzędzi do obsługi plików ZIP, aby uzyskać powiązane pliki. Możesz na przykład rozpakować plik mobilenet_v1_0.75_160_quantized i wyodrębnić z niego plik etykiet w modelu w ten sposób:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Możesz też odczytywać powiązane pliki za pomocą biblioteki Metadata Extractor.
W Javie przekaż nazwę pliku do metody MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Podobnie w C++ można to zrobić za pomocą metody:ModelMetadataExtractor::GetAssociatedFile
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;