
Операторы машинного обучения (ML), используемые в вашей модели, могут повлиять на процесс преобразования модели TensorFlow в формат LiteRT. Конвертер LiteRT поддерживает ограниченное количество операций TensorFlow, используемых в распространённых моделях вывода, что означает, что не все модели можно преобразовать напрямую. Инструмент конвертера позволяет добавлять дополнительные операторы, но для такого преобразования модели также требуется изменение среды выполнения LiteRT, используемой для выполнения модели, что может ограничить возможность использования стандартных вариантов развертывания среды выполнения, таких как сервисы Google Play .
Конвертер LiteRT предназначен для анализа структуры модели и применения оптимизаций для обеспечения её совместимости с напрямую поддерживаемыми операторами. Например, в зависимости от операторов машинного обучения в вашей модели, конвертер может исключить или объединить эти операторы для сопоставления их с аналогами в LiteRT.
Даже для поддерживаемых операций иногда ожидаются определённые шаблоны использования из соображений производительности. Лучший способ понять, как построить модель TensorFlow, подходящую для использования с LiteRT, — это внимательно изучить, как преобразуются и оптимизируются операции, а также ограничения, накладываемые этим процессом.
Поддерживаемые операторы
Встроенные операторы LiteRT являются подмножеством операторов, входящих в базовую библиотеку TensorFlow. Ваша модель TensorFlow также может включать пользовательские операторы в виде составных операторов или новых операторов, определяемых вами. На диаграмме ниже показаны взаимосвязи между этими операторами.
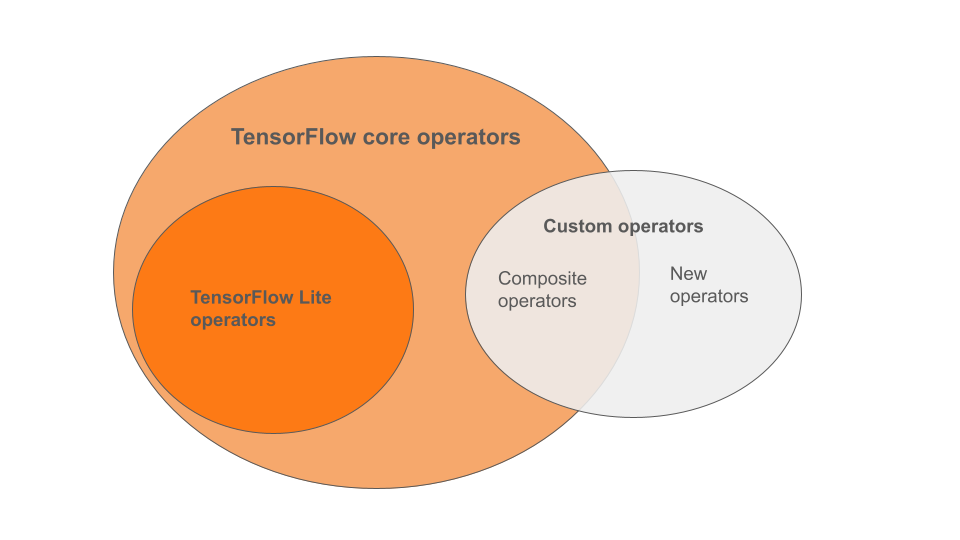
Из этого ряда операторов моделей ML существует 3 типа моделей, поддерживаемых процессом преобразования:
- Модели только со встроенным оператором LiteRT. ( Рекомендуется )
- Модели со встроенными операторами и избранными основными операторами TensorFlow.
- Модели со встроенными операторами, основными операторами TensorFlow и/или пользовательскими операторами.
Если ваша модель содержит только операции, изначально поддерживаемые LiteRT, для её преобразования не требуются дополнительные флаги. Это рекомендуемый путь, поскольку модель такого типа преобразуется плавно и её проще оптимизировать и запускать с использованием стандартной среды выполнения LiteRT. Кроме того, у вас есть больше возможностей для развёртывания модели, например, через сервисы Google Play . Вы можете начать работу с руководством по конвертации LiteRT . Список встроенных операторов см. на странице LiteRT Ops .
Если вам необходимо включить выбранные операции TensorFlow из основной библиотеки, необходимо указать это при конвертации и убедиться, что ваша среда выполнения включает эти операции. Подробные инструкции см. в разделе «Выбор операторов TensorFlow» .
По возможности избегайте последнего варианта — включения пользовательских операторов в преобразованную модель. Пользовательские операторы — это операторы, созданные либо путём объединения нескольких примитивных операторов ядра TensorFlow, либо путём определения совершенно нового оператора. Преобразование пользовательских операторов может увеличить размер модели в целом, создавая зависимости за пределами встроенной библиотеки LiteRT. Пользовательские операторы, если они не созданы специально для развёртывания на мобильных устройствах или устройствах, могут привести к снижению производительности при развёртывании на устройствах с ограниченными ресурсами по сравнению с серверной средой. Наконец, как и включение отдельных операторов ядра TensorFlow, пользовательские операторы требуют изменения среды выполнения модели , что ограничивает использование стандартных служб времени выполнения, таких как сервисы Google Play .
Поддерживаемые типы
Большинство операций LiteRT нацелены как на вывод с плавающей точкой ( float32 ), так и на квантованный вывод ( uint8 , int8 ), но многие операции пока не рассчитаны на другие типы, такие как tf.float16 и строки.
Помимо использования разных версий операций, другое различие между моделями с плавающей запятой и квантованными моделями заключается в способе их преобразования. Квантованное преобразование требует информации о динамическом диапазоне тензоров. Это требует «поддельного квантования» во время обучения модели, получения информации о диапазоне из набора калибровочных данных или оценки диапазона «на лету». Подробнее см. в разделе «Квантование» .
Простые преобразования, постоянное свертывание и слияние
Ряд операций TensorFlow могут быть обработаны LiteRT, несмотря на отсутствие у них прямого эквивалента. Это касается операций, которые можно просто удалить из графа ( tf.identity ), заменить тензорами ( tf.placeholder ) или объединить в более сложные операции ( tf.nn.bias_add ). В результате одного из этих процессов иногда могут быть удалены даже некоторые поддерживаемые операции.
Вот неполный список операций TensorFlow, которые обычно удаляются из графика:
-
tf.add -
tf.debugging.check_numerics -
tf.constant -
tf.div -
tf.divide -
tf.fake_quant_with_min_max_args -
tf.fake_quant_with_min_max_vars -
tf.identity -
tf.maximum -
tf.minimum -
tf.multiply -
tf.no_op -
tf.placeholder -
tf.placeholder_with_default -
tf.realdiv -
tf.reduce_max -
tf.reduce_min -
tf.reduce_sum -
tf.rsqrt -
tf.shape -
tf.sqrt -
tf.square -
tf.subtract -
tf.tile -
tf.nn.batch_norm_with_global_normalization -
tf.nn.bias_add -
tf.nn.fused_batch_norm -
tf.nn.relu -
tf.nn.relu6
Экспериментальные операции
Следующие операции LiteRT присутствуют, но не готовы для пользовательских моделей:
-
CALL -
CONCAT_EMBEDDINGS -
CUSTOM -
EMBEDDING_LOOKUP_SPARSE -
HASHTABLE_LOOKUP -
LSH_PROJECTION -
SKIP_GRAM -
SVDF