Imagen — это высокоточная модель генерации изображений от Google, способная создавать реалистичные и высококачественные изображения на основе текстовых запросов. Все сгенерированные изображения содержат водяной знак SynthID. Подробнее о доступных вариантах модели Imagen см. в разделе « Версии модели» .
Миграция к нано-бананам
Модели Imagen устарели и будут отключены 17 августа 2026 года. Мы рекомендуем перейти на Nano Banana для обработки изображений.
Миграция влечет за собой следующие изменения:
- Название модели : Используйте
gemini-2.5-flash-imageвместо названий моделей Imagen. - Метод : Используйте
client.models.generate_contentвместоclient.models.generate_images. - Обработка ответа : Nano Banana возвращает части контента, которые могут включать данные изображения, вместо конкретного объекта ответа, содержащего изображение.
Более подробную информацию и примеры см. в руководстве по созданию изображений .
Создавайте изображения, используя модели Imagen.
В этом примере демонстрируется генерация изображений с помощью модели Imagen :
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Идти
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
ОТДЫХ
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Конфигурация изображения
В настоящее время Imagen поддерживает только подсказки на английском языке и следующие параметры:
-
numberOfImages: Количество изображений для генерации, от 1 до 4 (включительно). Значение по умолчанию — 4. -
imageSize: Размер создаваемого изображения. Поддерживается только для моделей Standard и Ultra. Поддерживаемые значения:1Kи2K. Значение по умолчанию:1K. -
aspectRatio: Изменяет соотношение сторон создаваемого изображения. Поддерживаемые значения:"1:1","3:4","4:3","9:16"и"16:9". Значение по умолчанию —"1:1". personGeneration: Разрешить модели генерировать изображения людей. Поддерживаются следующие значения:-
"dont_allow": Блокировать генерацию изображений людей. -
"allow_adult": Генерировать изображения взрослых, но не детей. Это значение по умолчанию. -
"allow_all": Создавать изображения, включающие взрослых и детей.
-
Руководство по использованию изображений
В этом разделе руководства по Imagen показано, как изменение запроса на преобразование текста в изображение может привести к различным результатам, а также приведены примеры изображений, которые вы можете создать.
Основы написания текстов по заданным темам
Хороший запрос должен быть описательным и ясным, а также содержать значимые ключевые слова и определения. Начните с обдумывания темы , контекста и стиля .

Тема : Первое, о чем следует подумать, выбирая любое задание, — это тема : предмет, человек, животное или пейзаж, изображение которого вы хотите получить.
Контекст и фон: Не менее важен фон или контекст, в котором будет размещен объект съемки. Попробуйте разместить объект на разных фонах. Например, в студии на белом фоне, на открытом воздухе или в помещении.
Стиль: Наконец, добавьте желаемый стиль изображения. Стили могут быть общими (живопись, фотография, эскизы) или очень специфическими (пастельная живопись, рисунок углем, изометрическая 3D-модель). Вы также можете комбинировать стили.
После того, как вы напишете первый вариант своего задания, доработайте его, добавив больше деталей, пока не получите желаемый образ. Итерация важна. Начните с определения основной идеи, а затем дорабатывайте и расширяйте её, пока полученный образ не будет близок к вашему видению.
 |  |  |
Модели изображений могут превратить ваши идеи в детальные изображения, независимо от того, короткие или длинные и подробные ваши запросы. Уточняйте свое видение с помощью итеративных запросов, добавляя детали, пока не добьетесь идеального результата.
Короткие подсказки позволяют быстро создать изображение.  | Более длинные подсказки позволяют добавить конкретные детали и сформировать свой образ.  |
Дополнительные советы по написанию текстов по заданию Imagen:
- Используйте описательный язык : применяйте подробные прилагательные и наречия, чтобы создать четкую картину для Imagen.
- Предоставьте контекст : при необходимости включите справочную информацию, которая поможет ИИ понять материал.
- Упоминайте конкретных художников или стили : если у вас есть определенное эстетическое видение, полезно будет обратиться к работам конкретных художников или художественным направлениям.
- Используйте инструменты для оптимизации подсказок : Рассмотрите возможность изучения инструментов или ресурсов для оптимизации подсказок, которые помогут вам улучшить ваши подсказки и добиться оптимальных результатов.
- Улучшение детализации лиц на ваших личных и групповых фотографиях : Укажите детали лица как основной акцент фотографии (например, используйте слово «портрет» в задании).
Создание текста на изображениях
Модели изображений позволяют добавлять текст в изображения, открывая новые возможности для креативного создания картинок. Воспользуйтесь приведенными ниже рекомендациями, чтобы максимально эффективно использовать эту функцию:
- Не бойтесь экспериментировать : возможно, вам придётся перегенерировать изображения, пока вы не добьётесь желаемого результата. Интеграция текста в Imagen всё ещё находится в стадии развития, и иногда несколько попыток дают наилучшие результаты.
- Краткость : для оптимальной генерации текста ограничьте его 25 символами или меньше.
Использование нескольких фраз : поэкспериментируйте с двумя или тремя различными фразами, чтобы добавить дополнительную информацию. Избегайте использования более трех фраз для более лаконичного изложения.

Задание: Плакат с заголовком, написанным жирным шрифтом «Летняя страна», под которым расположен слоган «Лето еще никогда не было таким прекрасным». Направляющие для размещения текста : Хотя Imagen может попытаться расположить текст в соответствии с указаниями, возможны occasional отклонения. Эта функция постоянно совершенствуется.
Задайте стиль шрифта : укажите общий стиль шрифта, чтобы незаметно повлиять на выбор шрифтов Imagen. Не полагайтесь на точное воспроизведение шрифта, но ожидайте творческих интерпретаций.
Размер шрифта : Укажите размер шрифта или общее обозначение размера (например, маленький , средний , большой ), чтобы повлиять на генерацию размера шрифта.
Параметризация подсказок
Для более точного контроля результатов может быть полезно параметризовать входные данные в Imagen. Например, предположим, вы хотите, чтобы ваши клиенты могли создавать логотипы для своего бизнеса, и вы хотите убедиться, что логотипы всегда создаются на однотонном фоне. Вы также хотите ограничить выбор параметров, которые клиент может выбрать из меню.
В этом примере вы можете создать параметризованную подсказку, аналогичную следующей:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.В вашем пользовательском интерфейсе клиент может ввести параметры с помощью меню, и выбранное им значение будет отображаться в подсказке, которую получит Imagen.
Например:
Задание:
A minimalist logo for a health care company on a solid color background. Include the text Journey .
Задание:
A modern logo for a software company on a solid color background. Include the text Silo .
Задание:
A traditional logo for a baking company on a solid color background. Include the text Seed .
Продвинутые методы написания заданий
Используйте следующие примеры для создания более конкретных запросов на основе таких атрибутов, как описание фотографии, формы и материалы, исторические направления в искусстве и модификаторы качества изображения.
Фотография
- Задание включает в себя: «Фотография...»
Чтобы использовать этот стиль, начните с ключевых слов, которые четко указывают Imagen, что вы ищете фотографию. Начинайте свои запросы со слов «Фотография...» . Например:
 |  |  |
Источник изображения: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 4.
Фотомодификаторы
В приведенных ниже примерах вы можете увидеть несколько модификаторов и параметров, специфичных для фотографии. Вы можете комбинировать несколько модификаторов для более точного управления.
Съемка крупным планом, с большого расстояния.

Задание: Фотография кофейных зерен крупным планом. 
Задание: Фотография небольшого пакета, сделанная с большого расстояния .
кофейные зерна на грязной кухнеРакурс камеры — вид сверху, снизу.

Задание: аэрофотоснимок городского пейзажа с небоскребами. 
Задание: Фотография лесного полога на фоне голубого неба, сделанная снизу. Освещение — естественное, драматическое, тёплое, холодное

Задание: студийная фотография современного кресла при естественном освещении. 
Задание: студийная фотография современного кресла, эффектное освещение. Настройки камеры - размытие в движении, мягкая фокусировка, боке, портрет.

Задание: фотография города с небоскребами, сделанная из салона автомобиля, с эффектом размытия движения. 
Задание: фотография моста в ночном городском пейзаже с мягким фокусом . Типы объективов : 35 мм, 50 мм, «рыбий глаз», широкоугольный, макро.

Задание: фотография листа, макрообъектив 
Задание: уличная фотография, Нью-Йорк, объектив «рыбий глаз». Типы плёнки — чёрно-белая, полароидная

Задание: полароидный портрет собаки в солнцезащитных очках. 
Задание: черно-белая фотография собаки в солнцезащитных очках.
Источник изображения: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 4.
Иллюстрация и искусство
- Задание включает в себя: « painting с изображением...» , « sketch с изображением...».
Художественные стили варьируются от монохромных, таких как карандашные наброски, до гиперреалистичного цифрового искусства. Например, следующие изображения используют одно и то же задание, но в разных стилях:
« [art style or creation technique] угловатого спортивного электроседана на фоне небоскребов»
 |  |  |
 |  |  |
Источник изображений: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 2.
Формы и материалы
- В задании используются слова: "...сделано из..." , "...в форме...".
Одно из преимуществ этой технологии заключается в возможности создания изображений, которые другими способами сложно или невозможно получить. Например, можно воссоздать логотип вашей компании, используя различные материалы и текстуры.
 |  |  |
Источник изображения: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 4.
Исторические отсылки к искусству
- Задание включает в себя: "...в стиле..."
Некоторые стили со временем стали культовыми. Ниже представлены несколько идей исторических стилей живописи или искусства, которые вы можете попробовать.
"Создать изображение в стиле [art period or movement] : ветряная электростанция"
 |  |  |
Источник изображения: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 4.
Модификаторы качества изображения
Определенные ключевые слова могут дать модели понять, что вы ищете высококачественный ресурс. Примеры модификаторов качества включают следующее:
- Общие модификаторы - высококачественные, красивые, стилизованные
- Фотографии - 4K, HDR, студийная фотосъемка
- Искусство, иллюстрация — от профессионала, с вниманием к деталям.
Ниже приведены несколько примеров подсказок без уточнений качества и той же подсказки с уточнениями качества.
 |  фотография кукурузного стебля , сделанная профессиональный фотограф |
Источник изображения: Каждое изображение было сгенерировано с использованием соответствующего текстового запроса с помощью модели Imagen 4.
Соотношение сторон
Функция генерации изображений позволяет задавать пять различных соотношений сторон изображения.
- Квадратное (1:1, по умолчанию) — стандартное квадратное фото. Часто такое соотношение сторон используется для публикаций в социальных сетях.
Полноэкранный режим (4:3) — это соотношение сторон, широко используемое в медиа и кино. Оно также соответствует размерам большинства старых (не широкоэкранных) телевизоров и среднеформатных камер. Оно захватывает большую часть сцены по горизонтали (по сравнению с 1:1), что делает его предпочтительным соотношением сторон для фотографии.

Задание: крупный план пальцев музыканта, играющего на пианино, черно-белый фильм, винтажный (соотношение сторон 4:3). 
Задание: Профессиональная студийная фотография картофеля фри для элитного ресторана в стиле кулинарного журнала (соотношение сторон 4:3). Портретный полноэкранный режим (3:4) — это полноэкранное соотношение сторон, повернутое на 90 градусов. Это позволяет захватывать большую часть сцены по вертикали по сравнению с соотношением сторон 1:1.

Задание: женщина, идущая в поход, отражение её ботинок в луже, на заднем плане высокие горы, в стиле рекламы, эффектные ракурсы (соотношение сторон 3:4). 
Задание: аэрофотосъемка реки, текущей по мистической долине (соотношение сторон 3:4). Широкоэкранный формат (16:9) — это соотношение сторон, заменившее 4:3, и в настоящее время является наиболее распространенным для телевизоров, мониторов и экранов мобильных телефонов (альбомная ориентация). Используйте это соотношение сторон, когда хотите охватить большую часть фона (например, живописные пейзажи).

Задание: мужчина в белой одежде сидит на пляже, крупный план, освещение в «золотой час» (соотношение сторон 16:9). Портретный формат (9:16) — это широкоэкранный формат, но с поворотом. Это относительно новое соотношение сторон, получившее популярность благодаря приложениям для коротких видеороликов (например, YouTube Shorts). Используйте его для высоких объектов с выраженной вертикальной ориентацией, таких как здания, деревья, водопады или другие подобные объекты.

Задание: цифровая визуализация массивного небоскреба, современного, величественного, грандиозного, с прекрасным закатом на заднем плане (соотношение сторон 9:16).
Фотореалистичные изображения
Различные версии модели генерации изображений могут предлагать сочетание художественного и фотореалистичного результата. Используйте следующие формулировки в подсказках, чтобы получить более фотореалистичный результат в зависимости от желаемой тематики.
| Вариант использования | Тип линзы | Фокусные расстояния | Дополнительные сведения |
|---|---|---|---|
| Люди (портреты) | Прайм, зум | 24-35 мм | Черно-белая пленка, фильм нуар, глубина резкости, двухцветная съемка (укажите два цвета) |
| Еда, насекомые, растения (предметы, натюрморты) | Макро | 60-105 мм | Высокая детализация, точная фокусировка, контролируемое освещение. |
| Спорт, дикая природа (в движении) | Телеобъектив с зумом | 100-400 мм | Короткая выдержка, отслеживание движения или действия |
| Астрономическая, пейзажная (широкоугольная) фотография | Широкоугольный | 10-24 мм | Длительная выдержка, резкая фокусировка, длительная выдержка, гладкая вода или облака |
Портреты
| Вариант использования | Тип линзы | Фокусные расстояния | Дополнительные сведения |
|---|---|---|---|
| Люди (портреты) | Прайм, зум | 24-35 мм | Черно-белая пленка, фильм нуар, глубина резкости, двухцветная съемка (укажите два цвета) |
Используя несколько ключевых слов из таблицы, Imagen может сгенерировать следующие портреты:
 |  |  |  |
Задание: Женщина, портрет, 35 мм, двухцветная сине-серая гамма.
Модель: imagen-4.0-generate-001
 |  |  |  |
Задание: Женщина, портрет, 35 мм, фильм нуар.
Модель: imagen-4.0-generate-001
Объекты
| Вариант использования | Тип линзы | Фокусные расстояния | Дополнительные сведения |
|---|---|---|---|
| Еда, насекомые, растения (предметы, натюрморты) | Макро | 60-105 мм | Высокая детализация, точная фокусировка, контролируемое освещение. |
Используя несколько ключевых слов из таблицы, Imagen может сгенерировать следующие изображения объектов:
 |  |  |  |
Задание: лист молитвенного растения, макрообъектив, 60 мм
Модель: imagen-4.0-generate-001
 |  |  |  |
Задание: тарелка пасты, макрообъектив 100 мм.
Модель: imagen-4.0-generate-001
Движение
| Вариант использования | Тип линзы | Фокусные расстояния | Дополнительные сведения |
|---|---|---|---|
| Спорт, дикая природа (в движении) | Телеобъектив с зумом | 100-400 мм | Короткая выдержка, отслеживание движения или действия |
Используя несколько ключевых слов из таблицы, Imagen может сгенерировать следующие видеоролики:
 |  | 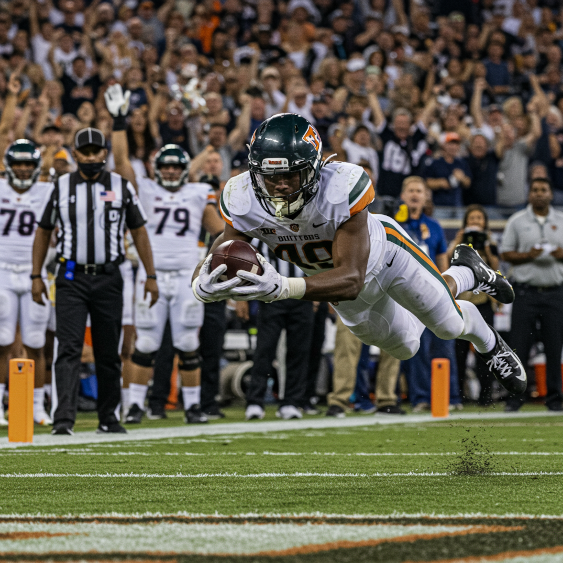 |  |
Подсказка: победный тачдаун, быстрая выдержка, отслеживание движения.
Модель: imagen-4.0-generate-001
 |  |  |  |
Задание: Олень бежит в лесу, быстрая выдержка, слежение за движением.
Модель: imagen-4.0-generate-001
Широкоугольный
| Вариант использования | Тип линзы | Фокусные расстояния | Дополнительные сведения |
|---|---|---|---|
| Астрономическая, пейзажная (широкоугольная) фотография | Широкоугольный | 10-24 мм | Длительная выдержка, резкая фокусировка, длительная выдержка, гладкая вода или облака |
Используя несколько ключевых слов из таблицы, Imagen может сгенерировать следующие широкоугольные изображения:
 |  |  |  |
Подсказка: обширный горный хребет, пейзаж, широкоугольный объектив 10 мм.
Модель: imagen-4.0-generate-001
 |  |  |  |
Задание: фотография Луны, астрофотография, широкоугольный объектив 10 мм.
Модель: imagen-4.0-generate-001
Версии моделей
Imagen 4 (Устарело)
| Свойство | Описание |
|---|---|
| Код модели | API Gemini |
| Поддерживаемые типы данных | Вход Текст Выход Изображения |
| Ограничения на количество токенов [*] | Ограничение на количество введенных токенов 480 токенов (текст) Выходные изображения 1–4 (Ультра/Стандарт/Быстрый) |
| Последнее обновление | Июнь 2025 г. |
Изображение 3
Производство модели Imagen 3 прекращено .