
LiteRT es el framework integrado en el dispositivo de Google para la implementación de AA y de IA generativa de alto rendimiento en plataformas perimetrales.
Conversión, tiempo de ejecución y optimización eficientes para el aprendizaje automático integrado en el dispositivo.
Compilado sobre la base probada de TensorFlow Lite
LiteRT no solo es nuevo, sino que es la próxima generación del entorno de ejecución de aprendizaje automático más implementado del mundo. Potencia las apps que usas todos los días, ofrece baja latencia y alta privacidad en miles de millones de dispositivos.
Cuenta con la confianza de las apps de Google más importantes
Más de 100, 000 aplicaciones y miles de millones de usuarios en todo el mundo
Destacados de LiteRT

Lista para multiplataforma

Libera la IA generativa

Aceleración de hardware simplificada

Compatibilidad con varios frameworks
Implementa a través de LiteRT
Optimiza tu flujo de trabajo de aprendizaje profundo, desde el entrenamiento hasta la implementación en el dispositivo.

1.Obtén un modelo
Usa modelos previamente entrenados .tflite o convierte modelos de PyTorch, JAX o TensorFlow a .tflite.

2.Optimiza
Usa el kit de herramientas de optimización de LiteRT para cuantizar tus modelos después del entrenamiento.

3.Ejecutar
Implementa tu modelo con LiteRT y elige el acelerador óptimo para tu app.
Elige tu ruta de desarrollo
Usa LiteRT para implementar la IA en cualquier lugar, desde apps para dispositivos móviles de alto rendimiento hasta dispositivos de IoT con recursos limitados.
Usuario existente de TFLite
Se realizó la transición a LiteRT para aprovechar el rendimiento mejorado y las APIs unificadas en todas las plataformas (Android, escritorio y Web).
BYOM : Bring your own Models
Tener un modelo de PyTorch y querer implementar experiencias de audio o visión en el dispositivo
Implementación de modelos de IA generativa
Crear chatbots sofisticados en el dispositivo con modelos de IA generativa optimizados y de peso abierto, como Gemma o algún otro modelo de peso abierto
[Advanced] Model Expert
Crear modelos personalizados o realizar optimizaciones profundas específicas del hardware de CPU/GPU/NPU para obtener el máximo rendimiento
Muestras, modelos y demostración

Consulta la app de ejemplo de LiteRT en GitHub
Apps de ejemplo completas de extremo a extremo

Ver modelos de IA generativa
Modelos de IA generativa listos para usar y entrenados previamente.

Ver demostraciones: App de Google AI Edge Gallery
Una galería que muestra casos de uso de AA/IA generativa integrados en el dispositivo con LiteRT.
Blogs y anuncios
Mantente al tanto de los anuncios más recientes, los análisis técnicos detallados y las comparativas de rendimiento del equipo de LiteRT.

Cómo crear IA integrada en el dispositivo para el mundo real con LiteRT y NPU
Descubre cómo los líderes de la industria compilan aplicaciones de IA integradas en el dispositivo de alto rendimiento y del mundo real con LiteRT y NPU.
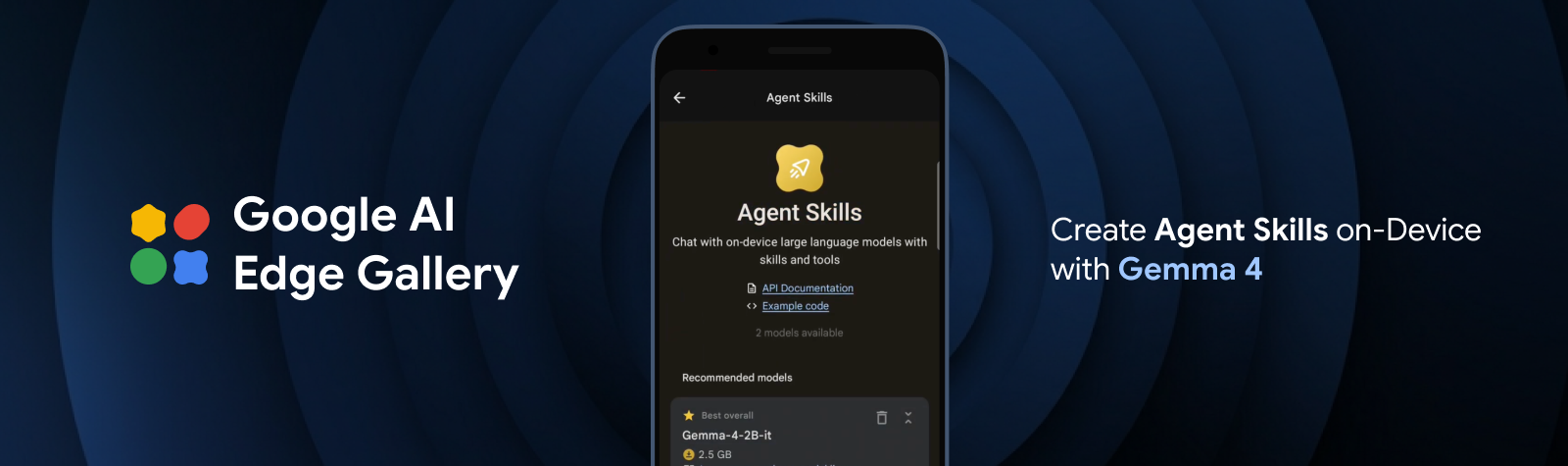
Incorpora habilidades de agente de vanguardia al borde con Gemma 4
Implementa capacidades de planificación con agentes y de varios pasos integrado en el dispositivo con la nueva familia Gemma 4 y LiteRT.

LiteRT: El marco de trabajo universal para la IA integrada en el dispositivo
Es el framework unificado de AA integrado en el dispositivo de Google, que evolucionó a partir de TFLite para una implementación de alto rendimiento.
NPU y LiteRT de MediaTek: Potenciamos la nueva generación de IA integrada en el dispositivo
Se amplió la compatibilidad con la aceleración de la NPU para los chipsets de MediaTek, lo que permite una IA de alta eficiencia.
Cómo desbloquear el máximo rendimiento en la NPU de Qualcomm con LiteRT
Se desbloqueó un rendimiento revolucionario para la IA generativa en las unidades de procesamiento neuronal de Qualcomm.

LiteRT: Máximo rendimiento, simplificado
Presentamos la API de CompiledModel para la selección de hardware automatizada y la ejecución asíncrona.
IA generativa integrada en el dispositivo en Chrome, Chromebook Plus y Pixel Watch con LiteRT-LM
Implementa modelos de lenguaje en plataformas basadas en navegadores y wearables con LiteRT-LM.

Modelos de lenguaje pequeños, multimodalidad y llamadas a funciones de Google AI Edge
Las estadísticas más recientes sobre RAG, multimodalidad y llamada a función para modelos de lenguaje perimetrales
Únete a la Comunidad
Comunidad de LiteRT en GitHub
Contribuir directamente al proyecto y colaborar con los desarrolladores principales

Hugging Face Hub
Accede a modelos de código abierto optimizados en Hugging Face Hub.