
MediaPipe 手勢辨識器工作可讓您即時辨識手勢,並提供已辨識的手勢結果和偵測到的手部地標。本操作說明將說明如何針對網路和 JavaScript 應用程式使用手勢辨識器。
您可以觀看示範影片,瞭解這項工作的實際運作情形。如要進一步瞭解這項工作的功能、模型和設定選項,請參閱總覽。
程式碼範例
手勢辨識器的範例程式碼可讓您參考如何在 JavaScript 中完整實作此項工作。這段程式碼可協助您測試這項工作,並開始建構自己的手勢辨識應用程式。您只需使用網頁瀏覽器,即可查看、執行及編輯手勢辨識器範例程式碼。
設定
本節將說明設定開發環境的關鍵步驟,特別是使用手勢辨識器的步驟。如要進一步瞭解如何設定網路和 JavaScript 開發環境,包括平台版本需求,請參閱網路設定指南。
JavaScript 套件
您可以透過 MediaPipe @mediapipe/tasks-vision
NPM 套件取得手勢辨識器程式碼。您可以按照平台設定指南中的操作說明,尋找及下載這些程式庫。
您可以使用下列指令,透過 NPM 安裝必要套件:
npm install @mediapipe/tasks-vision
如要透過內容傳遞網路 (CDN) 服務匯入工作程式碼,請在 HTML 檔案的 <head> 標記中加入下列程式碼:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
型號
MediaPipe 手勢辨識器工作需要訓練的模型,且必須與此工作相容。如要進一步瞭解手勢辨識器可用的訓練模型,請參閱任務總覽的「模型」一節。
選取並下載模型,然後將模型儲存在專案目錄中:
<dev-project-root>/app/shared/models/
建立工作
使用其中一個手勢辨識器 createFrom...() 函式,準備執行推論的工作。使用 createFromModelPath() 函式搭配訓練模型檔案的相對或絕對路徑。如果模型已載入至記憶體,您可以使用 createFromModelBuffer() 方法。
以下程式碼範例示範如何使用 createFromOptions() 函式設定工作。createFromOptions 函式可讓您使用設定選項自訂手勢辨識器。如要進一步瞭解設定選項,請參閱「設定選項」。
以下程式碼示範如何使用自訂選項建構及設定工作:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
設定選項
此工作包含下列網頁應用程式設定選項:
| 選項名稱 | 說明 | 值範圍 | 預設值 |
|---|---|---|---|
runningMode |
設定工作執行模式。有兩種模式: IMAGE:單張圖片輸入模式。 影片:解碼影片影格或輸入資料 (例如來自攝影機) 直播的模式。 |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
GestureRecognizer 最多可偵測的手數。 |
Any integer > 0 |
1 |
min_hand_detection_confidence |
在手掌偵測模型中,手部偵測的最低信賴分數,才會視為成功。 | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
手部地標偵測模型中手部存在分數的最低可信度分數。在手勢辨識器的影片模式和直播模式中,如果手標記模型的手部存在可信度分數低於此閾值,則會觸發手掌偵測模型。否則,系統會使用輕量手勢追蹤演算法,判斷手的位置,以便後續的顯著點偵測。 | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
手部追蹤系統判定為成功的最低可信度分數。這是目前影格和上一個影格中手的定界框交併比閾值。在手勢辨識器的影片模式和串流模式中,如果追蹤失敗,手勢辨識器會觸發手部偵測。否則系統會略過手勢偵測。 | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
設定預先錄製手勢分類器行為的選項。罐頭手勢為 ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
設定自訂手勢分類器行為的選項。 |
|
|
準備資料
手勢辨識器可辨識主機瀏覽器支援的任何圖片格式中的手勢。此工作也會處理資料輸入預先處理作業,包括調整大小、旋轉和值正規化。如要辨識影片中的手勢,您可以使用 API 一次快速處理一個影格,並利用影格時間戳記判斷手勢在影片中出現的時間。
執行工作
手勢辨識器會使用 recognize() (執行模式為 'image') 和 recognizeForVideo() (執行模式為 'video') 方法觸發推論。任務會處理資料、嘗試辨識手勢,然後回報結果。
以下程式碼示範如何使用工作模型執行處理作業:
圖片
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
影片
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
對手勢辨識器 recognize() 和 recognizeForVideo() 方法的呼叫會同步執行,並封鎖使用者介面執行緒。如果您在裝置相機的影片影格中辨識手勢,每個辨識動作都會阻斷主執行緒。如要避免這種情況,您可以實作網路 worker,在另一個執行緒上執行 recognize() 和 recognizeForVideo() 方法。
如需更完整的執行手勢辨識器工作實作方式,請參閱程式碼範例。
處理及顯示結果
手勢辨識器會為每次執行的辨識作業產生手勢偵測結果物件。結果物件包含圖片座標中的手標記、世界座標中的手標記、手的慣用手(左手/右手),以及偵測到的手部手勢類別。
以下是這項工作的輸出資料範例:
產生的 GestureRecognizerResult 包含四個元件,每個元件都是陣列,每個元素都包含偵測到單一手的偵測結果。
慣用手
慣用手代表偵測到的手是左手還是右手。
手勢
系統偵測到的手勢類別。
地標
手部有 21 個地標,每個地標都由
x、y和z座標組成。x和y座標會分別根據圖片寬度和高度,正規化為 [0.0, 1.0]。z座標代表地標深度,其中手腕的深度為原點。值越小,地標與相機的距離就越近。z的大小會使用與x大致相同的刻度。世界著名地標
21 個手部地標也會以世界座標呈現。每個地標都由
x、y和z組成,代表以公尺為單位的實際 3D 座標,起點位於手的幾何中心。
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
下圖是工作輸出內容的視覺化呈現:
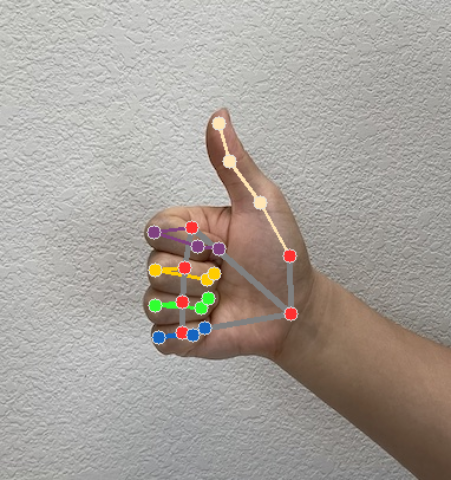
如需更完整的實作方式,請參閱程式碼範例,瞭解如何建立手勢辨識器工作。