
La tâche MediaPipe Gesture Recognizer vous permet de reconnaître les gestes de la main en temps réel. Elle fournit les résultats de la reconnaissance des gestes de la main et les points de repère des mains détectées. Ces instructions vous expliquent comment utiliser Gesture Recognizer pour les applications Web et JavaScript.
Vous pouvez voir cette tâche en action en regardant la démonstration. Pour en savoir plus sur les fonctionnalités, les modèles et les options de configuration de cette tâche, consultez la présentation.
Exemple de code
L'exemple de code pour Gesture Recognizer fournit une implémentation complète de cette tâche en JavaScript à titre de référence. Ce code vous aide à tester cette tâche et à commencer à créer votre propre application de reconnaissance de gestes. Vous pouvez afficher, exécuter et modifier l'exemple de Gesture Recognizer à l'aide de votre navigateur Web.
Configuration
Cette section décrit les étapes clés de la configuration de votre environnement de développement, en particulier pour utiliser Gesture Recognizer. Pour obtenir des informations générales sur la configuration de votre environnement de développement Web et JavaScript, y compris les exigences concernant la version de la plate-forme, consultez le guide de configuration pour le Web.
Packages JavaScript
Le code de Gesture Recognizer est disponible via le package @mediapipe/tasks-vision
NPM MediaPipe. Vous pouvez
trouver et télécharger ces bibliothèques en suivant les instructions du guide de configuration de la plate-forme
Setup.
Vous pouvez installer les packages requis via NPM à l'aide de la commande suivante :
npm install @mediapipe/tasks-vision
Si vous souhaitez importer le code de la tâche via un service de réseau de diffusion de contenu (CDN)
, ajoutez le code suivant dans la balise <head> de votre fichier HTML :
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Modèle
La tâche MediaPipe Gesture Recognizer nécessite un modèle entraîné compatible avec cette tâche. Pour en savoir plus sur les modèles entraînés disponibles pour Gesture Recognizer, consultez la section Modèles de la présentation de la tâche.
Sélectionnez et téléchargez le modèle, puis stockez-le dans le répertoire de votre projet :
<dev-project-root>/app/shared/models/
Créer la tâche
Utilisez l'une des fonctions createFrom...() de Gesture Recognizer pour préparer la tâche à exécuter des inférences. Utilisez la fonction createFromModelPath() avec un chemin d'accès relatif ou absolu au fichier de modèle entraîné.
Si votre modèle est déjà chargé en mémoire, vous pouvez utiliser la méthode createFromModelBuffer().
L'exemple de code ci-dessous montre comment utiliser la fonction createFromOptions() pour configurer la tâche. La fonction createFromOptions vous permet de personnaliser Gesture Recognizer avec des options de configuration. Pour en savoir plus sur les options de configuration, consultez la section Options de configuration.
Le code suivant montre comment créer et configurer la tâche avec des options personnalisées :
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Options de configuration
Cette tâche comporte les options de configuration suivantes pour les applications Web :
| Nom de l'option | Description | Plage de valeurs | Valeur par défaut |
|---|---|---|---|
runningMode |
Définit le mode d'exécution de la tâche. Il existe deux
modes: IMAGE : mode pour les entrées d'image unique. VIDEO : mode pour les frames décodées d'une vidéo ou d'une diffusion en direct de données d'entrée, par exemple à partir d'une caméra. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
Nombre maximal de mains pouvant être détectées par
GestureRecognizer.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
Score de confiance minimal pour que la détection de la main soit considérée comme réussie dans le modèle de détection de la paume. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
Score de confiance minimal de la présence de la main dans le modèle de détection des points de repère de la main. En mode vidéo et en mode diffusion en direct de Gesture Recognizer, si le score de confiance de la présence de la main du modèle de points de repère de la main est inférieur à ce seuil, il déclenche le modèle de détection de la paume. Sinon, un algorithme léger de suivi de la main est utilisé pour déterminer l'emplacement de la ou des mains pour la détection ultérieure des points de repère. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
Score de confiance minimal pour que le suivi de la main soit considéré comme réussi. Il s'agit du seuil d'IoU du cadre de délimitation entre les mains dans la frame actuelle et la dernière frame. En mode vidéo et en mode diffusion de Gesture Recognizer, si le suivi échoue, Gesture Recognizer déclenche la détection de la main. Sinon, la détection de la main est ignorée. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Options de configuration du comportement du classificateur de gestes prédéfinis. Les gestes prédéfinis sont ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
Options de configuration du comportement du classificateur de gestes personnalisés. |
|
|
Préparer les données
Gesture Recognizer peut reconnaître les gestes dans les images dans n'importe quel format compatible avec le navigateur hôte. La tâche gère également le prétraitement des données d'entrée, y compris le redimensionnement, la rotation et la normalisation des valeurs. Pour reconnaître les gestes dans les vidéos, vous pouvez utiliser l'API pour traiter rapidement une frame à la fois, en utilisant l'horodatage de la frame pour déterminer quand les gestes se produisent dans la vidéo.
Exécuter la tâche
Gesture Recognizer utilise les méthodes recognize() (avec le mode d'exécution 'image') et
recognizeForVideo() (avec le mode d'exécution 'video') pour déclencher
des inférences. La tâche traite les données, tente de reconnaître les gestes de la main, puis signale les résultats.
Le code suivant montre comment exécuter le traitement avec le modèle de tâche :
Image
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Vidéo
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Les appels aux méthodes recognize() et recognizeForVideo() de Gesture Recognizer s'exécutent de manière synchrone et bloquent le thread de l'interface utilisateur. Si vous reconnaissez des gestes dans les frames vidéo de la caméra d'un appareil, chaque reconnaissance bloque le thread principal. Vous pouvez éviter cela en implémentant des Web Workers pour exécuter les méthodes recognize() et recognizeForVideo() sur un autre thread.
Pour une implémentation plus complète de l'exécution d'une tâche Gesture Recognizer, consultez le exemple.
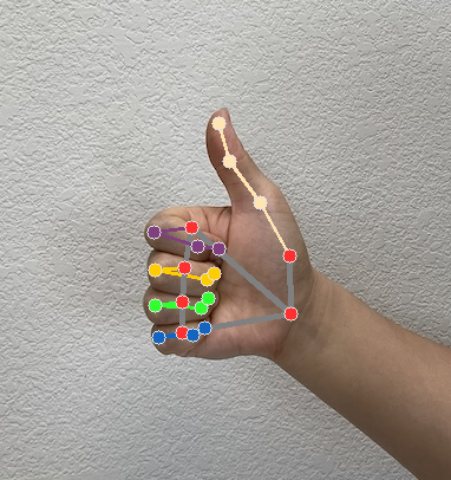
Gérer et afficher les résultats
Gesture Recognizer génère un objet de résultat de détection de gestes pour chaque exécution de reconnaissance. L'objet de résultat contient les points de repère de la main dans les coordonnées de l'image, les points de repère de la main dans les coordonnées mondiales, la main dominante(gauche/droite) et les catégories de gestes de la main des mains détectées.
Voici un exemple des données de sortie de cette tâche :
Le GestureRecognizerResult obtenu contient quatre composants, et chaque composant est un tableau, où chaque élément contient le résultat détecté d'une seule main détectée.
Main dominante
La main dominante indique si les mains détectées sont gauches ou droites.
Gestes
Catégories de gestes reconnues des mains détectées.
Points de repère
Il existe 21 points de repère de la main, chacun composé de coordonnées
x,yetz. Les coordonnéesxetysont normalisées sur [0.0, 1.0] par la largeur et la hauteur de l'image, respectivement. La coordonnéezreprésente la profondeur du point de repère, l'origine étant la profondeur au niveau du poignet. Plus la valeur est petite, plus le point de repère est proche de la caméra. La magnitude dezutilise à peu près la même échelle quex.Points de repère mondiaux
Les 21 points de repère de la main sont également présentés dans les coordonnées mondiales. Chaque point de repère est composé de
x,yetz, qui représentent des coordonnées 3D réelles en mètres, l'origine étant le centre géométrique de la main.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Les images suivantes montrent une visualisation de la sortie de la tâche :
Pour une implémentation plus complète de la création d'une tâche Gesture Recognizer, consultez l' exemple.