
MediaPipe Gesture Recognizer タスクを使用すると、手ジェスチャーをリアルタイムで認識し、認識された手ジェスチャーの結果と検出された手のランドマークを取得できます。ここでは、ウェブアプリと JavaScript アプリでジェスチャー認識ツールを使用する方法について説明します。
このタスクの動作を確認するには、デモをご覧ください。このタスクの機能、モデル、構成オプションの詳細については、概要をご覧ください。
サンプルコード
ジェスチャー認識ツールのサンプルコードには、このタスクの JavaScript での完全な実装が含まれています。このコードは、このタスクをテストし、独自のジェスチャー認識アプリの作成を開始するのに役立ちます。ジェスチャー認識ツールのサンプルコードは、ウェブブラウザだけで表示、実行、編集できます。
セットアップ
このセクションでは、ジェスチャー認識機能を使用するように開発環境を設定する主な手順について説明します。プラットフォームのバージョン要件など、ウェブと JavaScript の開発環境の設定に関する一般的な情報については、ウェブの設定ガイドをご覧ください。
JavaScript パッケージ
ジェスチャー認識コードは、MediaPipe @mediapipe/tasks-vision
NPM パッケージで入手できます。これらのライブラリは、プラットフォームの設定ガイドの手順に沿って見つけ、ダウンロードできます。
必要なパッケージは、次のコマンドを使用して NPM からインストールできます。
npm install @mediapipe/tasks-vision
コンテンツ配信ネットワーク(CDN)サービス経由でタスクコードをインポートする場合は、HTML ファイルの <head> タグに次のコードを追加します。
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
モデル
MediaPipe ジェスチャー認識タスクには、このタスクに対応したトレーニング済みモデルが必要です。ジェスチャー認識ツールで使用可能なトレーニング済みモデルの詳細については、タスクの概要のモデルのセクションをご覧ください。
モデルを選択してダウンロードし、プロジェクト ディレクトリに保存します。
<dev-project-root>/app/shared/models/
タスクを作成する
ジェスチャー認識機能の createFrom...() 関数のいずれかを使用して、推論を実行するタスクを準備します。トレーニング済みモデルファイルの相対パスまたは絶対パスを指定して createFromModelPath() 関数を使用します。モデルがすでにメモリに読み込まれている場合は、createFromModelBuffer() メソッドを使用できます。
次のコードサンプルは、createFromOptions() 関数を使用してタスクを設定する方法を示しています。createFromOptions 関数を使用すると、構成オプションでジェスチャー認識ツールをカスタマイズできます。構成オプションの詳細については、構成オプションをご覧ください。
次のコードは、カスタム オプションを使用してタスクをビルドして構成する方法を示しています。
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
設定オプション
このタスクには、ウェブ アプリケーションの次の構成オプションがあります。
| オプション名 | 説明 | 値の範囲 | デフォルト値 |
|---|---|---|---|
runningMode |
タスクの実行モードを設定します。モードは 2 つあります。 IMAGE: 単一画像入力のモード。 動画: 動画のフレームまたはカメラなどの入力データのライブ配信のデコード モード。 |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
検出できる手の最大数は GestureRecognizer によって決まります。 |
Any integer > 0 |
1 |
min_hand_detection_confidence |
手の検出が成功と見なされるために必要な、手のひら検出モデルの信頼度の最小スコア。 | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
手のランドマーク検出モデルにおける手の存在スコアの最小信頼度スコア。ジェスチャー認識ツールの動画モードとライブ配信モードでは、手のランドマーク モデルからの手の存在の信頼スコアがこのしきい値を下回ると、手のひら検出モデルがトリガーされます。それ以外の場合は、軽量の手トラッキング アルゴリズムを使用して、その後のランドマーク検出のために手の位置を決定します。 | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
ハンド トラッキングが成功とみなされるための最小信頼スコア。これは、現在のフレームと最後のフレームの手の境界ボックスの IoU しきい値です。ジェスチャー認識機能の動画モードとストリーミング モードでは、トラッキングに失敗すると、ジェスチャー認識機能が手の検出をトリガーします。そうでない場合、手の検出はスキップされます。 | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
定型ジェスチャー分類システムの動作を構成するためのオプション。定型ジェスチャーは ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]です。 |
|
|
custom_gestures_classifier_options |
カスタム ジェスチャー分類システムの動作を構成するためのオプション。 |
|
|
データの準備
ジェスチャー認識機能は、ホストブラウザでサポートされている任意の形式の画像内のジェスチャーを認識できます。このタスクは、サイズ変更、回転、値の正規化などのデータ入力前処理も処理します。動画内のジェスチャーを認識するには、API を使用して一度に 1 フレームずつすばやく処理し、フレームのタイムスタンプを使用して動画内でジェスチャーが発生したタイミングを特定します。
タスクを実行する
ジェスチャー認識機能は、recognize() メソッド(実行モード 'image' の場合)と recognizeForVideo() メソッド(実行モード 'video' の場合)を使用して推論をトリガーします。タスクはデータを処理し、手のジェスチャーを認識しようとしてから、結果を報告します。
次のコードは、タスクモデルを使用して処理を実行する方法を示しています。
画像
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
動画
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
ジェスチャー認識機能の recognize() メソッドと recognizeForVideo() メソッドの呼び出しは同期的に実行され、ユーザー インターフェース スレッドをブロックします。デバイスのカメラの動画フレームでジェスチャーを認識する場合、認識ごとにメインスレッドがブロックされます。これを回避するには、ウェブワーカーを実装して、recognize() メソッドと recognizeForVideo() メソッドを別のスレッドで実行します。
ジェスチャー認識タスクの実行の詳細な実装については、コードサンプルをご覧ください。
結果を処理して表示する
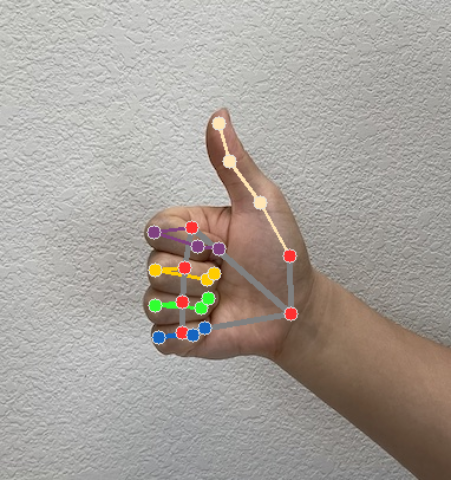
ジェスチャー認識機能は、認識の実行ごとにジェスチャー検出結果オブジェクトを生成します。結果オブジェクトには、画像座標のハンドランドマーク、ワールド座標のハンドランドマーク、利き手(左手/右手)、検出された手のハンドジェスチャー カテゴリが含まれます。
このタスクの出力データの例を次に示します。
結果の GestureRecognizerResult には 4 つのコンポーネントが含まれ、各コンポーネントは配列です。各要素には、検出された 1 つの手の検出結果が含まれます。
利き手
利き手は、検出された手が左手か右手かを表します。
ジェスチャー
検出された手の認識されたジェスチャー カテゴリ。
ランドマーク
手に関するランドマークは 21 個あり、それぞれ
x、y、zの座標で構成されています。x座標とy座標は、それぞれ画像の幅と高さで [0.0, 1.0] に正規化されます。z座標はランドマークの深さを表します。手首の深さが原点になります。値が小さいほど、ランドマークはカメラに近くなります。zの振幅は、xとほぼ同じスケールを使用します。世界の名所
21 個の手のランドマークもワールド座標で表されます。各ランドマークは
x、y、zで構成され、手形の幾何学的中心を原点として、メートル単位の現実世界の 3D 座標を表します。
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
次の画像は、タスク出力の可視化を示しています。
ジェスチャー認識タスクの作成の詳細な実装については、コードサンプルをご覧ください。