
MediaPipe के 'हाथ के लैंडमार्क' टास्क की मदद से, किसी इमेज में हाथ के लैंडमार्क का पता लगाया जा सकता है. इन निर्देशों में, Python के साथ हाथ के लैंडमार्क का इस्तेमाल करने का तरीका बताया गया है. इन निर्देशों में बताया गया कोड सैंपल, GitHub पर उपलब्ध है.
इस टास्क की सुविधाओं, मॉडल, और कॉन्फ़िगरेशन के विकल्पों के बारे में ज़्यादा जानने के लिए, खास जानकारी देखें.
कोड का उदाहरण
हाथ के लैंडमार्क के लिए दिए गए कोड के उदाहरण में, Python में इस टास्क को लागू करने का पूरा तरीका बताया गया है. इस कोड की मदद से, इस टास्क की जांच की जा सकती है और हाथ के लैंडमार्क का पता लगाने वाला अपना सिस्टम बनाया जा सकता है. सिर्फ़ वेब ब्राउज़र का इस्तेमाल करके, हाथ के लैंडमार्कर के उदाहरण के कोड को देखा, चलाया, और उसमें बदलाव किया जा सकता है.
अगर Raspberry Pi के लिए हाथ के लैंडमार्क का इस्तेमाल किया जा रहा है, तो Raspberry Pi के लिए बने उदाहरण के ऐप्लिकेशन को देखें.
सेटअप
इस सेक्शन में, खास तौर पर हाथ के लैंडमार्क का इस्तेमाल करने के लिए, डेवलपमेंट एनवायरमेंट और कोड प्रोजेक्ट सेट अप करने के मुख्य चरणों के बारे में बताया गया है. MediaPipe Tasks का इस्तेमाल करने के लिए, डेवलपमेंट एनवायरमेंट सेट अप करने के बारे में सामान्य जानकारी पाने के लिए, Python के लिए सेटअप गाइड देखें. इसमें प्लैटफ़ॉर्म के वर्शन से जुड़ी ज़रूरी शर्तें भी शामिल हैं.
पैकेज
MediaPipe Hand Landmarker टास्क के लिए, mediapipe PyPI पैकेज की ज़रूरत होती है. इन डिपेंडेंसी को इनके साथ इंस्टॉल और इंपोर्ट किया जा सकता है:
$ python -m pip install mediapipe
आयात
हाथ के लैंडमार्कर टास्क के फ़ंक्शन ऐक्सेस करने के लिए, ये क्लास इंपोर्ट करें:
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
मॉडल
MediaPipe के हाथ के लैंडमार्क का पता लगाने वाले टूल के लिए, ऐसे मॉडल की ज़रूरत होती है जिसे इस टास्क के लिए ट्रेन किया गया हो. हाथ के लैंडमार्क के लिए, ट्रेन किए गए उपलब्ध मॉडल के बारे में ज़्यादा जानकारी के लिए, टास्क की खास जानकारी वाला मॉडल सेक्शन देखें.
मॉडल चुनें और डाउनलोड करें. इसके बाद, उसे किसी लोकल डायरेक्ट्री में सेव करें:
model_path = '/absolute/path/to/gesture_recognizer.task'
इस्तेमाल किए जाने वाले मॉडल का पाथ बताने के लिए, BaseOptions ऑब्जेक्ट model_asset_path पैरामीटर का इस्तेमाल करें. कोड का उदाहरण देखने के लिए, अगला सेक्शन देखें.
टास्क बनाना
MediaPipe Hand Landmarker टास्क, टास्क सेट अप करने के लिए create_from_options फ़ंक्शन का इस्तेमाल करता है. create_from_options फ़ंक्शन, कॉन्फ़िगरेशन के विकल्पों को मैनेज करने के लिए वैल्यू स्वीकार करता है. कॉन्फ़िगरेशन के विकल्पों के बारे में ज़्यादा जानने के लिए, कॉन्फ़िगरेशन के विकल्प लेख पढ़ें.
नीचे दिए गए कोड में, इस टास्क को बनाने और कॉन्फ़िगर करने का तरीका बताया गया है.
इन सैंपल में, इमेज, वीडियो फ़ाइलों, और लाइव स्ट्रीम के लिए, टास्क बनाने के अलग-अलग तरीके भी दिखाए गए हैं.
इमेज
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the image mode: options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.IMAGE) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
वीडियो
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the video mode: options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.VIDEO) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
लाइव स्ट्रीम
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions HandLandmarkerResult = mp.tasks.vision.HandLandmarkerResult VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the live stream mode: def print_result(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int): print('hand landmarker result: {}'.format(result)) options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.LIVE_STREAM, result_callback=print_result) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
इमेज के साथ इस्तेमाल करने के लिए, हाथ का लैंडमार्क बनाने का पूरा उदाहरण देखने के लिए, कोड का उदाहरण देखें.
कॉन्फ़िगरेशन विकल्प
इस टास्क में, Python ऐप्लिकेशन के लिए ये कॉन्फ़िगरेशन विकल्प हैं:
| विकल्प का नाम | ब्यौरा | वैल्यू की रेंज | डिफ़ॉल्ट मान |
|---|---|---|---|
running_mode |
टास्क के लिए रनिंग मोड सेट करता है. इसके तीन मोड हैं: IMAGE: एक इमेज इनपुट के लिए मोड. वीडियो: किसी वीडियो के डिकोड किए गए फ़्रेम के लिए मोड. LIVE_STREAM: कैमरे से मिले इनपुट डेटा की लाइव स्ट्रीम के लिए मोड. इस मोड में, नतीजे असींक्रोनस तरीके से पाने के लिए, एक listener सेट अप करने के लिए, resultListener को कॉल करना होगा. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_hands |
हाथ के लैंडमार्क डिटेक्टर की मदद से, ज़्यादा से ज़्यादा कितने हाथों की पहचान की जा सकती है. | Any integer > 0 |
1 |
min_hand_detection_confidence |
हाथ की पहचान करने के लिए, कम से कम इतना कॉन्फ़िडेंस स्कोर होना चाहिए, ताकि उसे हथेली की पहचान करने वाले मॉडल में सफल माना जा सके. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
हाथ के मौजूद होने के स्कोर के लिए, कम से कम कॉन्फ़िडेंस स्कोर. यह स्कोर, हाथ के लैंडमार्क का पता लगाने वाले मॉडल में दिखता है. वीडियो मोड और लाइव स्ट्रीम मोड में, अगर हाथ के लैंडमार्क मॉडल से हाथ की मौजूदगी का कॉन्फ़िडेंस स्कोर इस थ्रेशोल्ड से कम है, तो हाथ के लैंडमार्क की पहचान करने वाला टूल, हथेली की पहचान करने वाले मॉडल को ट्रिगर करता है. अगर ऐसा नहीं होता है, तो लैंडमार्क का पता लगाने के लिए, हाथ को ट्रैक करने वाला एक आसान एल्गोरिदम, हाथ की जगह का पता लगाता है. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
हाथ की ट्रैकिंग को कामयाब माना जा सके, इसके लिए कम से कम कॉन्फ़िडेंस स्कोर. यह मौजूदा फ़्रेम और आखिरी फ़्रेम में, हाथों के बीच के बॉउंडिंग बॉक्स का IoU थ्रेशोल्ड है. अगर हाथ के लैंडमार्क की सुविधा के वीडियो मोड और स्ट्रीम मोड में ट्रैकिंग नहीं हो पाती है, तो हाथ के लैंडमार्क की सुविधा, हाथ का पता लगाने की सुविधा को ट्रिगर करती है. ऐसा न करने पर, हाथ का पता लगाने की सुविधा काम नहीं करती. | 0.0 - 1.0 |
0.5 |
result_callback |
जब हाथ का लैंडमार्कर लाइव स्ट्रीम मोड में हो, तो पहचान के नतीजे पाने के लिए रिज़ल्ट लिसनर को असिंक्रोनस तरीके से सेट करता है.
यह सिर्फ़ तब लागू होता है, जब रनिंग मोड को LIVE_STREAM पर सेट किया गया हो |
लागू नहीं | लागू नहीं |
डेटा तैयार करना
अपने इनपुट को इमेज फ़ाइल या numpy ऐरे के तौर पर तैयार करें. इसके बाद, उसे mediapipe.Image ऑब्जेक्ट में बदलें. अगर आपका इनपुट कोई वीडियो फ़ाइल या वेबकैम से लाइव स्ट्रीम है, तो अपने इनपुट फ़्रेम को numpy ऐरे के तौर पर लोड करने के लिए, OpenCV जैसी किसी बाहरी लाइब्रेरी का इस्तेमाल किया जा सकता है.
इमेज
import mediapipe as mp # Load the input image from an image file. mp_image = mp.Image.create_from_file('/path/to/image') # Load the input image from a numpy array. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_image)
वीडियो
import mediapipe as mp # Use OpenCV’s VideoCapture to load the input video. # Load the frame rate of the video using OpenCV’s CV_CAP_PROP_FPS # You’ll need it to calculate the timestamp for each frame. # Loop through each frame in the video using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
लाइव स्ट्रीम
import mediapipe as mp # Use OpenCV’s VideoCapture to start capturing from the webcam. # Create a loop to read the latest frame from the camera using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
टास्क चलाना
अनुमान लगाने के लिए, हाथ के लैंडमार्क की सुविधा, detect, detect_for_video, और detect_async फ़ंक्शन का इस्तेमाल करती है. हाथ के लैंडमार्क का पता लगाने के लिए, इनपुट डेटा को पहले से प्रोसेस करना, इमेज में हाथों का पता लगाना, और हाथ के लैंडमार्क का पता लगाना शामिल है.
नीचे दिए गए कोड में, टास्क मॉडल की मदद से प्रोसेसिंग को लागू करने का तरीका बताया गया है.
इमेज
# Perform hand landmarks detection on the provided single image. # The hand landmarker must be created with the image mode. hand_landmarker_result = landmarker.detect(mp_image)
वीडियो
# Perform hand landmarks detection on the provided single image. # The hand landmarker must be created with the video mode. hand_landmarker_result = landmarker.detect_for_video(mp_image, frame_timestamp_ms)
लाइव स्ट्रीम
# Send live image data to perform hand landmarks detection. # The results are accessible via the `result_callback` provided in # the `HandLandmarkerOptions` object. # The hand landmarker must be created with the live stream mode. landmarker.detect_async(mp_image, frame_timestamp_ms)
निम्न पर ध्यान दें:
- वीडियो मोड या लाइव स्ट्रीम मोड में चलाने के दौरान, आपको हाथ के लैंडमार्क का पता लगाने वाले टास्क के लिए, इनपुट फ़्रेम का टाइमस्टैंप भी देना होगा.
- इमेज या वीडियो मॉडल में चलने पर, हाथ के लैंडमार्क का पता लगाने वाला टास्क, मौजूदा थ्रेड को तब तक ब्लॉक कर देगा, जब तक वह इनपुट इमेज या फ़्रेम को प्रोसेस नहीं कर लेता.
- लाइव स्ट्रीम मोड में चलने पर, हाथ के लैंडमार्क का टास्क मौजूदा थ्रेड को ब्लॉक नहीं करता, बल्कि तुरंत वापस आ जाता है. यह हर बार किसी इनपुट फ़्रेम को प्रोसेस करने के बाद, अपने नतीजे के लिसनर को, पहचान के नतीजे के साथ कॉल करेगा. अगर हाथ के लैंडमार्क का पता लगाने वाले टास्क के किसी फ़्रेम को प्रोसेस करने के दौरान, पहचान करने वाले फ़ंक्शन को कॉल किया जाता है, तो टास्क नए इनपुट फ़्रेम को अनदेखा कर देगा.
किसी इमेज पर हाथ के लैंडमार्कर को चलाने का पूरा उदाहरण देखने के लिए, ज़्यादा जानकारी के लिए कोड का उदाहरण देखें.
नतीजों को मैनेज और दिखाना
हाथ की गतिविधि का पता लगाने वाली सुविधा, हर बार पहचान करने के लिए, हाथ की गतिविधि का पता लगाने वाला नतीजा ऑब्जेक्ट जनरेट करती है. नतीजे के ऑब्जेक्ट में, इमेज के कोऑर्डिनेट में हाथ के लैंडमार्क, दुनिया के कोऑर्डिनेट में हाथ के लैंडमार्क, और पहचाने गए हाथों के लिए, बायां/दायां हाथ की जानकारी होती है.
यहां इस टास्क के आउटपुट डेटा का उदाहरण दिया गया है:
HandLandmarkerResult आउटपुट में तीन कॉम्पोनेंट होते हैं. हर कॉम्पोनेंट एक कलेक्शन होता है. इसमें हर एलिमेंट में, पहचाने गए एक हाथ के लिए ये नतीजे होते हैं:
किसी खास हाथ का इस्तेमाल
इस एट्रिब्यूट से पता चलता है कि पहचाने गए हाथ बाएं हैं या दाएं.
लैंडमार्क
हाथ के 21 लैंडमार्क हैं. हर लैंडमार्क में
x,y, औरzकोऑर्डिनेट होते हैं.xऔरyनिर्देशांक को इमेज की चौड़ाई और ऊंचाई के हिसाब से, [0.0, 1.0] पर नॉर्मलाइज़ किया जाता है.zनिर्देशांक, लैंडमार्क की गहराई दिखाता है. इसमें कलाई की गहराई को ऑरिजिन माना जाता है. वैल्यू जितनी कम होगी, लैंडमार्क कैमरे के उतना ही करीब होगा.zके मैग्नीट्यूड के लिए,xके स्केल का इस्तेमाल किया जाता है.विश्व भू-स्थल
हाथ के 21 लैंडमार्क, वर्ल्ड कोऑर्डिनेट में भी दिखाए जाते हैं. हर लैंडमार्क,
x,y, औरzसे बना होता है. यह मीटर में, असल दुनिया के 3D कोऑर्डिनेट दिखाता है. इसमें हाथ के ज्यामितीय केंद्र को ऑरिजिन माना जाता है.
HandLandmarkerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
नीचे दी गई इमेज में, टास्क के आउटपुट को विज़ुअलाइज़ किया गया है:
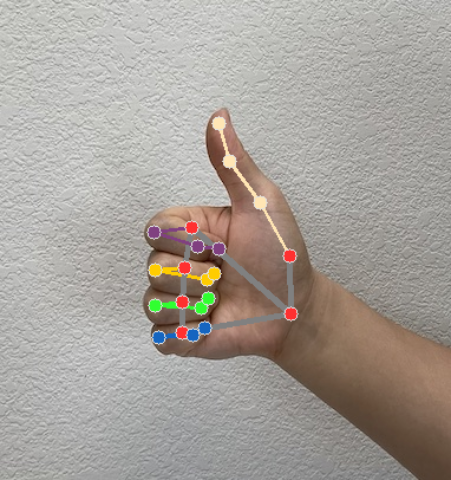
हाथ के लैंडमार्क का उदाहरण देने वाले कोड में, टास्क से मिले नतीजों को दिखाने का तरीका बताया गया है. ज़्यादा जानकारी के लिए, कोड का उदाहरण देखें.