
MediaPipe 雙手地標工作可讓您偵測圖片中的手部地標。 以下操作說明將為您示範如何使用指針 適用於網頁和 JavaScript 應用程式
進一步瞭解功能、模型和設定選項 請參閱總覽。
程式碼範例
這個例子提供了手部地標工具的 方便您參考。這個程式碼可協助您測試這項工作 您就可以開始打造自己的手部地標偵測應用程式您可以查看、執行 編輯手部地標程式碼範例 只要使用網路瀏覽器即可。
設定
本節說明設定開發環境的重要步驟 並特別針對該使用手冊如需 設定您的網路和 JavaScript 開發環境,包含 平台版本需求,請參閱 網頁版設定指南。
JavaScript 套件
你可以透過 MediaPipe @mediapipe/tasks-vision 取得手部地標代碼
NPM 套件。你可以
才能找到並下載這些程式庫。
設定指南。
您可以透過 NPM 安裝必要的套件 使用以下指令:
npm install @mediapipe/tasks-vision
如果想要透過內容傳遞網路 (CDN) 匯入工作程式碼 請在 <head> 加入下列程式碼代碼:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.js"
crossorigin="anonymous"></script>
</head>
型號
MediaPipe 雙手地標模型需要經過訓練的模型,且這個模型與 工作。如要進一步瞭解適用於手地標人員的已訓練模型,請參閱: 工作總覽的「模型」一節。
選取並下載模型,然後將模型儲存在專案目錄中:
<dev-project-root>/app/shared/models/
建立工作
使用手部地標 createFrom...() 函式之一來
準備執行推論的工作。使用「createFromModelPath()」
內含已訓練模型檔案的相對或絕對路徑。
如果模型已載入記憶體,您可以使用
createFromModelBuffer() 方法。
以下程式碼範例示範如何使用 createFromOptions() 函式
設定工作。createFromOptions 函式可讓您自訂
有設定選項的手部地標。進一步瞭解設定
選項,請參閱設定選項。
以下程式碼示範如何使用自訂選項建構及設定工作 選項:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm"
);
const handLandmarker = await HandLandmarker.createFromOptions(
vision,
{
baseOptions: {
modelAssetPath: "hand_landmarker.task"
},
numHands: 2
});
設定選項
這項工作包含以下網頁和 JavaScript 設定選項 應用程式:
| 選項名稱 | 說明 | 值範圍 | 預設值 |
|---|---|---|---|
runningMode |
設定任務的執行模式。這裡共有兩個
模式: 圖片:單一圖片輸入模式。 VIDEO:此模式適用於 影片或即時串流等輸入資料 (例如攝影機) 時 |
{IMAGE, VIDEO} |
IMAGE |
numHands |
手部地標偵測工具偵測到的手部數量上限。 | Any integer > 0 |
1 |
minHandDetectionConfidence |
手部偵測為 而且被認定為成功的手掌偵測模型 | 0.0 - 1.0 |
0.5 |
minHandPresenceConfidence |
手部在家狀態分數的最低可信度分數 地標偵測模型在影片模式和直播模式中 如果手部地標模型的可信度分數低於 這個門檻,會觸發手掌偵測模型否則, 輕量手動追蹤演算法會決定 手勢偵測後續的地標偵測。 | 0.0 - 1.0 |
0.5 |
minTrackingConfidence |
要考慮手部追蹤的最低可信度分數 成功。這是手中各部位的定界框 IoU 門檻 目前的影格和最後一個影格在影片模式和串流模式中, 手地標工 (如果追蹤失敗),手地標人員會親自採買 偵測。否則會略過手部偵測。 | 0.0 - 1.0 |
0.5 |
準備資料
安全地標可以偵測圖片中的手部地標,支援的格式為 主機瀏覽器。這項工作也會處理資料輸入預先處理作業,包括 調整大小、旋轉以及值正規化如要偵測影片中的手部地標, 您可以運用這個 API 的時間戳記, 判斷手部地標出現在影片中的時間。
執行工作
手部地標使用 detect() (執行跑步模式 image) 和
要觸發的 detectForVideo() (執行模式 video) 方法
推論出工作會處理資料、嘗試偵測手部地標,以及
然後回報結果
對手地標人員的 detect() 和 detectForVideo() 方法的呼叫都會執行
以及封鎖使用者介面執行緒如果偵測到手部地標
,每次偵測都會封鎖
。如要避免這種情況發生,您可以實作網路工作站來執行 detect()
和 detectForVideo() 方法
下列程式碼示範如何使用工作模型執行處理程序:
圖片
const image = document.getElementById("image") as HTMLImageElement; const handLandmarkerResult = handLandmarker.detect(image);
影片
await handLandmarker.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const detections = handLandmarker.detectForVideo(video); processResults(detections); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
如需更完整的實作「舉手地標」工作,請參閱 程式碼範例。
處理及顯示結果
手地標人員為每個偵測產生一個手部地標結果物件 此程序的第一步 是將程式碼簽入執行所有單元測試的存放區中結果物件包含圖片座標中的手部地標、手部 偵測出的世界座標和手部位置(左/右手) 。
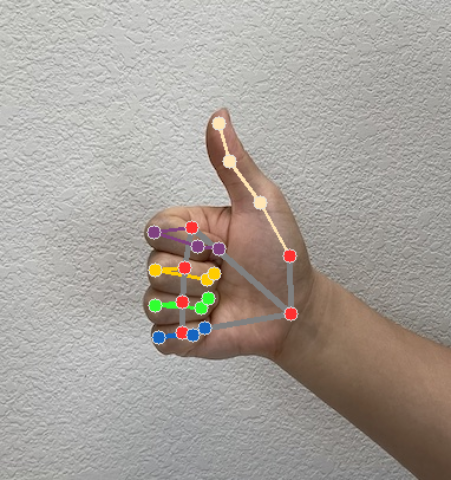
以下範例顯示這項工作的輸出資料範例:
HandLandmarkerResult 輸出內容包含三個元件。每個元件都是陣列,其中每個元素包含下列單一偵測到的手部結果:
慣用手設計
慣用手代表偵測到的手是左手還是右手。
地標
共有 21 個手部地標,每個地標都由
x、y和z座標組成。x和y座標會依照圖片寬度和z座標代表地標深度, 手腕的深度就是起點值越小, 地標就是相機鏡頭z的規模大致與下列指標相同:x。世界著名地標
世界座標也會顯示 21 個手部地標。每個地標 由
x、y和z組成,代表實際的 3D 座標 公尺,將感應器放在手部的幾何中心。
HandLandmarkerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
下圖是工作輸出內容的視覺化呈現:
實作地標程式碼範例,示範如何顯示 查看工作傳回的結果 程式碼範例