

La tarea de marcador de posición de pose de MediaPipe te permite detectar puntos de referencia de cuerpos humanos en una imagen o un video. Puedes usar esta tarea para identificar ubicaciones clave del cuerpo, analizar la postura y categorizar los movimientos. Esta tarea usa modelos de aprendizaje automático (AA) que trabajan con imágenes o videos individuales. La tarea genera puntos de referencia de la postura del cuerpo en coordenadas de imagen y en coordenadas mundiales tridimensionales.
Comenzar
Para comenzar a usar esta tarea, sigue la guía de implementación de tu plataforma de destino. En estas guías específicas de la plataforma, se explica una implementación básica de esta tarea, incluido un modelo recomendado y un ejemplo de código con las opciones de configuración recomendadas:
- Android: Ejemplo de código: Guía
- Python: Ejemplo de código: Guía
- Web: Ejemplo de código: Guía
Detalles de la tarea
En esta sección, se describen las capacidades, las entradas, las salidas y las opciones de configuración de esta tarea.
Funciones
- Procesamiento de imágenes de entrada: El procesamiento incluye la rotación de imágenes, el cambio de tamaño, la normalización y la conversión de espacios de color.
- Umbral de puntuación: Filtra los resultados según las puntuaciones de predicción.
| Entradas de tareas | Resultados de las tareas |
|---|---|
El marcador de posición acepta una entrada de uno de los siguientes tipos de datos:
|
El marcador de posición genera los siguientes resultados:
|
Opciones de configuración
Esta tarea tiene las siguientes opciones de configuración:
| Nombre de la opción | Descripción | Rango de valores | Valor predeterminado |
|---|---|---|---|
running_mode |
Establece el modo de ejecución de la tarea. Existen tres modos: IMAGE: Es el modo para entradas de una sola imagen. VIDEO: Es el modo para los fotogramas decodificados de un video. LIVE_STREAM: Es el modo de transmisión en vivo de datos de entrada, como los de una cámara. En este modo, se debe llamar a resultListener para configurar un objeto de escucha que reciba resultados de forma asíncrona. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Es la cantidad máxima de poses que puede detectar el marcador de poses. | Integer > 0 |
1 |
min_pose_detection_confidence |
Es la puntuación de confianza mínima para que la detección de poses se considere exitosa. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Es la puntuación de confianza mínima de la puntuación de presencia de pose en la detección de puntos de referencia de pose. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Es la puntuación de confianza mínima para que el seguimiento de poses se considere exitoso. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Indica si el marcador de posición genera una máscara de segmentación para la posición detectada. | Boolean |
False |
result_callback |
Establece el objeto de escucha de resultados para que reciba los resultados del marcador de posición de forma asíncrona cuando el marcador de posición de pose esté en el modo de transmisión en vivo.
Solo se puede usar cuando el modo de ejecución está configurado como LIVE_STREAM. |
ResultListener |
N/A |
Modelos
El marcador de poses usa una serie de modelos para predecir los marcadores de poses. El primer modelo detecta la presencia de cuerpos humanos dentro de un fotograma de imagen, y el segundo modelo localiza puntos de referencia en los cuerpos.
Los siguientes modelos se empaquetan en un paquete de modelos descargable:
- Modelo de detección de poses: Detecta la presencia de cuerpos con algunos puntos de referencia de poses clave.
- Modelo de marcador de pose: Agrega una asignación completa de la pose. El modelo genera una estimación de 33 puntos de referencia de pose 3D.
Este paquete usa una red neuronal convolucional similar a MobileNetV2 y está optimizado para aplicaciones de fitness en tiempo real en el dispositivo. Esta variante del modelo BlazePose usa GHUM, una canalización de modelado de formas humanas en 3D, para estimar la postura corporal 3D completa de una persona en imágenes o videos.
| Paquete de modelos | Forma de entrada | Tipo de datos | Tarjetas de modelo | Versiones |
|---|---|---|---|---|
| Marcador de posición (ligero) | Detector de poses: 224 x 224 x 3 Marcador de poses: 256 x 256 x 3 |
Número de punto flotante 16 | info | Más reciente |
| Marcador de posición (completo) | Detector de poses: 224 x 224 x 3 Marcador de poses: 256 x 256 x 3 |
Número de punto flotante 16 | info | Más reciente |
| Marcador de posición (intenso) | Detector de poses: 224 x 224 x 3 Marcador de poses: 256 x 256 x 3 |
Número de punto flotante 16 | info | Más reciente |
Modelo de marcador de posición
El modelo de marcador de pose realiza un seguimiento de 33 ubicaciones de puntos de referencia del cuerpo, que representan la ubicación aproximada de las siguientes partes del cuerpo:
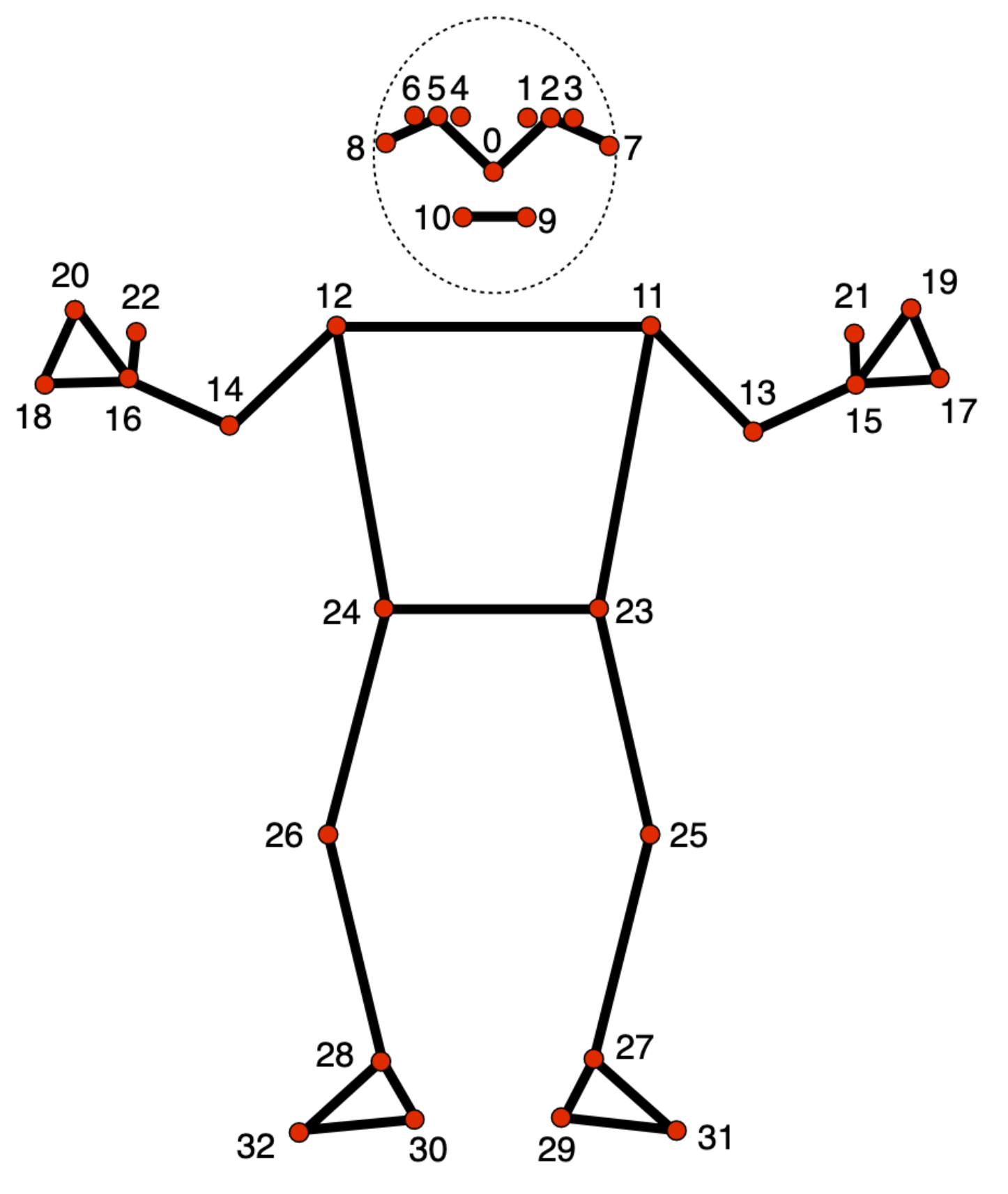
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
El resultado del modelo contiene coordenadas normalizadas (Landmarks) y coordenadas mundiales (WorldLandmarks) para cada punto de referencia.