

A tarefa MediaPipe Pose Landmarker permite detectar pontos de referência de corpos humanos em uma imagem ou vídeo. Você pode usar essa tarefa para identificar os principais locais do corpo, analisar a postura e categorizar os movimentos. Esta tarefa usa modelos de aprendizado de máquina (ML) que funcionam com imagens ou vídeos únicos. A tarefa gera pontos de referência da pose do corpo em coordenadas de imagem e em coordenadas mundiais tridimensionais.
Começar
Para começar a usar essa tarefa, siga o guia de implementação da plataforma de destino. Estes guias específicos para plataformas orientam você em uma implementação básica desta tarefa, incluindo um modelo recomendado e um exemplo de código com opções de configuração recomendadas:
- Android: exemplo de código - guia
- Python: exemplo de código - guia
- Web: exemplo de código: guia
Detalhes da tarefa
Esta seção descreve os recursos, entradas, saídas e opções de configuração desta tarefa.
Recursos
- Processamento de imagens de entrada: inclui rotação, redimensionamento, normalização e conversão de espaço de cor.
- Limite de pontuação: filtre os resultados com base nas pontuações de previsão.
| Entradas da tarefa | Saídas de tarefas |
|---|---|
O Pose Landmarker aceita uma entrada de um dos seguintes tipos de dados:
|
O Pose Landmarker gera os seguintes resultados:
|
Opções de configuração
Esta tarefa tem as seguintes opções de configuração:
| Nome da opção | Descrição | Intervalo de valor | Valor padrão |
|---|---|---|---|
running_mode |
Define o modo de execução da tarefa. Há três
modos: IMAGE: o modo para entradas de imagem única. VÍDEO: o modo para quadros decodificados de um vídeo. LIVE_STREAM: o modo de uma transmissão ao vivo de dados de entrada, como de uma câmera. Nesse modo, o resultListener precisa ser chamado para configurar um listener para receber resultados de forma assíncrona. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
O número máximo de poses que podem ser detectadas pelo Pose Landmarker. | Integer > 0 |
1 |
min_pose_detection_confidence |
A pontuação de confiança mínima para que a detecção de pose seja considerada bem-sucedida. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
O valor de confiança mínimo da pontuação de presença de pose na detecção de marco de pose. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
A pontuação de confiança mínima para que o rastreamento de pose seja considerado bem-sucedido. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Indica se o Pose Landmarker vai gerar uma máscara de segmentação para a pose detectada. | Boolean |
False |
result_callback |
Define o listener de resultado para receber os resultados do marcador de posição de forma assíncrona quando o marcador de posição de pose está no modo de transmissão ao vivo.
Só pode ser usado quando o modo de execução está definido como LIVE_STREAM. |
ResultListener |
N/A |
Modelos
O Pose Landmarker usa uma série de modelos para prever pontos de referência de pose. O primeiro modelo detecta a presença de corpos humanos em um frame de imagem, e o segundo modelo localiza pontos de referência nos corpos.
Os modelos a seguir são agrupados em um pacote de modelos para download:
- Modelo de detecção de pose: detecta a presença de corpos com alguns pontos de referência principais da pose.
- Modelo de marcador de pose: adiciona um mapeamento completo da pose. O modelo exibe uma estimativa de 33 pontos de referência de pose tridimensionais.
Esse pacote usa uma rede neural convolucional semelhante à MobileNetV2 e é otimizado para aplicativos de condicionamento físico em tempo real no dispositivo. Essa variante do modelo BlazePose usa o GHUM, um pipeline de modelagem de forma humana em 3D, para estimar a pose corporal completa em 3D de um indivíduo em imagens ou vídeos.
| Pacote de modelos | Forma de entrada | Tipo de dado | Cards de modelo | Versões |
|---|---|---|---|---|
| Pose landmarker (lite) | Detector de pose: 224 x 224 x 3 Marcador de pose: 256 x 256 x 3 |
float 16 | informações | Mais recente |
| Pose landmarker (completo) | Detector de pose: 224 x 224 x 3 Marcador de pose: 256 x 256 x 3 |
float 16 | informações | Mais recente |
| Pose landmarker (intenso) | Detector de pose: 224 x 224 x 3 Marcador de pose: 256 x 256 x 3 |
float 16 | informações | Mais recente |
Posicionar o modelo de ponto de referência
O modelo de marcador de pose rastreia 33 locais de marcadores corporais, representando o local aproximado das seguintes partes do corpo:
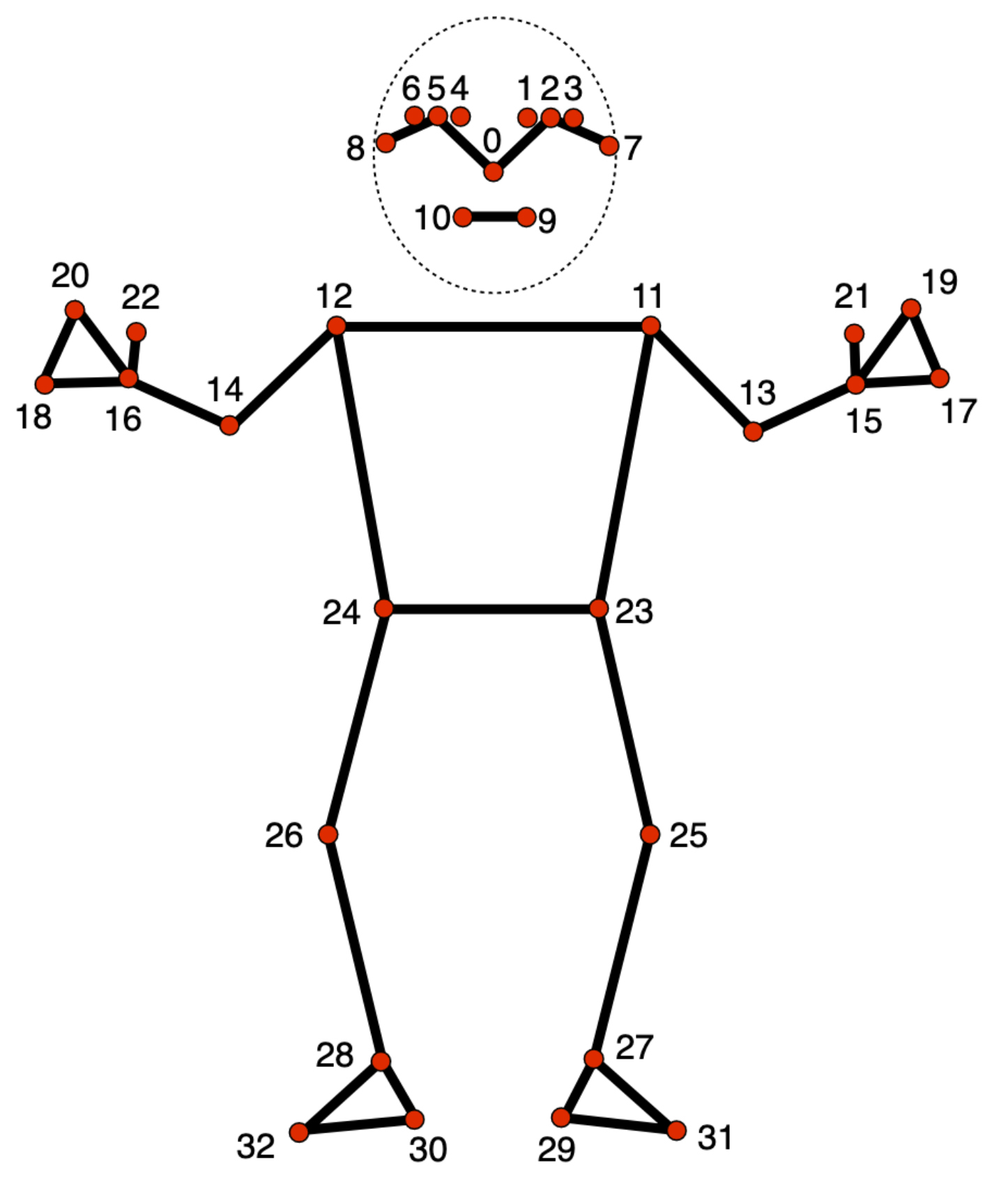
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
A saída do modelo contém coordenadas normalizadas (Landmarks) e coordenadas do mundo (WorldLandmarks) para cada ponto de referência.