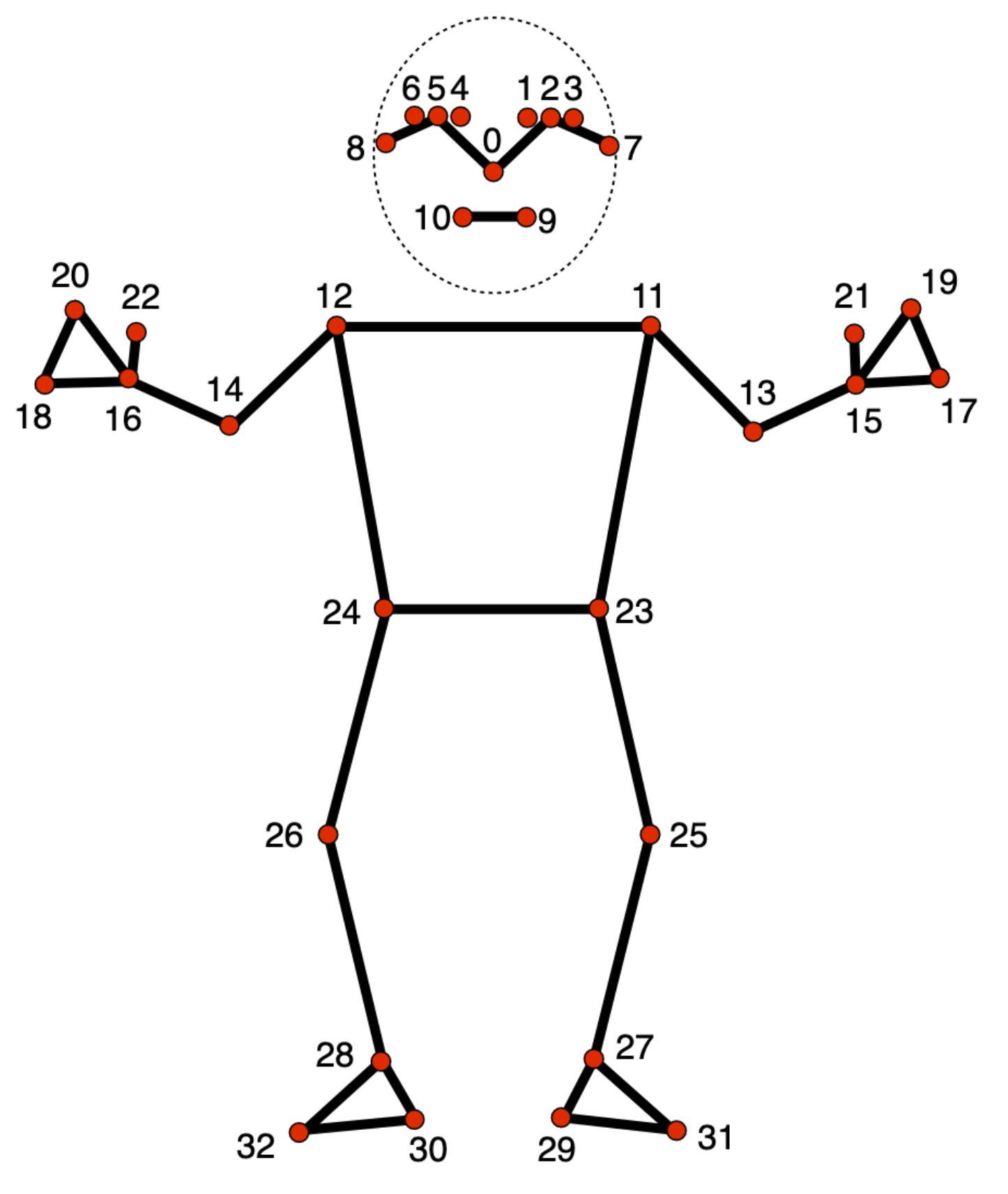
MediaPipe Pose Landmarker টাস্ক আপনাকে একটি ছবি বা ভিডিওতে মানবদেহের ল্যান্ডমার্ক সনাক্ত করতে দেয়। আপনি শরীরের মূল অবস্থানগুলি সনাক্ত করতে, অঙ্গবিন্যাস বিশ্লেষণ করতে এবং আন্দোলনগুলিকে শ্রেণীবদ্ধ করতে এই কাজটি ব্যবহার করতে পারেন। এই কাজটি মেশিন লার্নিং (ML) মডেল ব্যবহার করে যা একক ছবি বা ভিডিওর সাথে কাজ করে। টাস্কটি ইমেজ কোঅর্ডিনেট এবং 3-ডাইমেনশনাল ওয়ার্ল্ড কোঅর্ডিনেটে বডি পোজ ল্যান্ডমার্ককে আউটপুট করে।
শুরু করুন
আপনার লক্ষ্য প্ল্যাটফর্মের জন্য বাস্তবায়ন নির্দেশিকা অনুসরণ করে এই কাজটি ব্যবহার করা শুরু করুন। এই প্ল্যাটফর্ম-নির্দিষ্ট নির্দেশিকাগুলি আপনাকে এই টাস্কের একটি প্রাথমিক বাস্তবায়নের মাধ্যমে নিয়ে যায়, যার মধ্যে একটি প্রস্তাবিত মডেল এবং প্রস্তাবিত কনফিগারেশন বিকল্পগুলির সাথে কোড উদাহরণ রয়েছে:
- অ্যান্ড্রয়েড - কোড উদাহরণ - গাইড
- পাইথন - কোড উদাহরণ - গাইড
- ওয়েব - কোড উদাহরণ - গাইড
টাস্কের বিবরণ
এই বিভাগটি এই কাজের ক্ষমতা, ইনপুট, আউটপুট এবং কনফিগারেশন বিকল্পগুলি বর্ণনা করে।
বৈশিষ্ট্য
- ইনপুট ইমেজ প্রসেসিং - প্রসেসিং এর মধ্যে রয়েছে ইমেজ রোটেশন, রিসাইজ, নরমালাইজেশন এবং কালার স্পেস কনভার্সন।
- স্কোর থ্রেশহোল্ড - পূর্বাভাস স্কোরের উপর ভিত্তি করে ফলাফল ফিল্টার করুন।
| টাস্ক ইনপুট | টাস্ক আউটপুট |
|---|---|
পোজ ল্যান্ডমার্কার নিম্নলিখিত ডেটা প্রকারগুলির একটির একটি ইনপুট গ্রহণ করে:
| পোজ ল্যান্ডমার্কার নিম্নলিখিত ফলাফলগুলি আউটপুট করে:
|
কনফিগারেশন অপশন
এই কাজের নিম্নলিখিত কনফিগারেশন বিকল্প আছে:
| বিকল্পের নাম | বর্ণনা | মান পরিসীমা | ডিফল্ট মান |
|---|---|---|---|
running_mode | টাস্কের জন্য চলমান মোড সেট করে। তিনটি মোড আছে: IMAGE: একক ইমেজ ইনপুট জন্য মোড. ভিডিও: একটি ভিডিওর ডিকোড করা ফ্রেমের মোড। লাইভ_স্ট্রিম: ইনপুট ডেটার লাইভস্ট্রিমের মোড, যেমন ক্যামেরা থেকে। এই মোডে, ফলাফল শ্রোতাকে অ্যাসিঙ্ক্রোনাসভাবে ফলাফল পেতে একটি শ্রোতা সেট আপ করতে কল করতে হবে। | { IMAGE, VIDEO, LIVE_STREAM } | IMAGE |
num_poses | পোজ ল্যান্ডমার্কার দ্বারা সনাক্ত করা যেতে পারে এমন সর্বোচ্চ সংখ্যক পোজ। | Integer > 0 | 1 |
min_pose_detection_confidence | ভঙ্গি সনাক্তকরণের জন্য ন্যূনতম আত্মবিশ্বাসের স্কোর সফল বলে বিবেচিত হবে। | Float [0.0,1.0] | 0.5 |
min_pose_presence_confidence | পোজ ল্যান্ডমার্ক সনাক্তকরণে পোজ উপস্থিতি স্কোরের সর্বনিম্ন আত্মবিশ্বাসের স্কোর। | Float [0.0,1.0] | 0.5 |
min_tracking_confidence | পোজ ট্র্যাকিংয়ের জন্য ন্যূনতম আত্মবিশ্বাসের স্কোর সফল বলে বিবেচিত হবে। | Float [0.0,1.0] | 0.5 |
output_segmentation_masks | পোজ ল্যান্ডমার্কার সনাক্ত করা পোজের জন্য একটি বিভাজন মাস্ক আউটপুট করে কিনা। | Boolean | False |
result_callback | Pose Landmarker যখন লাইভ স্ট্রিম মোডে থাকে তখন ল্যান্ডমার্কারের ফলাফল অ্যাসিঙ্ক্রোনাসভাবে পেতে ফলাফল শ্রোতাকে সেট করে। চলমান মোড LIVE_STREAM এ সেট করা থাকলেই কেবল ব্যবহার করা যাবে৷ | ResultListener | N/A |
মডেল
পোজ ল্যান্ডমার্কার পোজ ল্যান্ডমার্কের ভবিষ্যদ্বাণী করতে মডেলের একটি সিরিজ ব্যবহার করে। প্রথম মডেলটি একটি ইমেজ ফ্রেমের মধ্যে মানবদেহের উপস্থিতি সনাক্ত করে এবং দ্বিতীয় মডেলটি মৃতদেহের উপর ল্যান্ডমার্ক সনাক্ত করে।
নিম্নলিখিত মডেলগুলি একটি ডাউনলোডযোগ্য মডেল বান্ডিলে একসাথে প্যাকেজ করা হয়েছে:
- ভঙ্গি সনাক্তকরণ মডেল : কয়েকটি মূল পোজ ল্যান্ডমার্ক সহ দেহের উপস্থিতি সনাক্ত করে।
- পোজ ল্যান্ডমার্কার মডেল : ভঙ্গির একটি সম্পূর্ণ ম্যাপিং যোগ করে। মডেলটি 33টি 3-মাত্রিক পোজ ল্যান্ডমার্কের একটি অনুমান আউটপুট করে।
এই বান্ডিলটি MobileNetV2 এর মতো একটি কনভোল্যুশনাল নিউরাল নেটওয়ার্ক ব্যবহার করে এবং অন-ডিভাইস, রিয়েল-টাইম ফিটনেস অ্যাপ্লিকেশনের জন্য অপ্টিমাইজ করা হয়েছে। BlazePose মডেলের এই রূপটি GHUM ব্যবহার করে, একটি 3D মানব আকৃতির মডেলিং পাইপলাইন, ছবি বা ভিডিওতে একজন ব্যক্তির সম্পূর্ণ 3D বডি পোজ অনুমান করতে।
| মডেল বান্ডিল | ইনপুট আকৃতি | ডেটা টাইপ | মডেল কার্ড | সংস্করণ |
|---|---|---|---|---|
| পোজ ল্যান্ডমার্কার (লাইট) | পোজ ডিটেক্টর: 224 x 224 x 3 পোজ ল্যান্ডমার্কার: 256 x 256 x 3 | ভাসা 16 | তথ্য | সর্বশেষ |
| পোজ ল্যান্ডমার্কার (সম্পূর্ণ) | পোজ ডিটেক্টর: 224 x 224 x 3 পোজ ল্যান্ডমার্কার: 256 x 256 x 3 | ভাসা 16 | তথ্য | সর্বশেষ |
| পোজ ল্যান্ডমার্কার (ভারী) | পোজ ডিটেক্টর: 224 x 224 x 3 পোজ ল্যান্ডমার্কার: 256 x 256 x 3 | ভাসা 16 | তথ্য | সর্বশেষ |