
|
|
|
 Quelle auf GitHub ansehen Quelle auf GitHub ansehen
|
Überblick
In dieser Anleitung wird gezeigt, wie Sie Clustering mit den Einbettungen aus der Gemini API visualisieren und ausführen. Sie visualisieren eine Teilmenge der 20 Newsgroup-Datasets mithilfe von t-SNE und gruppieren diese Teilmenge mithilfe des KMeans-Algorithmus.
Weitere Informationen zu den ersten Schritten mit Einbettungen, die mit der Gemini API generiert werden, finden Sie in der Python-Kurzanleitung.
Voraussetzungen
Sie können diese Kurzanleitung in Google Colab ausführen.
Wenn Sie diese Kurzanleitung in Ihrer eigenen Entwicklungsumgebung ausführen möchten, muss Ihre Umgebung die folgenden Anforderungen erfüllen:
- Python 3.9 oder höher
- Eine Installation von
jupyterzum Ausführen des Notebooks.
Einrichtung
Laden Sie zuerst die Gemini API-Python-Bibliothek herunter und installieren Sie sie.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
API-Schlüssel anfordern
Bevor Sie die Gemini API verwenden können, müssen Sie einen API-Schlüssel abrufen. Wenn Sie noch keinen Schlüssel haben, können Sie mit einem Klick in Google AI Studio einen Schlüssel erstellen.
Fügen Sie den Schlüssel in Colab dem Secret-Manager unter "🚀" im linken Steuerfeld hinzu. Geben Sie ihr den Namen API_KEY.
Sobald Sie den API-Schlüssel haben, übergeben Sie ihn an das SDK. Dafür haben Sie die beiden folgenden Möglichkeiten:
- Fügen Sie den Schlüssel in die Umgebungsvariable
GOOGLE_API_KEYein. Das SDK ruft ihn dort automatisch ab. - Übergib den Schlüssel an
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Dataset
Das Text-Dataset für 20 Newsgroups enthält 18.000 Newsgroups zu 20 Themen,die in Trainings- und Test-Datasets aufgeteilt sind. Die Aufteilung zwischen Trainings- und Test-Datasets basiert auf Nachrichten, die vor und nach einem bestimmten Datum veröffentlicht wurden. In dieser Anleitung verwenden Sie die Trainingsteilmenge.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Hier ist das erste Beispiel im Trainings-Dataset.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Als Nächstes nehmen Sie Stichproben aus einigen Daten, indem Sie 100 Datenpunkte im Trainings-Dataset verwenden und einige der Kategorien auslassen, die im Rahmen dieser Anleitung ausgeführt werden sollen. Wähle die Wissenschaftskategorien aus, die du vergleichen möchtest.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Einbettungen erstellen
In diesem Abschnitt erfahren Sie, wie Sie mithilfe der Einbettungen aus der Gemini API Einbettungen für die verschiedenen Texte im DataFrame generieren.
API-Änderungen an Einbettungen mit Modellembedding-001
Für das neue Einbettungsmodell „embedding-001“ gibt es einen neuen Aufgabentypparameter und den optionalen Titel (nur gültig bei „task_type=RETRIEVAL_DOCUMENT“).
Diese neuen Parameter gelten nur für die neuesten Einbettungsmodelle.Es gibt folgende Aufgabentypen:
| Aufgabentyp | Beschreibung |
|---|---|
| RETRIEVAL_QUERY | Gibt an, dass der angegebene Text eine Abfrage in einer Such-/Abrufeinstellung ist. |
| RETRIEVAL_DOCUMENT | Gibt an, dass der angegebene Text ein Dokument in einer Such-/Abrufeinstellung ist. |
| SEMANTIC_SIMILARITY | Gibt an, dass der angegebene Text für die Bestimmung der semantischen Textähnlichkeit (Semantic Textual Similarity, STS) verwendet wird. |
| KLASSIFIZIERUNG | Gibt an, dass die Einbettungen zur Klassifizierung verwendet werden. |
| Clustering | Gibt an, dass die Einbettungen für das Clustering verwendet werden. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Dimensionalitätsreduktion
Die Länge des Dokumenteinbettungsvektors beträgt 768. Um zu visualisieren, wie die eingebetteten Dokumente gruppiert werden, müssen Sie die Dimensionalität reduzieren, da die Einbettungen nur im 2D- oder 3D-Raum visualisiert werden können. Kontextbezogene ähnliche Dokumente sollten räumlich näher beieinander liegen, im Gegensatz zu Dokumenten, die sich nicht so ähnlich sind.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
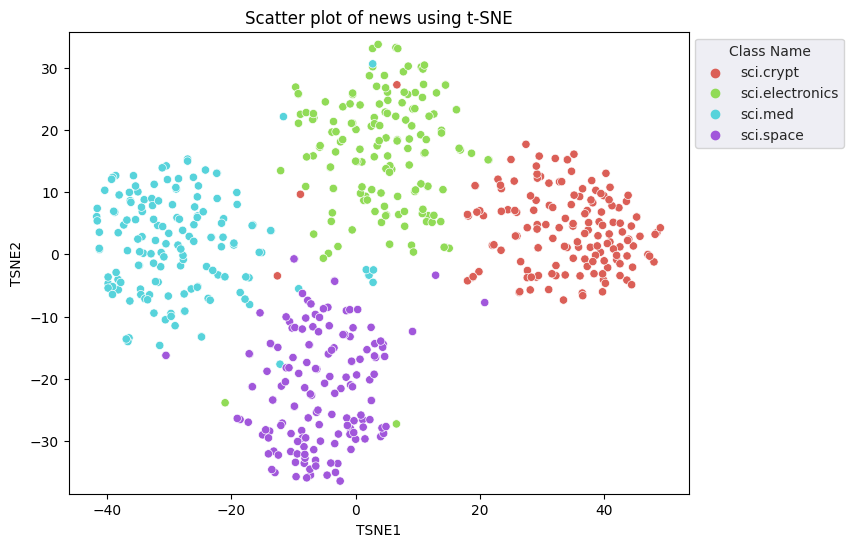
Sie wenden den t-Distributed Stochastic Neighbor Embedding (t-SNE)-Ansatz an, um eine Dimensionalitätsreduzierung durchzuführen. Mit diesem Verfahren wird die Anzahl der Dimensionen reduziert und gleichzeitig Cluster erhalten (d. h. nahe beieinander liegende Punkte bleiben nah beieinander). Für die Originaldaten versucht das Modell, eine Verteilung zu konstruieren, für die andere Datenpunkte „Nachbarn“ sind (z.B. haben sie eine ähnliche Bedeutung). Dann wird eine Zielfunktion optimiert, um eine ähnliche Verteilung in der Visualisierung beizubehalten.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Ergebnisse mit KMeans vergleichen
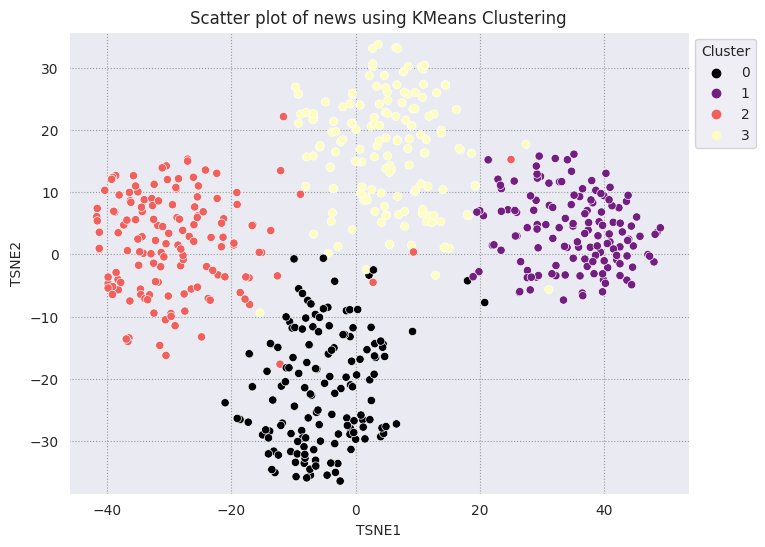
KMeans-Clustering ist ein beliebter Clustering-Algorithmus, der häufig für unüberwachtes Lernen verwendet wird. Sie ermittelt iterativ die besten k-Mittelpunkte und weist jedes Beispiel dem nächstgelegenen Schwerpunkt zu. Geben Sie die Einbettungen direkt in den KMeans-Algorithmus ein, um die Visualisierung der Einbettungen mit der Leistung eines Algorithmus für maschinelles Lernen zu vergleichen.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Ermitteln Sie die Mehrheit der Cluster pro Gruppe und sehen Sie sich an, wie viele Mitglieder der Gruppe sich tatsächlich in diesem Cluster befinden.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
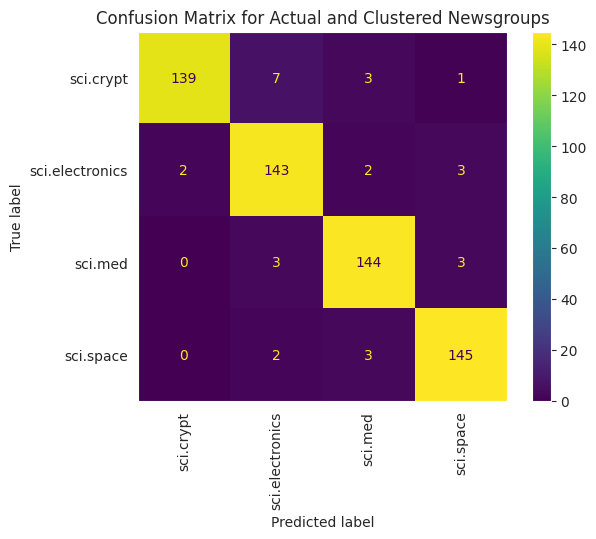
Um die Leistung der auf Ihre Daten angewendeten KMeans besser zu visualisieren, können Sie eine Wahrheitsmatrix verwenden. Mit der Wahrheitsmatrix können Sie die Leistung des Klassifizierungsmodells über die Genauigkeit hinaus bewerten. Sie können sehen, als falsch klassifizierte Punkte klassifiziert werden. Sie benötigen die tatsächlichen Werte und die vorhergesagten Werte, die Sie im obigen DataFrame gesammelt haben.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Nächste Schritte
Sie haben jetzt Ihre eigene Visualisierung von Einbettungen mit Clustering erstellt. Versuchen Sie, Ihre eigenen Textdaten als Einbettungen zu visualisieren. Sie können die Dimensionalität reduzieren, um den Visualisierungsschritt abzuschließen. Beachten Sie, dass sich TSNE gut für das Clustering von Eingaben eignet, die Konvergierung jedoch länger dauern kann oder bei der lokalen Minima feststecken kann. Wenn dieses Problem auftritt, können Sie auch die Hauptkomponentenanalyse (PCA) verwenden.
Neben KMeans gibt es noch weitere Clustering-Algorithmen, zum Beispiel density-based Spatial Clustering (DBSCAN).
Weitere Informationen zur Verwendung von Einbettungen finden Sie in diesen anderen Anleitungen: