
|
|
|
 GitHub पर सोर्स देखें GitHub पर सोर्स देखें
|
खास जानकारी
इस ट्यूटोरियल में बताया गया है कि Gemini API की मदद से एम्बेड किए गए डेटा के साथ, क्लस्टरिंग को कैसे विज़ुअलाइज़ किया जा सकता है. t-SNE का इस्तेमाल करके और ऐसे क्लस्टर का इस्तेमाल करके, 20 न्यूज़ग्रुप डेटासेट के एक सबसेट को विज़ुअलाइज़ किया जाएगा जो KMeans एल्गोरिदम का इस्तेमाल करता है.
Gemini API की मदद से जनरेट किए गए एम्बेड करने के तरीके के बारे में ज़्यादा जानने के लिए, Python क्विकस्टार्ट लेख पढ़ें.
ज़रूरी शर्तें
इस क्विकस्टार्ट को Google Colab में चलाया जा सकता है.
अपने डेवलपमेंट एनवायरमेंट में इस क्विकस्टार्ट को पूरा करने के लिए, पक्का करें कि आपका माहौल इन शर्तों को पूरा करता हो:
- Python 3.9 और इसके बाद के वर्शन
- notebook चलाने के लिए
jupyterका इंस्टॉलेशन.
सेटअप
सबसे पहले, Gemini API Python लाइब्रेरी को डाउनलोड और इंस्टॉल करें.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
कोई API कुंजी पाएं
Gemini API का इस्तेमाल करने से पहले, आपको एपीआई पासकोड हासिल करना होगा. अगर आपके पास पहले से कोई कुंजी नहीं है, तो Google AI Studio में सिर्फ़ एक क्लिक करके कुंजी बनाएं.
Colab में, सीक्रेट मैनेजर में बाईं ओर मौजूद पैनल में " दिलचस्पी" में जाकर कुंजी जोड़ें. इसे API_KEY नाम दें.
एपीआई पासकोड मिलने के बाद, उसे SDK टूल को पास करें. आप इसे दो तरीकों से कर सकते हैं:
- कुंजी को
GOOGLE_API_KEYके एनवायरमेंट वैरिएबल में डालें. SDK टूल इसे वहां से अपने-आप चुन लेगा. - कुंजी को
genai.configure(api_key=...)पर पास करें
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
डेटासेट
20 न्यूज़ग्रुप टेक्स्ट डेटासेट में 20 विषयों पर 18,000 न्यूज़ग्रुप पोस्ट हैं. इन्हें ट्रेनिंग और टेस्ट सेट में बांटा गया है. ट्रेनिंग और टेस्ट डेटासेट के बीच फ़र्क़, किसी खास तारीख से पहले और बाद में पोस्ट किए गए मैसेज के आधार पर तय होता है. इस ट्यूटोरियल के लिए, आपको ट्रेनिंग सबसेट का इस्तेमाल करना होगा.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
ट्रेनिंग सेट में दिया गया पहला उदाहरण यहां दिया गया है.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
इसके बाद, आपको ट्रेनिंग डेटासेट में 100 डेटा पॉइंट लेकर, इस ट्यूटोरियल को चलाने के लिए कुछ डेटा को कैटगरी में छोड़ना होगा. तुलना करने के लिए विज्ञान की कैटगरी चुनें.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
एम्बेड करना
इस सेक्शन में, आपको Gemini API की मदद से एम्बेड किए गए डेटा का इस्तेमाल करके, डेटाफ़्रेम में अलग-अलग टेक्स्ट के लिए एम्बेड करने के तरीके के बारे में बताया जाएगा.
मॉडल एम्बेडिंग-001 के साथ एम्बेडिंग में एपीआई में बदलाव
एम्बेड करने वाले नए मॉडल, एम्बेड-001 के लिए, एक नया टास्क टाइप पैरामीटर और वैकल्पिक शीर्षक उपलब्ध है (सिर्फ़ Task_type=RETRIEVAL_DOCUMENT के साथ मान्य है).
ये नए पैरामीटर सिर्फ़ एम्बेड किए गए नए मॉडल पर लागू होते हैं.ये टास्क इस तरह के हैं:
| टास्क किस तरह का है | ब्यौरा |
|---|---|
| RETRIEVAL_QUERY | तय करता है कि दिया गया टेक्स्ट किसी खोज/उपयोगकर्ता हासिल करने की सेटिंग में मौजूद क्वेरी है. |
| RETRIEVAL_DOCUMENT | तय करता है कि दिया गया टेक्स्ट खोज/वापस पाने की सेटिंग में मौजूद एक दस्तावेज़ है. |
| SEMANTIC_SIMILARITY | इससे यह तय होता है कि दिए गए टेक्स्ट का इस्तेमाल सिमैंटिक टेक्स्ट वाली समानता (एसटीएस) के लिए किया जाएगा. |
| कैटगरी तय करना | इससे यह पता चलता है कि एम्बेड किए गए लिंक का इस्तेमाल, कैटगरी तय करने के लिए किया जाएगा. |
| क्लस्टरिंग | इससे यह पता चलता है कि एम्बेड किए गए लिंक का इस्तेमाल, क्लस्टरिंग के लिए किया जाएगा. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
डाइमेंशनलिटी रिडक्शन
दस्तावेज़ एम्बेड करने वाले वेक्टर की लंबाई 768 है. एम्बेड किए गए दस्तावेज़ों को एक साथ ग्रुप करने के तरीके को देखने के लिए, आपको डाइमेंशन की वैल्यू कम करने की सुविधा लागू करनी होगी. ऐसा इसलिए, क्योंकि एम्बेड किए गए दस्तावेज़ों को सिर्फ़ 2D या 3D स्पेस में देखा जा सकता है. कॉन्टेक्स्ट के हिसाब से मिलते-जुलते दस्तावेज़, एक जैसे न होने वाले दस्तावेज़ों के बजाय स्पेस में एक-दूसरे के करीब होने चाहिए.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
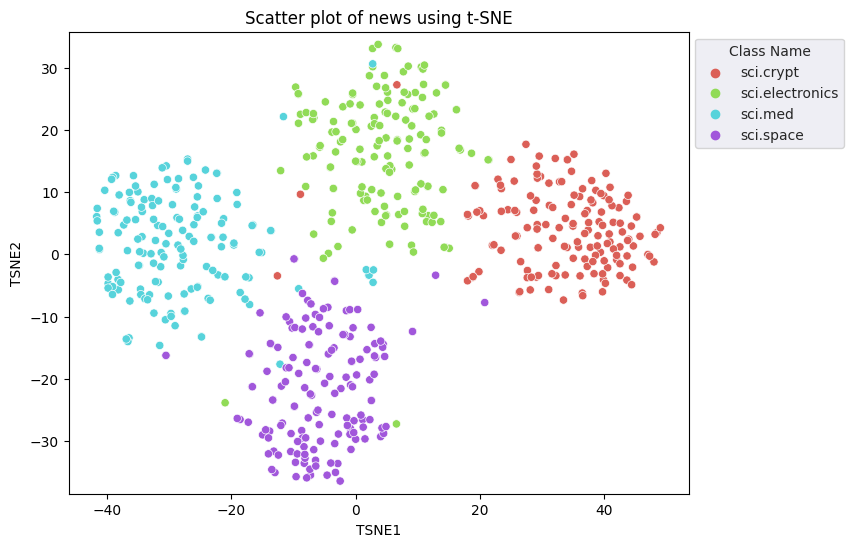
डाइमेंशनलिटी को कम करने के लिए, t-डिस्ट्रिब्यूटेड स्टोकेस्टिक नेबर एम्बेडिंग (t-SNE) की रणनीति का इस्तेमाल किया जा सकता है. यह तकनीक क्लस्टर को बचाते हुए, डाइमेंशन की संख्या कम कर देती है. ऐसे पॉइंट जो एक-दूसरे के करीब रहते हैं वे एक-दूसरे के करीब रहते हैं. ओरिजनल डेटा के लिए, मॉडल ऐसा डिस्ट्रिब्यूशन बनाने की कोशिश करता है जिसके हिसाब से अन्य डेटा पॉइंट "पड़ोसी" हों. उदाहरण के लिए, उनका मतलब एक जैसा है. इसके बाद, यह विज़ुअलाइज़ेशन में एक जैसा डिस्ट्रिब्यूशन बनाए रखने के लिए, मकसद फ़ंक्शन को ऑप्टिमाइज़ करता है.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
नतीजों की तुलना KMEAN से करें
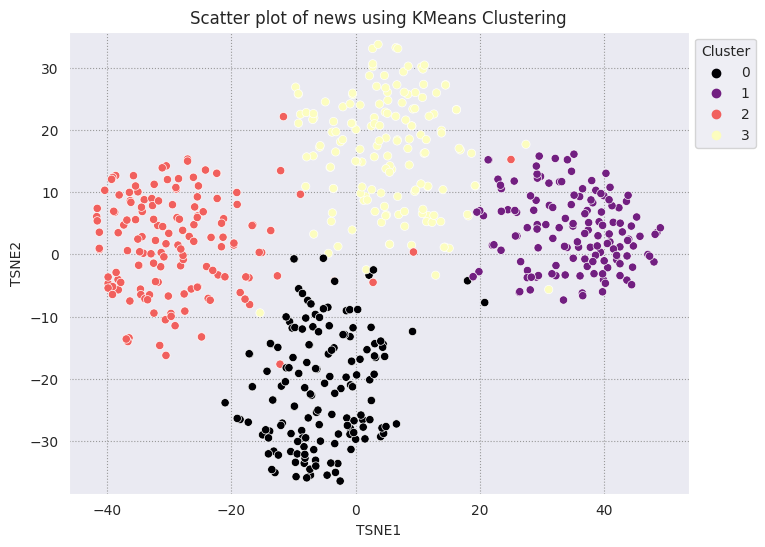
KMEAN क्लस्टरिंग, क्लस्टरिंग के लिए इस्तेमाल किया जाने वाला एक लोकप्रिय एल्गोरिदम है. इसका इस्तेमाल, अक्सर बिना निगरानी वाले लर्निंग के लिए किया जाता है. यह बार-बार सबसे अच्छे k सेंटर पॉइंट तय करता है और हर उदाहरण को सबसे नज़दीकी सेंट्रोइड को असाइन करता है. एम्बेड किए गए डेटा को सीधे KMians एल्गोरिदम में डालें, ताकि एम्बेड किए गए डेटा के विज़ुअलाइज़ेशन की तुलना, मशीन लर्निंग एल्गोरिदम की परफ़ॉर्मेंस से की जा सके.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
हर ग्रुप के ज़्यादातर क्लस्टर पाएं और देखें कि उस क्लस्टर में उस ग्रुप के कितने असल सदस्य हैं.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
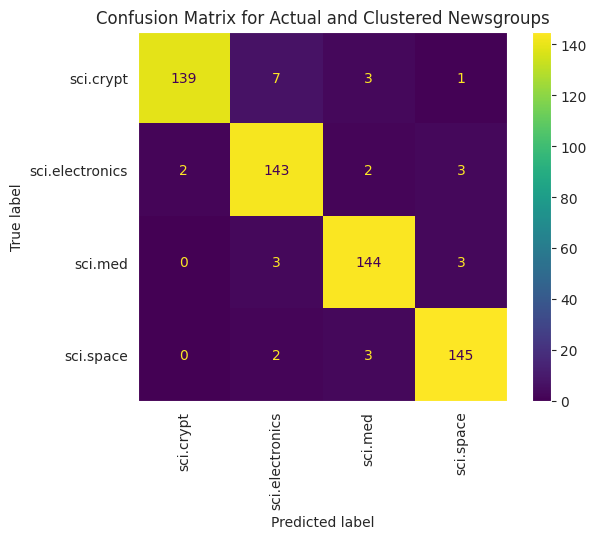
अपने डेटा पर लागू किए गए KMEAN की परफ़ॉर्मेंस को बेहतर तरीके से समझने के लिए, भ्रम की मेट्रिक का इस्तेमाल किया जा सकता है. भ्रम की मैट्रिक्स की मदद से, क्लासिफ़िकेशन मॉडल की परफ़ॉर्मेंस का आकलन सटीक तरीके से नहीं किया जा सकता. आपके पास यह देखने का विकल्प होता है कि गलत कैटगरी में रखे गए पॉइंट की कैटगरी क्या है. आपको ऊपर दिए गए डेटाफ़्रेम में इकट्ठा की गई असल वैल्यू और अनुमानित वैल्यू की ज़रूरत होगी.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
अगले चरण
अब आपने क्लस्टरिंग की मदद से एम्बेड किए गए चैनलों का अपना विज़ुअलाइज़ेशन बना लिया है! टेक्स्ट वाले अपने डेटा का इस्तेमाल करके, उन्हें एम्बेड किए जाने वाले डेटा के तौर पर विज़ुअलाइज़ करें. विज़ुअलाइज़ेशन के चरण को पूरा करने के लिए, डाइमेंशनलिटी कम करने की प्रोसेस शुरू की जा सकती है. ध्यान दें कि TSNE इनपुट को क्लस्टर में बांटने में अच्छा है, लेकिन एक-दूसरे से जुड़ने में ज़्यादा समय लग सकता है. इसके अलावा, यह स्थानीय मिनीमा में अटक सकता है. अगर आपको यह समस्या आती है, तो आप प्रिंसिपल कॉम्पोनेंट विश्लेषण (पीसीए) की तरह भी इस तकनीक का इस्तेमाल कर सकते हैं.
KMEAN के बाहर भी अन्य क्लस्टरिंग एल्गोरिदम होते हैं, जैसे कि डेंसिटी-बेस्ड स्पेशल क्लस्टरिंग (डीबीएससीएएन).
Gemini API में दूसरी सेवाओं को इस्तेमाल करने का तरीका जानने के लिए, Python क्विकस्टार्ट पर जाएं. एम्बेड करने के तरीके के बारे में ज़्यादा जानने के लिए, यहां दिए गए उदाहरण देखें. इन्हें नए सिरे से बनाने का तरीका जानने के लिए, TensorFlow का वर्ड एम्बेडिंग ट्यूटोरियल देखें.