
हो सकता है कि प्रॉम्प्ट डिज़ाइन की रणनीतियां, जैसे कि फ़्यू-शॉट प्रॉम्प्टिंग से हमेशा आपको ज़रूरी नतीजे न मिलें. बेहतर बनाना एक ऐसी प्रोसेस है जिससे खास टास्क पर आपके मॉडल की परफ़ॉर्मेंस को बेहतर बनाया जा सकता है. इसके अलावा, जब निर्देश काफ़ी नहीं होते और आपके पास ऐसे उदाहरणों का एक सेट होता है जो आपको मिलने वाले आउटपुट को दिखाते हैं, तो मॉडल को आउटपुट की खास ज़रूरतों को पूरा करने में मदद मिलती है.
इस पेज में, पीछे के टेक्स्ट मॉडल को बेहतर बनाने के बारे में खास जानकारी दी गई है Gemini API की टेक्स्ट सेवा. जब आप ट्यून करना शुरू करने के लिए तैयार हों, तो फ़ाइन-ट्यूनिंग का ट्यूटोरियल. अगर आपको इस्तेमाल के खास उदाहरणों के लिए, एलएलएम को पसंद के मुताबिक बनाने के बारे में बुनियादी जानकारी. आउट एलएलएम: फ़ाइन-ट्यूनिंग, डिस्टिलेशन, और प्रॉम्प्ट इंजीनियरिंग में मशीन लर्निंग क्रैश कोर्स.
फ़ाइन-ट्यूनिंग की सुविधा कैसे काम करती है
फ़ाइन-ट्यूनिंग का मकसद, आपके खास टास्क के लिए मॉडल की परफ़ॉर्मेंस को और बेहतर बनाना है. मॉडल को बेहतर बनाने के लिए, उसे ट्रेनिंग दी जाती है डेटासेट में टास्क के कई उदाहरण शामिल हैं. खास टास्क के लिए, आपको मॉडल को ट्यून करके, उसकी परफ़ॉर्मेंस में अहम सुधार कर सकते हैं के उदाहरण हैं. इस तरह की मॉडल ट्यूनिंग को कभी-कभी सुपरवाइज़्ड फ़ाइन-ट्यूनिंग, ताकि इसे अन्य तरह की फ़ाइन-ट्यूनिंग से अलग किया जा सके.
आपका ट्रेनिंग डेटा, उदाहरणों के तौर पर होना चाहिए. इसमें प्रॉम्प्ट इनपुट और संभावित जवाब के आउटपुट शामिल होने चाहिए. उदाहरण के तौर पर दिए गए डेटा का इस्तेमाल करके भी मॉडल को ट्यून किया जा सकता है में जाकर देखें. इसका मकसद, मॉडल को मनचाहे व्यवहार की नकल करना सिखाना है या टास्क को उस व्यक्ति के व्यवहार या टास्क के बारे में कई उदाहरण देकर.
जब ट्यूनिंग जॉब चलाया जाता है, तो मॉडल अतिरिक्त पैरामीटर सीख लेता है, जो इसकी मदद करता है आपको जो टास्क चाहिए उसे पूरा करने के लिए, ज़रूरी जानकारी को कोड में बदलें व्यवहार. इसके बाद, अनुमान के समय इन पैरामीटर का इस्तेमाल किया जा सकता है. ट्यूनिंग जॉब का आउटपुट एक नया मॉडल होता है. यह मॉडल, नए पैरामीटर और ओरिजनल मॉडल का असरदार तरीके से मिला-जुला होता है.
अपना डेटासेट तैयार करना
मॉडल को बेहतर बनाने की प्रोसेस शुरू करने से पहले, आपको मॉडल को ट्यून करने के लिए डेटासेट की ज़रूरत होती है. इसके लिए सबसे अच्छी परफ़ॉर्मेंस, डेटासेट में दिए गए उदाहरण अच्छी क्वालिटी के होने चाहिए, और इसमें असल इनपुट और आउटपुट शामिल हों.
फ़ॉर्मैट
आपके डेटासेट में शामिल उदाहरण, आपके अनुमानित प्रोडक्शन से मेल खाने चाहिए ट्रैफ़िक कम कर सकता है. अगर आपके डेटासेट में खास फ़ॉर्मैटिंग, कीवर्ड, निर्देश या जानकारी शामिल है, तो प्रोडक्शन डेटा को उसी तरह फ़ॉर्मैट किया जाना चाहिए और उसमें वही निर्देश होने चाहिए.
उदाहरण के लिए, अगर आपके डेटासेट के उदाहरणों में "question:" और "context:" शामिल हैं, तो प्रोडक्शन ट्रैफ़िक को भी उसी क्रम में फ़ॉर्मैट किया जाना चाहिए जिस क्रम में डेटासेट के उदाहरणों में "question:" और "context:" दिखते हैं. अगर कॉन्टेक्स्ट को हटा दिया जाता है, तो मॉडल, पैटर्न को नहीं पहचान पाएगा,
भले ही सटीक सवाल डेटासेट के किसी उदाहरण में दिया गया हो.
एक और उदाहरण के तौर पर, यहां एक ऐप्लिकेशन के लिए Python ट्रेनिंग डेटा दिया गया है, जो किसी क्रम में अगला नंबर जनरेट करता है:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
अपने डेटासेट में हर उदाहरण के लिए प्रॉम्प्ट या प्रीएंबल जोड़ने से भी मदद मिल सकती है ट्यून किए गए मॉडल की परफ़ॉर्मेंस को बेहतर बनाना. ध्यान दें, अगर आपके डेटासेट में कोई प्रॉम्प्ट या प्रीऐबल शामिल है, तो अनुमान लगाने के समय, उसे ट्यून किए गए मॉडल के प्रॉम्प्ट में भी शामिल किया जाना चाहिए.
सीमाएं
ध्यान दें: Gemini 1.5 Flash के लिए डेटासेट को बेहतर बनाने की सुविधा में ये सीमाएं हैं:
- हर उदाहरण के लिए, इनपुट का ज़्यादा से ज़्यादा साइज़ 40,000 वर्ण हो सकता है.
- हर उदाहरण के लिए, आउटपुट का ज़्यादा से ज़्यादा साइज़ 5,000 वर्ण हो सकता है.
ट्रेनिंग के लिए डेटा का साइज़
आप कम से कम 20 उदाहरणों के साथ किसी मॉडल को बेहतर बना सकते हैं. अतिरिक्त डेटा आम तौर पर जवाबों की क्वालिटी को बेहतर बनाता है. आपको 100 के बीच लक्षित करना चाहिए और 500 उदाहरण देखें. यहां दी गई टेबल में, आम तौर पर किए जाने वाले अलग-अलग टास्क के लिए, टेक्स्ट मॉडल को बेहतर बनाने के लिए सुझाए गए डेटासेट के साइज़ की जानकारी दी गई है:
| टास्क | डेटासेट में उदाहरणों की संख्या |
|---|---|
| कैटगरी | 100+ |
| खास जानकारी | 100-500+ |
| दस्तावेज़ खोजें | 100+ |
ट्यूनिंग डेटासेट अपलोड करना
डेटा को एपीआई का इस्तेमाल करके या Google में अपलोड की गई फ़ाइलों के ज़रिए इनलाइन पास किया जाता है AI Studio.
क्लाइंट लाइब्रेरी का इस्तेमाल करने के लिए, createTunedModel कॉल में डेटा फ़ाइल दें.
फ़ाइल का साइज़ चार एमबी से ज़्यादा नहीं होना चाहिए. शुरू करने के लिए, Python की मदद से बेहतर बनाने के लिए क्विकस्टार्ट देखें.
cURL का इस्तेमाल करके REST API को कॉल करने के लिए, training_data आर्ग्युमेंट में JSON फ़ॉर्मैट में ट्रेनिंग के उदाहरण दें. शुरू करने के लिए, cURL की मदद से ट्यून करने का तरीका देखें.
बेहतर ट्यूनिंग की सेटिंग
ट्यूनिंग जॉब बनाते समय, आप नीचे दी गई बेहतर सेटिंग तय कर सकते हैं:
- Epoch: पूरे ट्रेनिंग सेट के लिए एक पूरा ट्रेनिंग पास, जैसे कि हर एक को उदाहरण को एक बार प्रोसेस कर दिया गया है.
- बैच साइज़: एक ट्रेनिंग इटरेशन में इस्तेमाल किए जाने वाले उदाहरणों का सेट. कॉन्टेंट बनाने बैच साइज़ से बैच में उदाहरणों की संख्या तय होती है.
- लर्निंग रेट: यह एक फ़्लोटिंग-पॉइंट नंबर है. इससे एल्गोरिदम को पता चलता है कि हर बार दोहराए जाने पर, मॉडल पैरामीटर को कितनी ज़्यादा बदलाव करना है. उदाहरण के लिए, 0.3 की लर्निंग रेट, 0.1 की लर्निंग रेट की तुलना में वज़न और बायस में तीन गुना ज़्यादा बदलाव करेगी. ज़्यादा और कम लर्निंग रेट के अपने अलग-अलग फ़ायदे और नुकसान होते हैं. इसलिए, इनमें अपने इस्तेमाल के हिसाब से बदलाव किया जाना चाहिए.
- लर्निंग रेट मल्टीप्लायर: रेट मल्टीप्लायर, मॉडल के मूल लर्निंग रेट में बदलाव करता है. वैल्यू 1 होने पर, मॉडल की मूल लर्निंग रेट का इस्तेमाल किया जाता है. एक से ज़्यादा वैल्यू देने पर, सीखने की दर और वैल्यू एक के बीच बढ़ जाती है और 0 सीखने की दर कम हो जाती है.
सुझाए गए कॉन्फ़िगरेशन
नीचे दी गई टेबल में कॉन्फ़िगरेशन को बेहतर बनाने के लिए सुझाए गए कॉन्फ़िगरेशन दिए गए हैं फ़ाउंडेशन मॉडल:
| हाइपर पैरामीटर | डिफ़ॉल्ट वैल्यू | सुझाए गए बदलाव |
|---|---|---|
| एपॉक | 5 |
अगर पांच एपिसोड से पहले लॉस प्लैटफ़ॉर्म पर आ जाता है, तो छोटी वैल्यू का इस्तेमाल करें. अगर नुकसान की वैल्यू एक जैसी है और अनुमानित नहीं है, तो ज़्यादा वैल्यू इस्तेमाल करें. |
| बैच का साइज़ | 4 | |
| सीखने की दर | 0.001 | छोटे डेटासेट के लिए, कम वैल्यू का इस्तेमाल करें. |
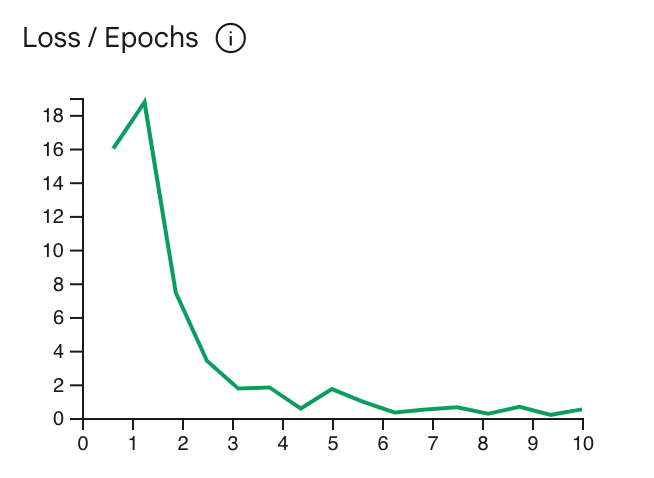
लॉस कर्व से पता चलता है कि हर एपिसोड के बाद, मॉडल का अनुमान, ट्रेनिंग के उदाहरणों में दी गई सही अनुमानों से कितना अलग है. आम तौर पर, आपको ट्रेनिंग को कर्व के सबसे निचले हिस्से पर, प्लैटफ़ॉर्म पर पहुंचने से ठीक पहले रोकना चाहिए. उदाहरण के लिए, नीचे दिए गए ग्राफ़ में लॉस कर्व, एपिक 4 से 6 के आस-पास प्लैटफ़ॉर्म पर दिख रहा है. इसका मतलब है कि Epoch पैरामीटर को 4 पर सेट किया जा सकता है और फिर भी वही परफ़ॉर्मेंस मिल सकती है.
ट्यूनिंग जॉब की स्थिति देखें
Google AI Studio में, ट्यूनिंग की नौकरी की स्थिति देखने के लिए
मेरी लाइब्रेरी टैब या इसके साथ ट्यून किए गए मॉडल की metadata प्रॉपर्टी का इस्तेमाल करना
Gemini API.
गड़बड़ियां ठीक करना
इस सेक्शन में, समस्याओं को ठीक करने के बारे में सलाह दी गई है. जिससे आपका ट्यून किया गया मॉडल बन जाएगा.
पुष्टि करना
एपीआई और क्लाइंट लाइब्रेरी का इस्तेमाल करके ट्यून करने के लिए, पुष्टि करना ज़रूरी है. आप API कुंजी (सुझाया गया) या OAuth का इस्तेमाल करके पुष्टि करने की सुविधा सेट अप करें क्रेडेंशियल डालें. एपीआई पासकोड सेट अप करने के बारे में दस्तावेज़ देखने के लिए, एपीआई पासकोड सेट अप करना लेख पढ़ें.
अगर आपको 'PermissionDenied: 403 Request had insufficient authentication
scopes' गड़बड़ी का कोड दिखता है, तो हो सकता है कि आपको OAuth क्रेडेंशियल का इस्तेमाल करके, उपयोगकर्ता की पुष्टि करने की सुविधा सेट अप करनी पड़े. Python के लिए OAuth क्रेडेंशियल कॉन्फ़िगर करने के लिए, OAuth सेटअप ट्यूटोरियल पर जाएं.
रद्द किए गए मॉडल
बेहतर परफ़ॉर्म करने वाले काम को पूरा करने से पहले, इसे किसी भी समय रद्द किया जा सकता है. हालांकि, रद्द किए गए मॉडल की परफ़ॉर्मेंस का अनुमान नहीं लगाया जा सकता, खास तौर पर तब ट्यूनिंग का काम ट्रेनिंग के दौरान जल्दी रद्द कर दिया जाता है. अगर आपने ट्रेनिंग को किसी पुराने युग पर रोकने के लिए रद्द किया है, तो आपको एक नई ट्यूनिंग जॉब बनानी चाहिए और युग को कम वैल्यू पर सेट करना चाहिए.
ट्यून किए गए मॉडल की सीमाएं
ध्यान दें: ट्यून किए गए मॉडल की सीमाएं नीचे दी गई हैं:
- ट्यून किए गए Gemini 1.5 Flash मॉडल के इनपुट की सीमा, 40,000 वर्ण है.
- JSON मोड, ट्यून किए गए मॉडल के साथ काम नहीं करता.
- सिर्फ़ टेक्स्ट इनपुट का इस्तेमाल किया जा सकता है.
आगे क्या करना है
बेहतर बनाने के ट्यूटोरियल देखना शुरू करें: