
|
|
|
 Consulte o código-fonte no GitHub Consulte o código-fonte no GitHub
|
Visão geral
Neste tutorial, você verá como visualizar e realizar o clustering com os embeddings da API Gemini. Você vai visualizar um subconjunto do conjunto de dados do Newsgroup 20 usando t-SNE e agrupar esse subconjunto usando o algoritmo KMeans.
Para mais informações sobre como começar a usar os embeddings gerados a partir da API Gemini, confira o guia de início rápido do Python.
Pré-requisitos
Este guia de início rápido pode ser executado no Google Colab.
Para concluir este guia de início rápido no seu próprio ambiente de desenvolvimento, verifique se o ambiente atende aos seguintes requisitos:
- Python 3.9 ou superior
- Uma instalação de
jupyterpara executar o notebook.
Configuração
Primeiro, faça o download e instale a biblioteca Python da API Gemini.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Obter uma chave de API
Antes de usar a API Gemini, é necessário ter uma chave de API. Se você ainda não tiver uma, crie uma chave com um clique no Google AI Studio.
No Colab, adicione a chave ao gerenciador de secrets abaixo do "", no painel à esquerda. Dê o nome API_KEY a ela.
Quando você tiver a chave de API, transmita-a ao SDK. Faça isso de duas maneiras:
- Coloque a chave na variável de ambiente
GOOGLE_API_KEY. O SDK vai selecioná-la automaticamente de lá. - Transmita a chave para
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Conjunto de dados
O conjunto de dados de 20 grupos de notícias contém 18.000 postagens de grupos de notícias sobre 20 tópicos divididos em conjuntos de treinamento e teste. A divisão entre os conjuntos de dados de treinamento e teste é baseada em mensagens postadas antes e depois de uma data específica. Neste tutorial, você vai usar o subconjunto de treinamento.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Este é o primeiro exemplo do conjunto de treinamento.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Em seguida, você fará uma amostra de alguns dos dados pegando 100 pontos de dados no conjunto de dados de treinamento e descartando algumas das categorias para executar este tutorial. Escolha as categorias científicas para comparar.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Criar os embeddings
Nesta seção, você vai aprender a gerar embeddings para os diferentes textos no DataFrame usando os embeddings da API Gemini.
Mudanças de API em embeddings com embeddings-001 do modelo
Para o novo modelo de embeddings, embedding-001, há um novo parâmetro de tipo de tarefa e o título opcional (válido somente com task_type=RETRIEVAL_DOCUMENT).
Esses novos parâmetros se aplicam somente aos modelos de embeddings mais recentes.Os tipos de tarefa são:
| Tipo de tarefa | Descrição |
|---|---|
| RETRIEVAL_QUERY | Especifica que o texto é uma consulta em uma configuração de pesquisa/recuperação. |
| RETRIEVAL_DOCUMENT | Especifica que o texto é um documento em uma configuração de pesquisa/recuperação. |
| SEMANTIC_SIMILARITY | Especifica o texto a ser usado para similaridade textual semântica (STS). |
| CLASSIFICAÇÃO | Especifica que os embeddings serão usados para classificação. |
| CLUSTERING | Especifica que os embeddings serão usados para clustering. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Redução de dimensionalidade
O comprimento do vetor de embedding do documento é 768. Para visualizar como os documentos incorporados são agrupados, você precisará aplicar a redução de dimensionalidade, já que só é possível visualizar os embeddings em espaços 2D ou 3D. Documentos contextualmente semelhantes devem estar mais próximos no espaço, em vez de documentos que não são tão semelhantes.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
Você aplicará a abordagem t-Distributed Stochastic Neighbor Embedding (t-SNE) para realizar a redução da dimensionalidade. Essa técnica reduz o número de dimensões e preserva os clusters, ou seja, os pontos que estão próximos permanecem próximos. Com relação aos dados originais, o modelo tenta criar uma distribuição em que outros pontos de dados são "vizinhos" (por exemplo, eles compartilham um significado semelhante). Em seguida, ele otimiza uma função objetiva para manter uma distribuição similar na visualização.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
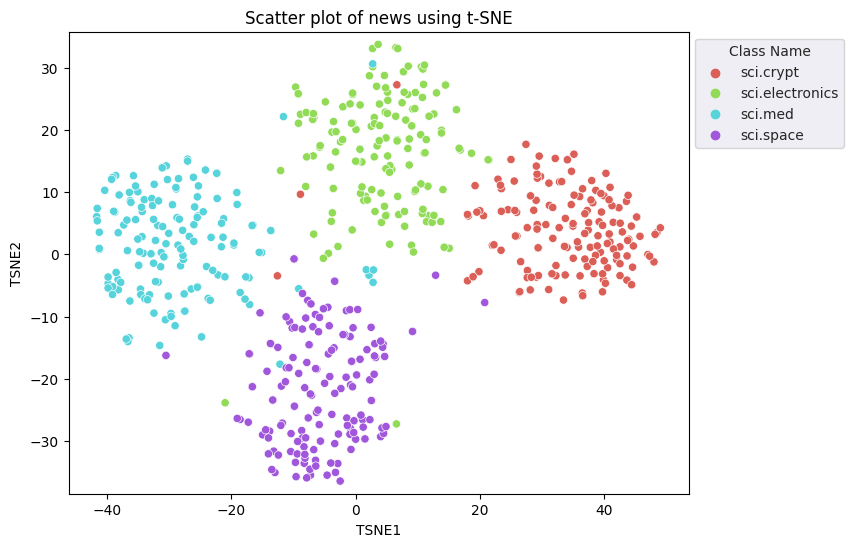
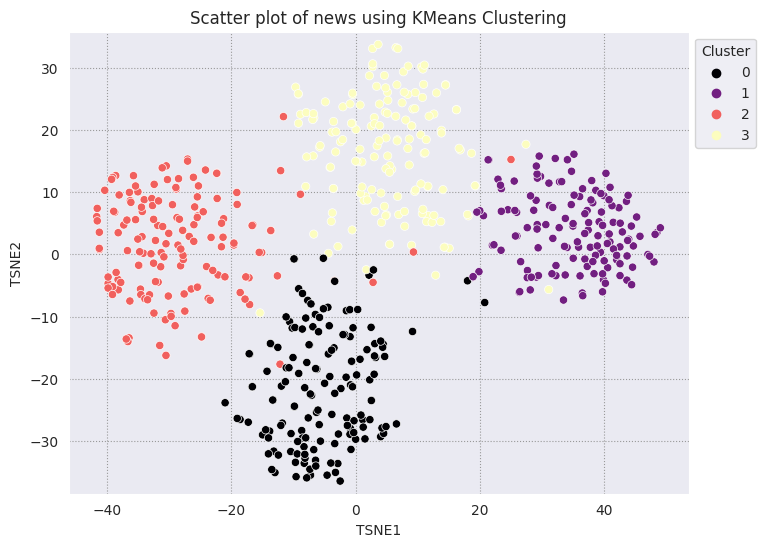
Comparar resultados com KMeans
O clustering KMeans é um algoritmo de clustering conhecido usado com frequência para aprendizado não supervisionado. Ela determina iterativamente os melhores k pontos centrais e atribui cada exemplo ao centroide mais próximo. Insira os embeddings diretamente no algoritmo KMeans para comparar a visualização deles com o desempenho de um algoritmo de machine learning.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Consiga a maioria dos clusters por grupo e veja quantos dos membros reais desse grupo estão nesse cluster.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
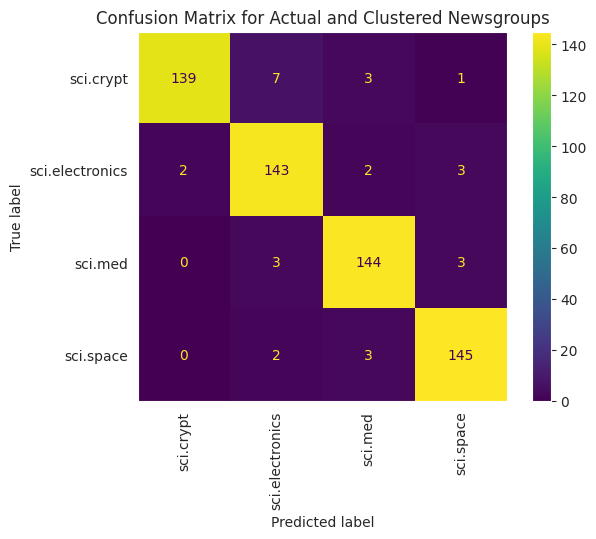
Para visualizar melhor o desempenho dos KMeans aplicados aos seus dados, é possível usar uma matriz de confusão. A matriz de confusão permite avaliar o desempenho do modelo de classificação além da acurácia. É possível saber como os pontos são classificados incorretamente. Você precisará dos valores reais e previstos, que reuniu no DataFrame acima.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Próximas etapas
Você criou sua própria visualização de embeddings com clustering. Tente usar seus próprios dados textuais para visualizá-los como embeddings. Você pode realizar a redução de dimensionalidade para concluir a etapa de visualização. O TSNE é bom em agrupar entradas, mas pode levar mais tempo para convergir ou ficar preso nos mínimos locais. Se você tiver esse problema, outra técnica que poderá usar é a análise de componentes principais (PCA, na sigla em inglês).
Há também outros algoritmos de clustering fora do KMeans, como o clustering espacial baseado em densidade (DBSCAN).
Para saber mais sobre como usar embeddings, consulte estes outros tutoriais: