
|
|
|
 GitHub에서 소스 보기 GitHub에서 소스 보기
|
개요
이 튜토리얼에서는 Gemini API의 임베딩으로 클러스터링을 시각화하고 수행하는 방법을 보여줍니다. t-SNE를 사용하여 20개 뉴스그룹 데이터 세트의 하위 집합을 시각화하고 KMeans 알고리즘을 사용하여 해당 하위 집합을 클러스터링합니다.
Gemini API에서 생성된 임베딩을 시작하는 방법에 대한 자세한 내용은 Python 빠른 시작을 참고하세요.
기본 요건
이 빠른 시작은 Google Colab에서 실행할 수 있습니다.
자체 개발 환경에서 이 빠른 시작을 완료하려면 환경이 다음 요구사항을 충족하는지 확인하세요.
- Python 3.9 이상
- 노트북을 실행할
jupyter설치
설정
먼저 Gemini API Python 라이브러리를 다운로드하고 설치합니다.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
API 키 가져오기
Gemini API를 사용하려면 먼저 API 키를 가져와야 합니다. 아직 키가 없으면 Google AI Studio에서 클릭 한 번으로 키를 만듭니다.
Colab에서 왼쪽 패널의 'boot' 아래에 있는 보안 비밀 관리자에 키를 추가합니다. 이름을 API_KEY로 지정합니다.
API 키가 있으면 SDK에 전달합니다. 여기에는 두 가지 방법이 있습니다.
GOOGLE_API_KEY환경 변수에 키를 배치합니다 (SDK가 자동으로 거기에서 가져옴).genai.configure(api_key=...)에 키 전달
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
데이터 세트
20 Newsgroups 텍스트 데이터 세트에는 학습 및 테스트 세트로 나누어진 20가지 주제에 대한 18,000개의 뉴스그룹 게시물이 포함되어 있습니다. 학습 데이터 세트와 테스트 데이터 세트는 특정 날짜 이전과 이후에 게시된 메시지를 기준으로 분할됩니다. 이 튜토리얼에서는 학습 하위 집합을 사용합니다.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
다음은 학습 세트의 첫 번째 예입니다.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
다음으로 학습 데이터 세트에서 100개의 데이터 포인트를 선택하고 이 튜토리얼에서 실행할 카테고리 몇 개를 삭제하여 일부 데이터를 샘플링합니다. 비교할 과학 카테고리를 선택합니다.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
임베딩 만들기
이 섹션에서는 Gemini API의 임베딩을 사용하여 DataFrame의 다양한 텍스트에 대한 임베딩을 생성하는 방법을 알아봅니다.
모델 Embedding-001을 사용한 Embeddings의 API 변경사항
새 임베딩 모델인 embedding-001에는 새로운 작업 유형 매개변수와 선택적 제목이 있습니다 (task_type=RETRIEVAL_DOCUMENT에서만 유효).
이러한 새 매개변수는 최신 임베딩 모델에만 적용됩니다. 작업 유형은 다음과 같습니다.
| 작업 유형 | 설명 |
|---|---|
| RETRIEVAL_QUERY | 지정된 텍스트가 검색/가져오기 설정의 쿼리임을 지정합니다. |
| RETRIEVAL_DOCUMENT | 지정된 텍스트가 검색/가져오기 설정의 문서임을 지정합니다. |
| SEMANTIC_SIMILARITY | 지정된 텍스트를 시맨틱 텍스트 유사성(STS)에 사용하도록 지정합니다. |
| 분류 | 임베딩이 분류에 사용되도록 지정합니다. |
| 클러스터링 | 클러스터링에 임베딩을 사용하도록 지정합니다. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
차원 축소
문서 임베딩 벡터의 길이는 768입니다. 삽입된 문서를 그룹화하는 방법을 시각화하려면 임베딩을 2D 또는 3D 공간에서만 시각화할 수 있으므로 차원 축소를 적용해야 합니다. 문맥적으로 유사한 문서는 그다지 비슷하지 않은 문서보다 공간에서 서로 더 가까이 있어야 합니다.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
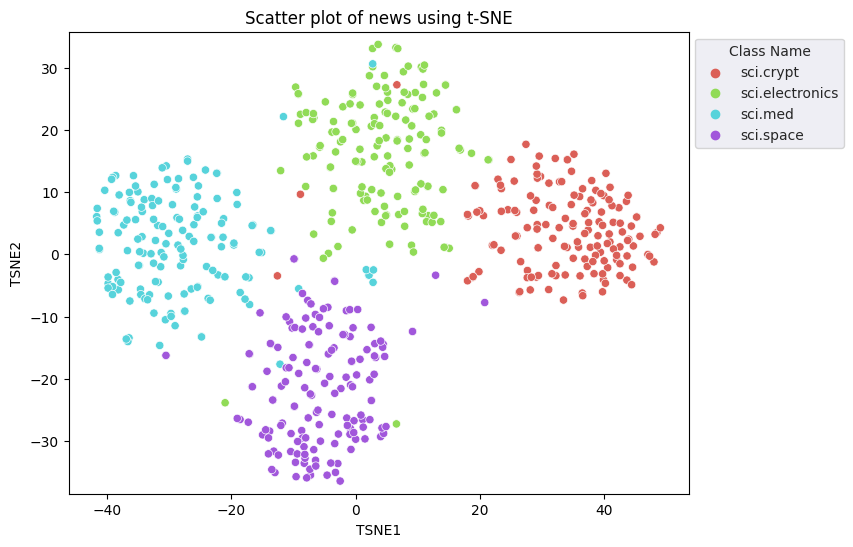
t-분산 확률적 이웃 임베딩 (t-SNE) 접근 방식을 적용하여 차원 축소를 수행합니다. 이 기법은 차원 수를 줄이면서 클러스터를 보존합니다 (가까운 지점은 서로 가까이 유지됨). 원본 데이터의 경우 모델은 다른 데이터 포인트가 '이웃'인 분포를 구성하려고 시도합니다(예: 비슷한 의미를 공유). 그런 다음 시각화에서 유사한 분포를 유지하도록 목적 함수를 최적화합니다.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
결과를 KMeans와 비교
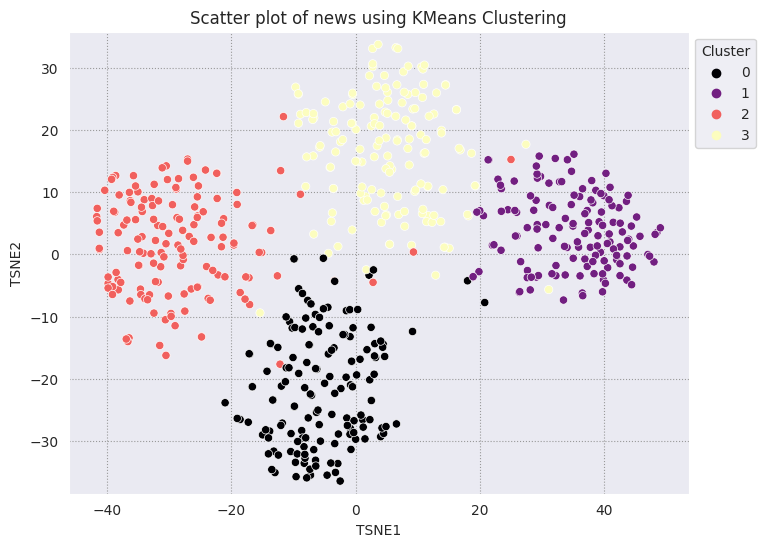
KMeans 클러스터링은 널리 사용되는 클러스터링 알고리즘으로, 비지도 학습에 자주 사용됩니다. 최적의 중심점을 반복적으로 결정하고 각 예를 가장 가까운 중심에 할당합니다. 임베딩을 KMeans 알고리즘에 직접 입력하여 임베딩의 시각화와 머신러닝 알고리즘의 성능을 비교합니다.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
그룹당 대부분의 클러스터를 가져오고 해당 그룹의 실제 구성원 중 해당 클러스터에 몇 명이 있는지 확인합니다.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
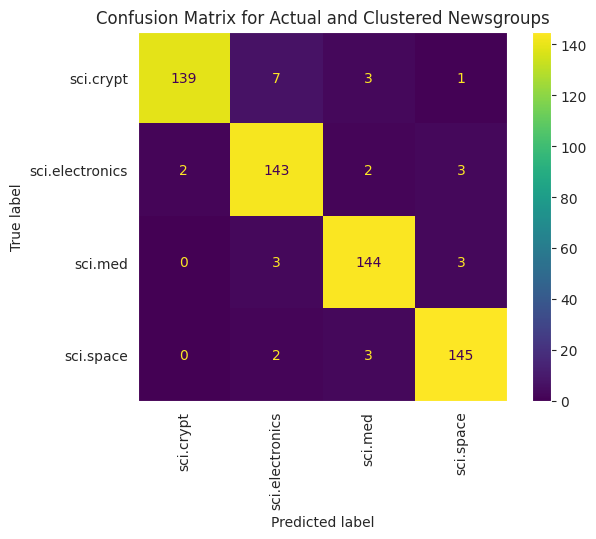
데이터에 적용된 KMeans의 성능을 더 잘 시각화하려면 혼동 행렬을 사용하면 됩니다. 혼동 행렬을 사용하면 정확성 외에도 분류 모델의 성능을 평가할 수 있습니다. 잘못 분류된 포인트를 확인할 수 있습니다. 실제 값과 위의 DataFrame에서 수집한 예측값이 필요합니다.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
다음 단계
이제 클러스터링으로 임베딩의 시각화를 직접 만들었습니다. 자체 텍스트 데이터를 사용하여 임베딩으로 시각화해 보세요. 시각화 단계를 완료하기 위해 측정기준 축소를 수행할 수 있습니다. TSNE는 입력을 클러스터링하는 데 적합하지만 수렴하는 데 시간이 더 오래 걸리거나 국소 최솟값에서 멈출 수 있습니다. 이 문제가 발생하는 경우 고려할 수 있는 또 다른 기술은 주성분 분석 (PCA)입니다.
KMeans 외에도 밀도 기반 공간 클러스터링 (DBSCAN)과 같은 다른 클러스터링 알고리즘이 있습니다.
임베딩 사용 방법에 대한 자세한 내용은 다음 튜토리얼을 참조하세요.