
提示設計策略 (例如幾個提示) 不一定能產生您需要的結果。微調是一項可改善模型 表現,或協助模型遵循特定輸出內容 並提供一組範例,藉此補充: 來呈現所需的輸出內容
本頁面提供微調文字模型的概念總覽 Gemini API 文字服務當您準備好調整模型時, 微調教學課程。如果您想 舉例來說,如要針對特定用途自訂 LLM,請參閱 出局 大型語言模型:微調、精煉和提示工程 的 機器學習密集課程。
微調功能的運作方式
微調的目的在於進一步提升 您的具體任務微調功能的運作方式是提供模型訓練資料 包含許多工作範例的資料集。對於特定任務,只要少量的樣本就能調整模型,大幅提升模型成效。這種調整模型有時也稱為 監督式微調,使其與其他類型的微調作業做出區別。
訓練資料的結構應為含有提示輸入內容和預期回應輸出內容的範例。您也可以直接在 Google AI Studio 中使用示例資料調整模型。目標是訓練模型模仿期望的行為 或工作或任務
執行調整工作時,模型會學習其他參數 將必要資訊編碼以執行所需工作 行為系統會在推論期間使用這些參數。模型的輸出內容 調整工作是新的模型,有效結合了 學習的參數和原始模型
準備資料集
您需要有用來調整模型的資料集,才能開始微調。適用對象 資料集中的範例必須為高品質、 來代表真實的輸入和輸出內容。
格式
資料集中的範例應與預期的實際工作環境流量相符。如果您的資料集包含特定格式、關鍵字、指示 生產資料的格式應該相同 包含相同指示
舉例來說,如果資料集中的範例包含 "question:" 和
"context:",正式環境流量也應格式化為
"question:" 和 "context:" 的順序與出現在資料集的順序相同
範例。如果排除情境,模型就無法辨識模式
即使確切問題位於資料集的範例中也一樣
以下是另一個範例,這是應用程式產生序列中下一個數字的 Python 訓練資料:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
在資料集中的每個範例中加入提示或前置詞,也可能有助於 可以提高調整後模型的成效請注意,如果提示或前置碼 也應該包含在調整後的提示中 推論模型
限制
注意:Gemini 1.5 Flash 的精細調整資料集有以下限制:
- 每個範例的輸入內容大小上限為 40,000 個字元。
- 每個範例的輸出內容大小上限為 5,000 個字元。
訓練資料大小
您最多可以使用 20 個範例微調模型。額外資料 通常也會改善回應的品質。您應指定 100 之間 以及 500 個範例,視您的應用程式而定。下表列出針對各種常見工作精調文字模型時,建議使用的資料集大小:
| 工作 | 資料集中的範例數量 |
|---|---|
| 分類 | 100 以上 |
| 製作摘要 | 100-500+ |
| 文件搜尋 | 100 人以上 |
上傳調整用資料集
系統可以透過 API 內嵌傳送資料,或經由上傳到 Google 的檔案進行傳遞 進行測試
如要使用用戶端程式庫,請在 createTunedModel 呼叫中提供資料檔案。
檔案大小上限為 4 MB。詳情請參閱
使用 Python 進行微調快速入門導覽課程
即可開始使用
如要使用 cURL 呼叫 REST API,請將 JSON 格式的訓練範例提供給 training_data 引數。請參閱使用 cURL 進行調整的快速入門指南,瞭解如何開始使用。
進階微調設定
建立調整工作時,您可以指定下列進階設定:
- 訓練週期:涵蓋整個訓練集的完整訓練集, 系統已處理過一次範例
- 批量:單一訓練「疊代」中使用的範例組合。 批次大小會決定批次中的樣本數量
- 學習率:是一個浮點數,能告知演算法如何 強力調整每次疊代的模型參數舉例來說,學習率為 0.3 的調整權重和偏差的效果,比學習率為 0.1 的效果強大三倍。高低學習率有 並依據自己的用途調整
- 學習率調節係數:費率調節係數會修改模型的 原始學習率值為 1 時,系統會使用原有學習率 模型值大於 1 會提高學習率,而值介於 1 和 0 之間會降低學習率。
建議設定
下表列出微調 基礎模型:
| 超參數 | 預設值 | 建議調整 |
|---|---|---|
| Epoch | 5 |
如果損失開始值早於 5 個週期,請使用較小的值。 如果損失是採收斂處理,看起來並未偏平,則輸入較高的價值。 |
| 批量 | 4 | |
| 學習率 | 0.001 | 如果是較小的資料集,請使用較小的值。 |
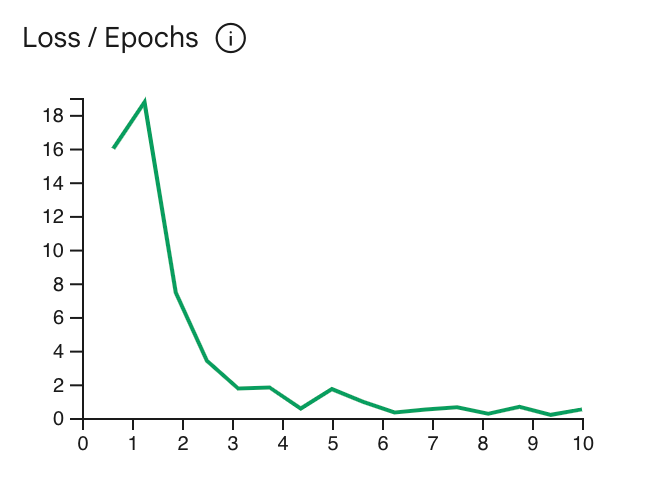
損失曲線會顯示模型預測與理想偏差的程度
訓練樣本中的預測結果最好
然後沿著曲線上最低點的高強度訓練例如:
下圖顯示了大約 4-6 號的損失曲線,這代表
就算將 Epoch 參數設為 4,您還是可以享有相同效能。
查看調整工作狀態
您可以在 Google AI Studio 的
」分頁或使用調整後模型的 metadata 屬性
或 Gemini API 整合。
排解錯誤
本節提供提示,說明如何解決在建立經過調整的模型時可能遇到的錯誤。
驗證
使用 API 與用戶端程式庫進行調整時,需要使用者驗證。單憑 API 金鑰是不夠的。如果您看到 'PermissionDenied: 403 Request had
insufficient authentication scopes' 錯誤,就必須設定使用者驗證。
如要設定 Python 的 OAuth 憑證,請參閱 OAuth 設定教學課程。
已取消的模型
您可以在精細調整工作完成前隨時取消。不過 取消模型的推論成效是無法預測的 系統就會在訓練過程提前取消調整工作。取消原因: 想要在早期週期停止訓練時 並將週期設為較低的值。
調整後模型的限制
注意:調校模型有下列限制:
- 調整後的 Gemini 1.5 Flash 模型的輸入上限為 40,000 個字元。
- 調整過的模型不支援 JSON 模式。
- 僅支援文字輸入。
後續步驟
透過微調教學課程瞭解如何開始使用: