
استفاده از پردازندههای تخصصی مانند GPU، NPU یا DSP برای شتاب سختافزاری میتواند عملکرد استنتاج (در برخی موارد تا ۱۰ برابر سریعتر استنتاج) و تجربه کاربری برنامه اندرویدی با قابلیت ML شما را به طور چشمگیری بهبود بخشد. با این حال، با توجه به انواع سخت افزار و درایورهایی که کاربران شما ممکن است داشته باشند، انتخاب پیکربندی بهینه شتاب سخت افزاری برای دستگاه هر کاربر می تواند چالش برانگیز باشد. علاوه بر این، فعال کردن پیکربندی اشتباه روی یک دستگاه میتواند تجربه کاربری ضعیفی را به دلیل تأخیر زیاد یا در برخی موارد نادر، خطاهای زمان اجرا یا مشکلات دقت ناشی از ناسازگاریهای سختافزاری ایجاد کند.
Acceleration Service for Android یک API است که به شما کمک میکند پیکربندی بهینه شتاب سختافزاری را برای یک دستگاه کاربر معین و مدل .tflite خود انتخاب کنید، در حالی که خطر خطای زمان اجرا یا مشکلات دقت را به حداقل میرساند.
سرویس شتاب پیکربندیهای مختلف شتاب را در دستگاههای کاربر با اجرای معیارهای استنتاج داخلی با مدل LiteRT شما ارزیابی میکند. این تست معمولاً بسته به مدل شما در چند ثانیه انجام می شود. می توانید قبل از زمان استنتاج، معیارها را یک بار روی هر دستگاه کاربر اجرا کنید، نتیجه را در حافظه پنهان نگه دارید و در طول استنتاج از آن استفاده کنید. این معیارها خارج از فرآیند هستند. که خطر خرابی برنامه شما را به حداقل می رساند.
مدل، نمونه دادهها و نتایج مورد انتظار (ورودیها و خروجیهای "طلایی") خود را ارائه دهید و سرویس شتاب یک معیار استنتاج داخلی TFLite را اجرا میکند تا توصیههای سختافزاری را به شما ارائه دهد.
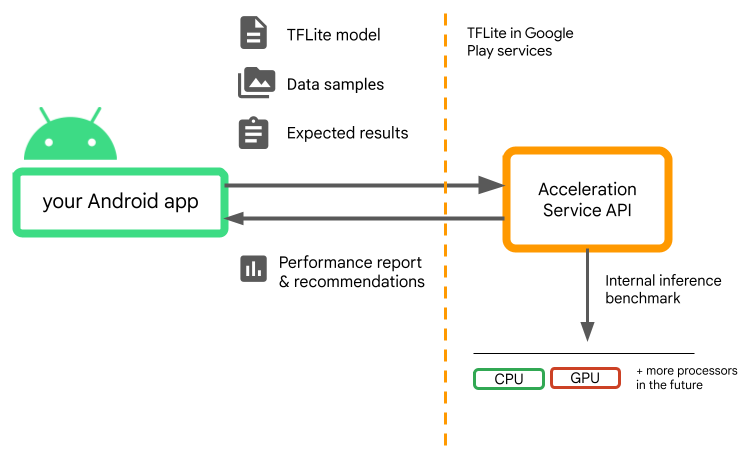
سرویس شتاب بخشی از پشته ML سفارشی Android است و با LiteRT در سرویسهای Google Play کار میکند.
وابستگی ها را به پروژه خود اضافه کنید
وابستگی های زیر را به فایل build.gradle برنامه خود اضافه کنید:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
Acceleration Service API با LiteRT در خدمات Google Play کار می کند. اگر هنوز از زمان اجرا LiteRT ارائه شده از طریق Play Services استفاده نمی کنید، باید وابستگی های خود را به روز کنید.
نحوه استفاده از Acceleration Service API
برای استفاده از Acceleration Service، با ایجاد پیکربندی شتابی که میخواهید برای مدل خود ارزیابی کنید، شروع کنید (مثلاً GPU با OpenGL). سپس یک پیکربندی اعتبار سنجی با مدل خود، برخی داده های نمونه و خروجی مدل مورد انتظار ایجاد کنید. در نهایت validateConfig() با عبور از پیکربندی شتاب و پیکربندی اعتبارسنجی فراخوانی کنید.

ایجاد تنظیمات شتاب
پیکربندیهای شتاب نمایشی از پیکربندیهای سختافزاری هستند که در طول زمان اجرا به نمایندگان ترجمه میشوند. سپس سرویس شتاب از این تنظیمات به صورت داخلی برای انجام استنتاج های آزمایشی استفاده خواهد کرد.
در حال حاضر سرویس شتاب به شما امکان میدهد پیکربندیهای GPU (تبدیل شده به نماینده GPU در طول زمان اجرا) را با GpuAccelerationConfig و استنتاج CPU (با CpuAccelerationConfig ) ارزیابی کنید. ما در حال کار بر روی حمایت از نمایندگان بیشتر برای دسترسی به سخت افزارهای دیگر در آینده هستیم.
پیکربندی شتاب GPU
یک پیکربندی شتاب GPU را به صورت زیر ایجاد کنید:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
باید مشخص کنید که آیا مدل شما از کوانتیزاسیون با setEnableQuantizedInference() استفاده می کند یا خیر.
پیکربندی شتاب CPU
شتاب CPU را به صورت زیر ایجاد کنید:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
از متد setNumThreads() برای تعیین تعداد رشته هایی که می خواهید برای ارزیابی استنتاج CPU استفاده کنید، استفاده کنید.
ایجاد تنظیمات اعتبار سنجی
تنظیمات اعتبارسنجی شما را قادر می سازد تا نحوه ارزیابی استنباط ها را از سرویس شتاب تعریف کنید. از آنها برای عبور استفاده خواهید کرد:
- نمونه های ورودی،
- خروجی های مورد انتظار،
- منطق اعتبارسنجی دقت
اطمینان حاصل کنید که نمونههای ورودی را ارائه میکنید که انتظار دارید عملکرد خوبی از مدل خود داشته باشید (همچنین به عنوان نمونههای طلایی شناخته میشوند).
یک ValidationConfig با CustomValidationConfig.Builder به صورت زیر ایجاد کنید:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
تعداد نمونه های طلایی را با setBatchSize() مشخص کنید. ورودی های نمونه طلایی خود را با استفاده از setGoldenInputs() ارسال کنید. خروجی مورد انتظار را برای ورودی ارسال شده با setGoldenOutputs() ارائه دهید.
شما می توانید حداکثر زمان استنتاج را با setInferenceTimeoutMillis() تعیین کنید (به طور پیش فرض 5000 میلی ثانیه). اگر استنتاج بیشتر از زمانی که شما تعریف کرده اید طول بکشد، پیکربندی رد می شود.
به صورت اختیاری، همچنین می توانید یک AccuracyValidator سفارشی به شرح زیر ایجاد کنید:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
مطمئن شوید که یک منطق اعتبار سنجی را تعریف کنید که برای مورد استفاده شما کار می کند.
توجه داشته باشید که اگر داده های اعتبارسنجی قبلاً در مدل شما تعبیه شده است، می توانید از EmbeddedValidationConfig استفاده کنید.
خروجی های اعتبار سنجی ایجاد کنید
خروجیهای طلایی اختیاری هستند و تا زمانی که ورودیهای طلایی را ارائه کنید، سرویس شتاب میتواند خروجیهای طلایی را به صورت داخلی تولید کند. همچنین می توانید پیکربندی شتاب مورد استفاده برای تولید این خروجی های طلایی را با فراخوانی setGoldenConfig() تعریف کنید:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
تأیید پیکربندی شتاب
هنگامی که یک پیکربندی شتاب و یک پیکربندی اعتبار سنجی ایجاد کردید، می توانید آنها را برای مدل خود ارزیابی کنید.
اطمینان حاصل کنید که LiteRT با زمان اجرای خدمات Play به درستی مقداردهی اولیه شده است و نماینده GPU برای دستگاه با اجرای زیر در دسترس است:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
با فراخوانی AccelerationService.create() AccelerationService را نمونه سازی کنید.
سپس می توانید با فراخوانی validateConfig() پیکربندی شتاب خود را برای مدل خود تأیید کنید:
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
همچنین میتوانید با فراخوانی validateConfigs() و ارسال یک شیء Iterable<AccelerationConfig> بهعنوان پارامتر، چندین پیکربندی را تأیید کنید.
validateConfig() یک Task< ValidatedAccelerationConfigResult > را از Google Play Services Task Api برمی گرداند که وظایف ناهمزمان را فعال می کند.
برای دریافت نتیجه از فراخوانی اعتبارسنجی، یک callback addOnSuccessListener() اضافه کنید.
از پیکربندی تایید شده در مترجم خود استفاده کنید
پس از بررسی اینکه آیا ValidatedAccelerationConfigResult برگشت داده شده در تماس برگشتی معتبر است، می توانید پیکربندی تایید شده را به عنوان یک پیکربندی شتاب برای interpreterOptions.setAccelerationConfig() خود تنظیم کنید.
ذخیره سازی پیکربندی
بعید است پیکربندی شتاب بهینه برای مدل شما در دستگاه تغییر کند. بنابراین هنگامی که پیکربندی شتاب رضایت بخشی را دریافت کردید، باید آن را در دستگاه ذخیره کنید و به برنامه خود اجازه دهید آن را بازیابی کند و از آن برای ایجاد InterpreterOptions خود در طول جلسات بعدی به جای اجرای اعتبارسنجی دیگر استفاده کند. متدهای serialize() و deserialize() در ValidatedAccelerationConfigResult فرآیند ذخیره سازی و بازیابی را آسان تر می کند.
نمونه برنامه
برای بررسی ادغام در محل سرویس شتاب، به برنامه نمونه نگاهی بیندازید.
محدودیت ها
سرویس شتاب دارای محدودیت های فعلی زیر است:
- در حال حاضر فقط پیکربندی های شتاب CPU و GPU پشتیبانی می شوند.
- این فقط LiteRT را در خدمات Google Play پشتیبانی می کند و اگر از نسخه همراه LiteRT استفاده می کنید نمی توانید از آن استفاده کنید.
- Acceleration Service SDK فقط از سطح API 22 و بالاتر پشتیبانی می کند.
هشدارها
لطفاً هشدارهای زیر را با دقت مرور کنید، به خصوص اگر قصد دارید از این SDK در تولید استفاده کنید:
قبل از خروج از بتا و انتشار نسخه پایدار برای API خدمات شتاب، یک SDK جدید منتشر خواهیم کرد که ممکن است تفاوت هایی با نسخه بتا فعلی داشته باشد. برای ادامه استفاده از سرویس شتاب، باید به این SDK جدید مهاجرت کنید و بهموقع بهروزرسانی برنامه خود را انجام دهید. انجام ندادن این کار ممکن است باعث شکستگی شود زیرا ممکن است SDK بتا پس از مدتی دیگر با خدمات Google Play سازگار نباشد.
هیچ تضمینی وجود ندارد که یک ویژگی خاص در API خدمات شتاب یا API به طور کلی در دسترس عموم قرار گیرد. ممکن است به طور نامحدود در بتا باقی بماند، خاموش شود، یا با سایر ویژگیها در بستههایی که برای مخاطبان توسعهدهنده خاص طراحی شدهاند ترکیب شود. برخی از ویژگیهای دارای API خدمات شتاب یا کل خود API ممکن است در نهایت به طور کلی در دسترس قرار گیرند، اما هیچ برنامه زمانی ثابتی برای این کار وجود ندارد.
شرایط و حریم خصوصی
شرایط خدمات
استفاده از APIهای سرویس شتاب تابع شرایط خدمات Google APIs است.
علاوه بر این، APIهای سرویس شتاب در حال حاضر در مرحله بتا هستند و به همین دلیل، با استفاده از آن، مشکلات احتمالی ذکر شده در بخش هشدارهای بالا را تأیید میکنید و تصدیق میکنید که سرویس شتاب ممکن است همیشه آنطور که مشخص شده است عمل نکند.
حریم خصوصی
وقتی از APIهای سرویس شتاب استفاده میکنید، پردازش دادههای ورودی (مانند تصاویر، ویدیو، متن) به طور کامل در دستگاه انجام میشود و سرویس شتاب آن دادهها را به سرورهای Google ارسال نمیکند . در نتیجه، میتوانید از APIهای ما برای پردازش دادههای ورودی استفاده کنید که نباید از دستگاه خارج شوند.
APIهای سرویس شتاب ممکن است گهگاه با سرورهای Google تماس بگیرند تا مواردی مانند رفع اشکال، مدلهای بهروزرسانی شده و اطلاعات سازگاری شتابدهنده سختافزاری را دریافت کنند. APIهای خدمات شتاب همچنین معیارهایی را درباره عملکرد و استفاده از APIهای موجود در برنامه شما به Google ارسال میکنند. Google از این دادههای اندازهگیری برای اندازهگیری عملکرد، اشکالزدایی، حفظ و بهبود APIها، و شناسایی سوء استفاده یا سوء استفاده استفاده میکند، همانطور که در خطمشی رازداری ما توضیح داده شده است.
شما مسئول اطلاع رسانی به کاربران برنامه خود در مورد پردازش داده های سنجه های سرویس شتاب توسط Google هستید که طبق قانون قابل اجرا الزامی است.
داده هایی که جمع آوری می کنیم شامل موارد زیر است:
- اطلاعات دستگاه (مانند سازنده، مدل، نسخه سیستم عامل و ساخت) و شتاب دهنده های سخت افزاری موجود ML (GPU و DSP). برای تشخیص و تجزیه و تحلیل استفاده استفاده می شود.
- اطلاعات برنامه (نام بسته / شناسه بسته، نسخه برنامه). برای تشخیص و تجزیه و تحلیل استفاده استفاده می شود.
- پیکربندی API (مانند فرمت و وضوح تصویر). برای تشخیص و تجزیه و تحلیل استفاده استفاده می شود.
- نوع رویداد (مانند مقداردهی اولیه، دانلود مدل، به روز رسانی، اجرا، شناسایی). برای تشخیص و تجزیه و تحلیل استفاده استفاده می شود.
- کدهای خطا برای تشخیص استفاده می شود.
- معیارهای عملکرد برای تشخیص استفاده می شود.
- شناسههای هر نصب که به طور منحصر به فرد کاربر یا دستگاه فیزیکی را شناسایی نمیکنند. برای عملیات پیکربندی از راه دور و تجزیه و تحلیل استفاده استفاده می شود.
- آدرس های IP فرستنده درخواست شبکه. برای تشخیص پیکربندی از راه دور استفاده می شود. آدرس های IP جمع آوری شده به طور موقت حفظ می شوند.
پشتیبانی و بازخورد
می توانید از طریق ردیاب مشکل TensorFlow بازخورد ارائه دهید و پشتیبانی دریافت کنید. لطفاً مشکلات و درخواستهای پشتیبانی را با استفاده از الگوی مشکل LiteRT در خدمات Google Play گزارش کنید.