
عملگرهای یادگیری ماشین (ML) که در مدل خود استفاده میکنید میتوانند بر فرآیند تبدیل یک مدل TensorFlow به فرمت LiteRT تأثیر بگذارند. مبدل LiteRT از تعداد محدودی از عملیات TensorFlow مورد استفاده در مدلهای استنتاج رایج پشتیبانی میکند، به این معنی که هر مدلی مستقیماً قابل تبدیل نیست. ابزار مبدل به شما امکان میدهد تا عملگرهای اضافی را نیز اضافه کنید، اما تبدیل یک مدل به این روش همچنین مستلزم تغییر محیط زمان اجرای LiteRT است که برای اجرای مدل خود استفاده میکنید، که میتواند توانایی شما را در استفاده از گزینههای استاندارد استقرار زمان اجرا، مانند سرویسهای Google Play ، محدود کند.
مبدل LiteRT برای تجزیه و تحلیل ساختار مدل و اعمال بهینهسازیها به منظور سازگاری آن با عملگرهای پشتیبانیشدهی مستقیم طراحی شده است. به عنوان مثال، بسته به عملگرهای یادگیری ماشین در مدل شما، مبدل ممکن است آن عملگرها را حذف یا ترکیب کند تا آنها را به همتایان LiteRT خود نگاشت کند.
حتی برای عملیات پشتیبانیشده، گاهی اوقات به دلایل عملکردی، الگوهای استفاده خاصی پیشبینی میشود. بهترین راه برای درک چگونگی ساخت یک مدل TensorFlow که بتوان با LiteRT از آن استفاده کرد، بررسی دقیق نحوه تبدیل و بهینهسازی عملیات، همراه با محدودیتهای اعمالشده توسط این فرآیند است.
اپراتورهای پشتیبانیشده
عملگرهای داخلی LiteRT زیرمجموعهای از عملگرهایی هستند که بخشی از کتابخانه اصلی TensorFlow هستند. مدل TensorFlow شما همچنین ممکن است شامل عملگرهای سفارشی به شکل عملگرهای مرکب یا عملگرهای جدیدی باشد که توسط شما تعریف شدهاند. نمودار زیر روابط بین این عملگرها را نشان میدهد.
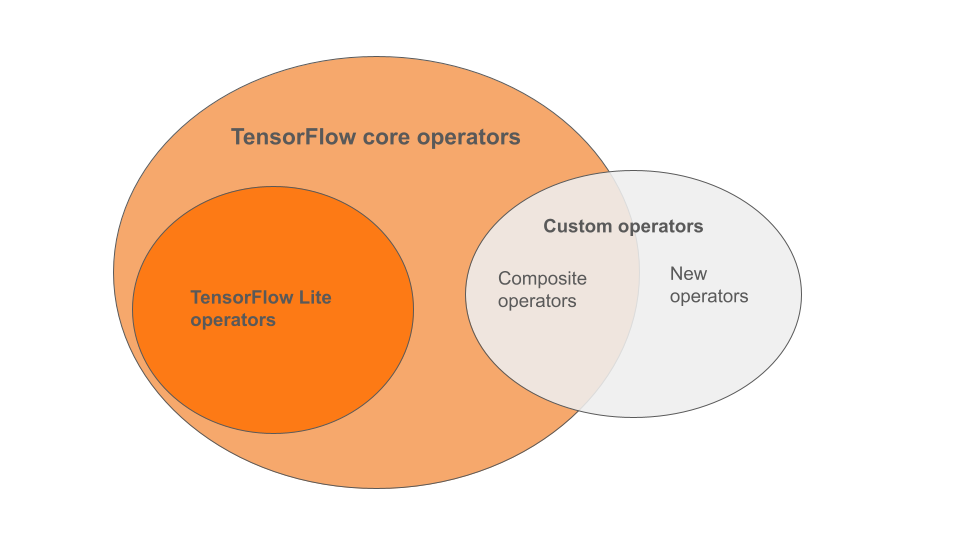
از این طیف عملگرهای مدل یادگیری ماشین، ۳ نوع مدل وجود دارد که توسط فرآیند تبدیل پشتیبانی میشوند:
- مدلهایی که فقط اپراتور داخلی LiteRT دارند. ( توصیه میشود )
- مدلها را با عملگرهای داخلی و عملگرهای اصلی TensorFlow انتخاب کنید.
- مدلهایی با عملگرهای داخلی، عملگرهای اصلی TensorFlow و/یا عملگرهای سفارشی.
اگر مدل شما فقط شامل عملیاتی است که به صورت بومی توسط LiteRT پشتیبانی میشوند، برای تبدیل آن به هیچ پرچم اضافی نیاز ندارید. این مسیر توصیه شده است زیرا این نوع مدل به راحتی تبدیل میشود و بهینهسازی و اجرای آن با استفاده از زمان اجرای پیشفرض LiteRT سادهتر است. همچنین گزینههای استقرار بیشتری برای مدل خود مانند سرویسهای Google Play دارید. میتوانید با راهنمای مبدل LiteRT شروع به کار کنید. برای مشاهده لیستی از عملگرهای داخلی، به صفحه LiteRT Ops مراجعه کنید.
اگر نیاز دارید که عملیاتهای منتخب TensorFlow را از کتابخانه اصلی اضافه کنید، باید آن را در زمان تبدیل مشخص کنید و مطمئن شوید که زمان اجرا شامل آن عملیاتها میشود. برای مراحل دقیقتر به مبحث «انتخاب عملگرهای TensorFlow» مراجعه کنید.
هر زمان که ممکن است، از آخرین گزینه یعنی گنجاندن عملگرهای سفارشی در مدل تبدیلشده خود اجتناب کنید. عملگرهای سفارشی یا عملگرهایی هستند که با ترکیب چندین عملگر اصلی اولیه TensorFlow ایجاد میشوند یا یک عملگر کاملاً جدید تعریف میکنند. وقتی عملگرهای سفارشی تبدیل میشوند، میتوانند با ایجاد وابستگیهایی خارج از کتابخانه داخلی LiteRT، اندازه کلی مدل را افزایش دهند. عملیات سفارشی، اگر بهطور خاص برای استقرار موبایل یا دستگاه ایجاد نشده باشند، میتوانند در مقایسه با محیط سرور، هنگام استقرار در دستگاههای با منابع محدود، عملکرد بدتری داشته باشند. در نهایت، درست مانند گنجاندن عملگرهای اصلی منتخب TensorFlow، عملگرهای سفارشی شما را ملزم به تغییر محیط زمان اجرای مدل میکنند که شما را از استفاده از سرویسهای زمان اجرای استاندارد مانند سرویسهای Google Play محدود میکند.
انواع پشتیبانی شده
بیشتر عملیات LiteRT هم استنتاج ممیز شناور ( float32 ) و هم استنتاج کوانتیزه ( uint8 , int8 ) را هدف قرار میدهند، اما بسیاری از عملیاتها هنوز برای انواع دیگر مانند tf.float16 و رشتهها این کار را نمیکنند.
جدا از استفاده از نسخههای مختلف عملیات، تفاوت دیگر بین مدلهای ممیز شناور و کوانتیزه، نحوه تبدیل آنهاست. تبدیل کوانتیزه به اطلاعات محدوده دینامیکی برای تانسورها نیاز دارد. این امر مستلزم "کوانتیزهسازی جعلی" در طول آموزش مدل، دریافت اطلاعات محدوده از طریق یک مجموعه داده کالیبراسیون یا انجام تخمین محدوده "در حال اجرا" است. برای جزئیات بیشتر به کوانتیزهسازی مراجعه کنید.
تبدیلهای سرراست، تا کردن مداوم و ترکیب
تعدادی از عملیات TensorFlow میتوانند توسط LiteRT پردازش شوند، حتی اگر معادل مستقیمی نداشته باشند. این مورد در مورد عملیاتی صدق میکند که میتوانند به سادگی از گراف حذف شوند ( tf.identity )، با تانسورها جایگزین شوند ( tf.placeholder ) یا در عملیات پیچیدهتر ادغام شوند ( tf.nn.bias_add ). حتی برخی از عملیات پشتیبانی شده ممکن است گاهی اوقات از طریق یکی از این فرآیندها حذف شوند.
در اینجا لیستی غیر جامع از عملیات TensorFlow که معمولاً از نمودار حذف میشوند، آورده شده است:
-
tf.add -
tf.debugging.check_numerics -
tf.constant -
tf.div -
tf.divide -
tf.fake_quant_with_min_max_args -
tf.fake_quant_with_min_max_vars -
tf.identity -
tf.maximum -
tf.minimum -
tf.multiply -
tf.no_op -
tf.placeholder -
tf.placeholder_with_default -
tf.realdiv -
tf.reduce_max -
tf.reduce_min -
tf.reduce_sum -
tf.rsqrt -
tf.shape -
tf.sqrt -
tf.square -
tf.subtract -
tf.tile -
tf.nn.batch_norm_with_global_normalization -
tf.nn.bias_add -
tf.nn.fused_batch_norm -
tf.nn.relu -
tf.nn.relu6
عملیات آزمایشی
عملیات LiteRT زیر موجود است، اما برای مدلهای سفارشی آماده نیست:
-
CALL -
CONCAT_EMBEDDINGS -
CUSTOM -
EMBEDDING_LOOKUP_SPARSE -
HASHTABLE_LOOKUP -
LSH_PROJECTION -
SKIP_GRAM -
SVDF