
למכשירי Edge יש לרוב זיכרון מוגבל או כוח מחשוב מוגבל. אפשר להחיל על המודלים אופטימיזציות שונות כדי להפעיל אותם במסגרת המגבלות האלה. בנוסף, חלק מהאופטימיזציות מאפשרות שימוש בחומרה ייעודית להסקת מסקנות מואצת.
LiteRT וTensorFlow Model Optimization Toolkit מספקים כלים לצמצום המורכבות של אופטימיזציית ההסקה.
מומלץ לבצע אופטימיזציה של המודל במהלך תהליך פיתוח האפליקציה. במסמך הזה מפורטות כמה שיטות מומלצות לאופטימיזציה של מודלים של TensorFlow לצורך פריסה בחומרה של Edge.
למה כדאי לבצע אופטימיזציה של מודלים
יש כמה דרכים עיקריות שבהן אופטימיזציה של מודלים יכולה לעזור בפיתוח אפליקציות.
הקטנת הגודל
אפשר להשתמש בסוגים מסוימים של אופטימיזציה כדי להקטין את הגודל של מודל. היתרונות של מודלים קטנים יותר:
- גודל אחסון קטן יותר: מודלים קטנים יותר תופסים פחות נפח אחסון במכשירים של המשתמשים. לדוגמה, אפליקציית Android שמשתמשת במודל קטן יותר תתפוס פחות נפח אחסון בנייד של המשתמש.
- גודל הורדה קטן יותר: מודלים קטנים יותר דורשים פחות זמן ורוחב פס כדי להוריד אותם למכשירים של המשתמשים.
- פחות שימוש בזיכרון: מודלים קטנים יותר משתמשים בפחות זיכרון RAM כשהם פועלים, מה שמשחרר זיכרון לשימוש בחלקים אחרים של האפליקציה, ויכול לשפר את הביצועים והיציבות.
בכל המקרים האלה, קוונטיזציה יכולה להקטין את הגודל של מודל, אבל יכול להיות שזה יפגע ברמת הדיוק. גיזום וקיבוץ יכולים להקטין את הגודל של מודל להורדה, כי הם מאפשרים דחיסה קלה יותר.
הפחתת זמן הטעינה
זמן האחזור הוא משך הזמן שנדרש להפעלת מסקנה יחידה עם מודל נתון. חלק מהאופטימיזציות יכולות להפחית את כמות החישובים שנדרשת כדי להריץ הסקה באמצעות מודל, וכתוצאה מכך להקטין את זמן האחזור. זמן האחזור יכול להשפיע גם על צריכת החשמל.
נכון לעכשיו, אפשר להשתמש בקוונטיזציה כדי להפחית את זמן האחזור על ידי פישוט החישובים שמתבצעים במהלך ההסקה, אבל יכול להיות שהדיוק ייפגע.
תאימות למאיץ
חלק מהמאיצים לחומרה, כמו Edge TPU, יכולים להריץ הסקה מהר מאוד עם מודלים שעברו אופטימיזציה נכונה.
בדרך כלל, כדי להשתמש במודלים במכשירים מהסוגים האלה צריך לבצע קוונטיזציה של המודלים בצורה ספציפית. מידע נוסף על הדרישות של כל מאיץ חומרה זמין במסמכי התיעוד שלו.
השפעות
אופטימיזציות יכולות להוביל לשינויים ברמת הדיוק של המודל, וצריך לקחת זאת בחשבון במהלך תהליך פיתוח האפליקציה.
השינויים ברמת הדיוק תלויים במודל הספציפי שעובר אופטימיזציה, וקשה לחזות אותם מראש. באופן כללי, מודלים שעברו אופטימיזציה לגודל או לזמן האחזור יהיו פחות מדויקים. בהתאם לאפליקציה, יכול להיות שהשינוי הזה ישפיע על חוויית המשתמשים ויכול להיות שלא. במקרים נדירים, מודלים מסוימים עשויים להפוך מדויקים יותר כתוצאה מתהליך האופטימיזציה.
סוגי אופטימיזציה
נכון לעכשיו, LiteRT תומך באופטימיזציה באמצעות קוונטיזציה, גיזום וקיבוץ לאשכולות.
הם חלק מTensorFlow Model Optimization Toolkit, שמספק משאבים לטכניקות אופטימיזציה של מודלים שתואמות ל-TensorFlow Lite.
קוונטיזציה
קוונטיזציה פועלת על ידי צמצום הדיוק של המספרים שמשמשים לייצוג הפרמטרים של מודל, שהם כברירת מחדל מספרים ממשיים של 32 ביט. כך מתקבל מודל קטן יותר וחישוב מהיר יותר.
אלה סוגי הכימות שזמינים ב-LiteRT:
| טכניקה | הדרישות לגבי הנתונים | הקטנת הגודל | דיוק | חומרה נתמכת |
|---|---|---|---|---|
| כימות float16 אחרי האימון | אין נתונים | עד 50% | ירידה זניחה ברמת הדיוק | מעבד, GPU |
| Post-training dynamic range quantization | אין נתונים | עד 75% | הכי פחות איבוד דיוק | מעבד (CPU), מעבד גרפי (GPU) (Android) |
| Post-training integer quantization | מדגם מייצג ללא תווית | עד 75% | ירידה קלה ברמת הדיוק | מעבד (CPU), מעבד גרפי (GPU) (Android), EdgeTPU |
| אימון עם התחשבות בקוונטיזציה | נתוני אימון מתויגים | עד 75% | הכי פחות איבוד דיוק | מעבד (CPU), מעבד גרפי (GPU) (Android), EdgeTPU |
עץ ההחלטות הבא עוזר לכם לבחור את סכימות הכמותיות שבהן כדאי להשתמש במודל, על סמך הגודל והדיוק הצפויים של המודל.
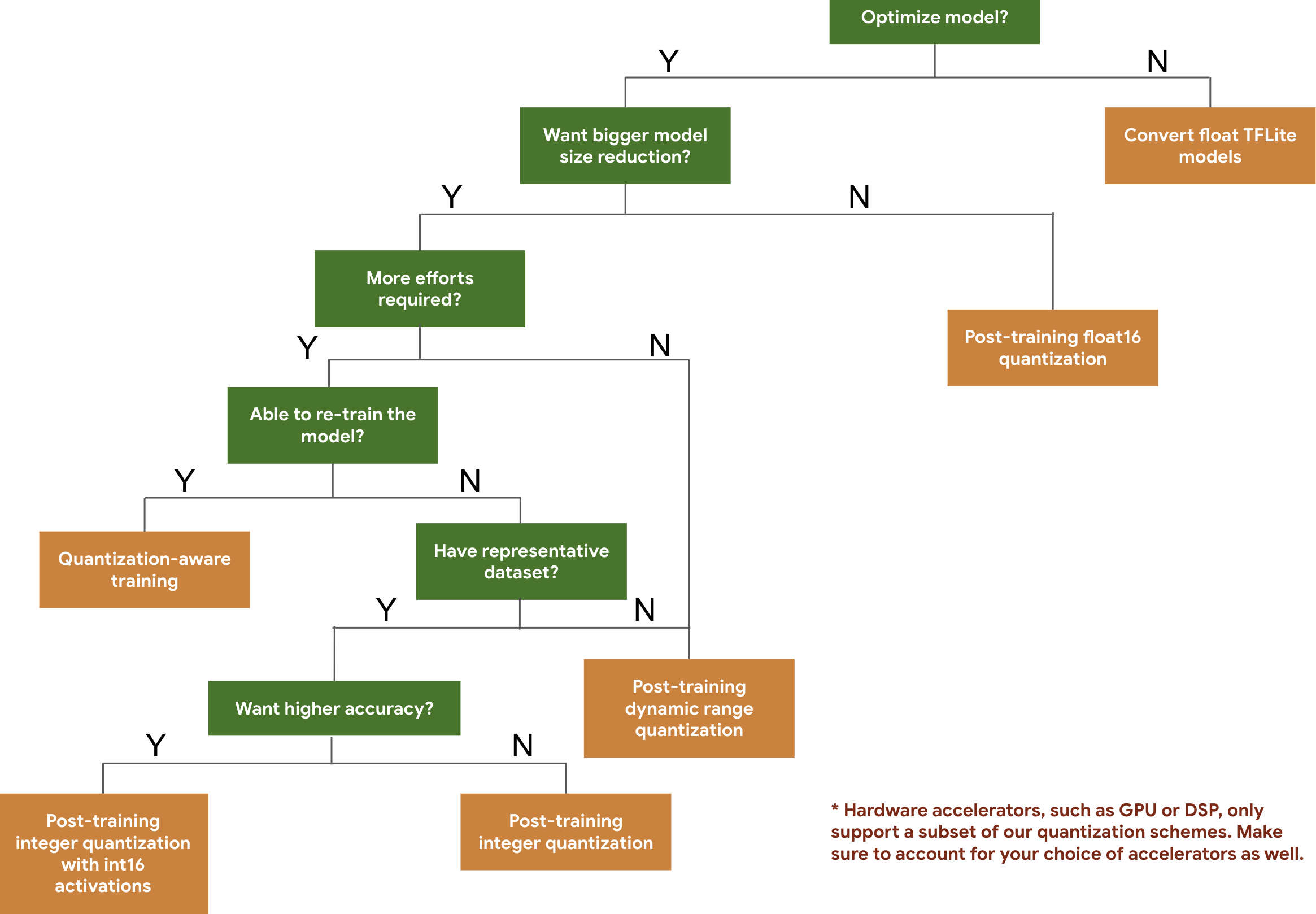
בהמשך מופיעות תוצאות של זמן האחזור והדיוק של כימות אחרי אימון ושל אימון עם כימות בכמה מודלים. כל מספרי ההשהיה נמדדים במכשירי Pixel 2 באמצעות CPU עם ליבה גדולה אחת. ככל שהערכה תשתפר, כך ישתפרו גם הנתונים שמוצגים כאן:
| דגם | דיוק בתוצאה הראשונה (מקורי) | דיוק ברמה העליונה (לאחר כימות) | דיוק במיקום הראשון (אימון עם מודעות לכמויות) | זמן האחזור (המקורי) (באלפיות השנייה) | זמן האחזור (לאחר הכשרה וכימות) (אלפיות השנייה) | זמן אחזור (אימון עם מודעות לקוונטיזציה) (באלפיות השנייה) | גודל (מקורי) (MB) | גודל (אופטימלי) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | לא רלוונטי | 3973 | 2868 | לא רלוונטי | 178.3 | 44.9 |
קוונטיזציה מלאה של מספרים שלמים עם הפעלות int16 ומשקלים int8
Quantization with int16 activations is a full integer quantization scheme with activations in int16 and weights in int8. המצב הזה יכול לשפר את הדיוק של המודל הכמותי בהשוואה לסכמת הכמותיות המלאה של מספרים שלמים עם הפעלות ומשקלים ב-int8, תוך שמירה על גודל מודל דומה. מומלץ להשתמש בה כשפעולות ההפעלה רגישות לקוונטיזציה.
הערה: נכון לעכשיו, ב-TFLite זמינות רק הטמעות של ליבות הפניה לא אופטימליות של סכימת הכימות הזו, ולכן כברירת מחדל הביצועים יהיו איטיים בהשוואה לליבות int8. כדי ליהנות מכל היתרונות של המצב הזה, צריך כרגע חומרה ייעודית או תוכנה בהתאמה אישית.
בהמשך מופיעות תוצאות הדיוק של כמה מודלים שמופיעים במצב הזה.
| דגם | סוג מדד הדיוק | דיוק (הפעלות float32) | דיוק (הפעלות int8) | דיוק (הפעלות int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | דיוק במיקום הראשון | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | רמת הדיוק של התוצאה הראשונה | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(התאמה מדויקת) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
גיזום
גיזום פועל על ידי הסרת פרמטרים במודל שיש להם השפעה קלה בלבד על התחזיות שלו. הגודל של מודלים שעברו גיזום בדיסק זהה לגודל של מודלים שלא עברו גיזום, והחביון בזמן הריצה זהה, אבל אפשר לדחוס אותם בצורה יעילה יותר. לכן, גיזום הוא טכניקה שימושית להקטנת גודל ההורדה של המודל.
בעתיד, LiteRT יספק הפחתה של זמן האחזור עבור מודלים שעברו גיזום.
סידור באשכול
אשכולות פועלים על ידי קיבוץ המשקלים של כל שכבה במודל למספר מוגדר מראש של אשכולות, ואז שיתוף ערכי מרכז המסה של המשקלים ששייכים לכל אשכול בנפרד. כך מצמצמים את מספר ערכי המשקל הייחודיים במודל, ולכן גם את המורכבות שלו.
כתוצאה מכך, אפשר לדחוס מודלים מקובצים בצורה יעילה יותר, וליהנות מיתרונות בפריסה שדומים לאלה של גיזום.
תהליך עבודה של פיתוח
כנקודת התחלה, כדאי לבדוק אם המודלים במודלים מתארחים יכולים להתאים לאפליקציה שלכם. אם לא, מומלץ למשתמשים להתחיל עם כלי הכימות אחרי האימון, כי הוא מתאים לשימוש נרחב ולא דורש נתוני אימון.
במקרים שבהם לא עומדים ביעדי הדיוק וזמן האחזור, או שחשוב לקבל תמיכה בהאצת חומרה, אימון עם התחשבות בקוונטיזציה היא האפשרות הטובה יותר. טכניקות אופטימיזציה נוספות מפורטות בערכת הכלים לאופטימיזציה של מודלים של TensorFlow.
כדי להקטין עוד יותר את גודל המודל, אפשר לנסות גיזום או אשכול לפני הכימות של המודלים.