
トレーニング後の量子化は、モデルの精度をほとんど低下させることなくモデルサイズを縮小しつつ、CPU とハードウェア アクセラレータ レイテンシを改善できる変換手法です。LiteRT コンバータを使用して、トレーニング済みの浮動小数点演算を行う TensorFlow モデルを LiteRT 形式に変換する際に、量子化できます。
最適化の方法
トレーニング後の量子化オプションは複数あります。選択肢とそのメリットの概要を表にまとめました。
| 手法 | 利点 | ハードウェア |
|---|---|---|
| ダイナミック レンジの量子化 | 4 分の 1 のサイズ、2 ~ 3 倍の高速化 | CPU |
| 完全な整数量子化 | 4 分の 1 のサイズ、3 倍以上の高速化 | CPU、Edge TPU、マイクロコントローラ |
| Float16 量子化 | 2 倍小さく、GPU アクセラレーション | CPU、GPU |
次のディシジョン ツリーは、ユースケースに最適なトレーニング後の量子化方法を判断する際に役立ちます。
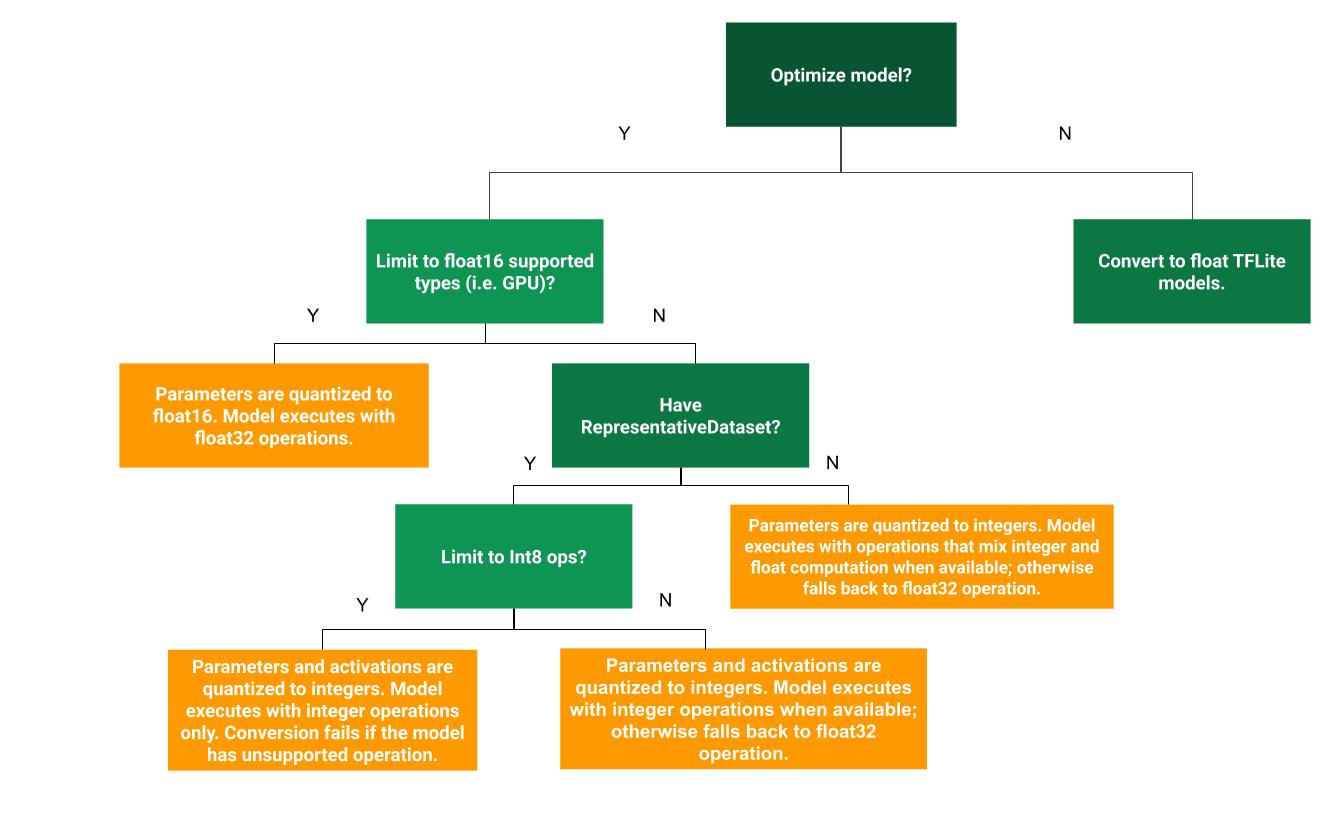
量子化なし
量子化せずに TFLite モデルに変換することをおすすめします。これにより、浮動小数点 TFLite モデルが生成されます。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
これは、元の TF モデルの演算子が TFLite と互換性があることを確認するための最初の手順として行うことをおすすめします。また、後続のトレーニング後の量子化手法によって発生した量子化エラーをデバッグするためのベースラインとしても使用できます。たとえば、量子化された TFLite モデルが予期しない結果を生成し、浮動小数点 TFLite モデルが正確である場合、問題は TFLite オペレーターの量子化バージョンによって導入されたエラーに絞り込むことができます。
ダイナミック レンジの量子化
動的範囲量子化では、キャリブレーション用の代表的なデータセットを提供することなく、メモリ使用量を削減し、計算を高速化できます。このタイプの量子化では、変換時に浮動小数点から整数への重みのみを静的に量子化し、8 ビットの精度を提供します。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
推論中のレイテンシをさらに短縮するために、「ダイナミック レンジ」演算子は、アクティベーションの範囲に基づいてアクティベーションを 8 ビットに動的に量子化し、8 ビットの重みとアクティベーションを使用して計算を実行します。この最適化により、完全な固定小数点推論に近いレイテンシが実現します。ただし、出力は浮動小数点を使用して保存されるため、動的範囲演算の速度向上は固定小数点演算全体よりも小さくなります。
完全な整数量子化
モデルのすべての計算が整数で量子化されていることを確認することで、レイテンシをさらに改善し、ピーク時のメモリ使用量を削減し、整数のみのハードウェア デバイスまたはアクセラレータとの互換性を確保できます。
整数量子化を行うには、範囲を調整または推定する必要があります。モデル内のすべての浮動小数点テンソルの(最小値、最大値)。重みやバイアスなどの定数テンソルとは異なり、モデル入力、アクティベーション(中間レイヤの出力)、モデル出力などの変数テンソルは、推論サイクルを数回実行しないと調整できません。そのため、コンバータの調整には代表的なデータセットが必要です。このデータセットは、トレーニング データまたは検証データの小さなサブセット(約 100 ~ 500 個のサンプル)にできます。以下の representative_dataset() 関数を参照してください。
TensorFlow 2.7 以降のバージョンでは、次の例のように、シグネチャを使用して代表的なデータセットを指定できます。
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
指定された TensorFlow モデルに複数のシグネチャがある場合は、シグネチャキーを指定して複数のデータセットを指定できます。
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
代表的なデータセットは、入力テンソルのリストを指定して生成できます。
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 以降のバージョンでは、入力テンソルの順序が簡単に反転する可能性があるため、入力テンソル リストベースのアプローチよりもシグネチャ ベースのアプローチを使用することをおすすめします。
テスト目的で、次のようにダミー データセットを使用できます。
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
浮動小数点フォールバック付きの整数(デフォルトの浮動小数点入出力を使用)
モデルを完全に整数量子化し、整数実装がない場合は浮動小数点演算子を使用する(変換がスムーズに行われるようにする)には、次の手順を行います。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
整数のみ
整数のみのモデルの作成は、マイクロコントローラ用 LiteRT と Coral Edge TPU の一般的なユースケースです。
また、整数のみのデバイス(8 ビット マイクロコントローラなど)やアクセラレータ(Coral Edge TPU など)との互換性を確保するため、次の手順で入力と出力を含むすべてのオペレーションに対して完全な整数量子化を適用できます。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 量子化
重みを float16(16 ビット浮動小数点数の IEEE 標準)に量子化することで、浮動小数点モデルのサイズを縮小できます。重みの float16 量子化を有効にする手順は次のとおりです。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 量子化の利点は次のとおりです。
- これにより、モデルサイズが最大で半分になります(すべての重みが元のサイズの半分になるため)。
- 精度が低下する程度は最小限です。
- float16 データで直接動作できるデリゲート(GPU デリゲートなど)をサポートしているため、float32 計算よりも高速に実行できます。
float16 量子化のデメリットは次のとおりです。
- 固定小数点演算への量子化ほどレイテンシは減少しません。
- デフォルトでは、float16 量子化モデルは CPU で実行されるときに重み値を float32 に「逆量子化」します。(GPU デリゲートは float16 データで動作できるため、この逆量子化は実行しません)。
整数のみ: 8 ビットの重みを持つ 16 ビットのアクティベーション(試験運用版)
これは試験運用中の量子化スキームです。「整数のみ」のスキームに似ていますが、アクティベーションは範囲に基づいて 16 ビットに量子化され、重みは 8 ビット整数に量子化され、バイアスは 64 ビット整数に量子化されます。これを 16x8 量子化と呼びます。
この量子化の主な利点は、精度を大幅に向上させながら、モデルサイズをわずかに増やすだけであることです。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
モデル内の演算子の一部で 16x8 量子化がサポートされていない場合でも、モデルを量子化できますが、サポートされていない演算子は浮動小数点数のままになります。これを許可するには、次のオプションを target_spec に追加する必要があります。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
この量子化スキームによって精度が向上するユースケースの例は次のとおりです。
- 超解像度、
- ノイズ キャンセルやビームフォーミングなどの音声信号処理、
- 画像ノイズ除去、
- 単一の画像から HDR を再構築します。
この量子化のデメリットは次のとおりです。
- 現在、最適化されたカーネル実装がないため、推論は 8 ビットの完全な整数よりも大幅に遅くなっています。
- 現在、既存のハードウェア アクセラレータ TFLite デリゲートとは互換性がありません。
この量子化モードのチュートリアルについては、こちらをご覧ください。
モデルの精度
重みはトレーニング後に量子化されるため、特に小規模なネットワークでは精度が低下する可能性があります。事前トレーニング済みの完全量子化モデルは、Kaggle Models で特定のネットワーク用に提供されています。量子化モデルの精度をチェックして、精度の低下が許容範囲内であることを確認することが重要です。LiteRT モデルの精度を評価するツールがあります。
また、精度低下が大きすぎる場合は、量子化認識トレーニングの使用を検討してください。ただし、これを行うには、モデルのトレーニング中に変更を加えて偽の量子化ノードを追加する必要があります。一方、このページのトレーニング後の量子化手法では、既存の事前トレーニング済みモデルを使用します。
量子化テンソルの表現
8 ビット量子化では、次の式を使用して浮動小数点値を近似します。
\[real\_value = (int8\_value - zero\_point) \times scale\]
この表現には、次の 2 つの主要な部分があります。
軸ごと(チャネルごと)またはテンソルごとの重み。ゼロポイントが 0 の範囲 [-127, 127] の int8 2 の補数値で表されます。
テンソルごとのアクティベーション/入力は、範囲 [-128, 127] の int8 2 の補数値で表され、ゼロポイントは範囲 [-128, 127] にあります。
量子化スキームの詳細については、量子化仕様をご覧ください。TensorFlow Lite のデリゲート インターフェースに接続したいハードウェア ベンダーは、そこに記載されている量子化スキームを実装することをおすすめします。