
LiteRT は、エッジ プラットフォームでのハイ パフォーマンス ML と生成 AI のデプロイのための Google のオンデバイス フレームワークです。
デバイス上の ML の効率的な変換、ランタイム、最適化。
TensorFlow Lite の実績ある基盤上に構築
LiteRT は単に新しいだけでなく、世界で最も広く導入されている機械学習ランタイムの次世代版です。この技術は、日常的に使用するアプリを支え、数十億台のデバイスで低レイテンシと高いプライバシー保護を実現しています。
最も重要な Google アプリで信頼されている
10 万件以上のアプリケーション、数十億人のグローバル ユーザー
LiteRT のハイライト

クロス プラットフォーム対応

Unleash GenAI
簡素化されたハードウェア アクセラレーション

マルチ フレームワークのサポート
LiteRT 経由でデプロイする
トレーニングからデバイス上でのデプロイまで、ディープ ラーニングのワークフローを効率化します。

1.モデルを取得する
.tflite 事前トレーニング済みモデルを使用するか、PyTorch、JAX、TensorFlow のモデルを .tflite に変換します。

2.最適化
LiteRT 最適化ツールキットを使用して、トレーニング後にモデルを量子化します。

3.Run
LiteRT を使用してモデルをデプロイし、アプリに最適なアクセラレータを選択します。
開発パスを選択する
LiteRT を使用して、高性能なモバイルアプリからリソースが制限された IoT デバイスまで、あらゆる場所に AI をデプロイできます。
既存の TFLite ユーザー
LiteRT に移行して、プラットフォーム(Android、デスクトップ、ウェブ)全体でパフォーマンスの向上と API の統合を実現します。
BYOM : Bring your own Models
PyTorch モデルがあり、オンデバイスのビジョンまたはオーディオ エクスペリエンスを実装したい。
生成 AI モデルのデプロイ
Gemma などの最適化されたオープンウェイト生成 AI モデルや、その他のオープンウェイト モデルを使用して、高度なオンデバイス chatbot を作成する。
[上級] モデル エキスパート
カスタムモデルの作成、またはピーク パフォーマンスを実現するためのハードウェア固有の CPU/GPU/NPU の詳細な最適化。
サンプル、モデル、デモ

GitHub の LiteRT サンプルアプリを参照してください
完全なエンドツーエンドのサンプルアプリ。

生成 AI モデルを参照する
事前トレーニング済みで、すぐに使用できる生成 AI モデル。

デモを見る - Google AI Edge ギャラリー アプリ
LiteRT を使用したオンデバイス ML/生成 AI のユースケースを紹介するギャラリー。
ブログとお知らせ
LiteRT チームからの最新のお知らせ、技術的な解説、パフォーマンス ベンチマークを常に把握できます。

LiteRT と NPU を使用した現実世界のオンデバイス AI の構築
業界のリーダーが LiteRT と NPU を使用して、実際の高性能なオンデバイス AI アプリケーションを構築する方法について説明します。
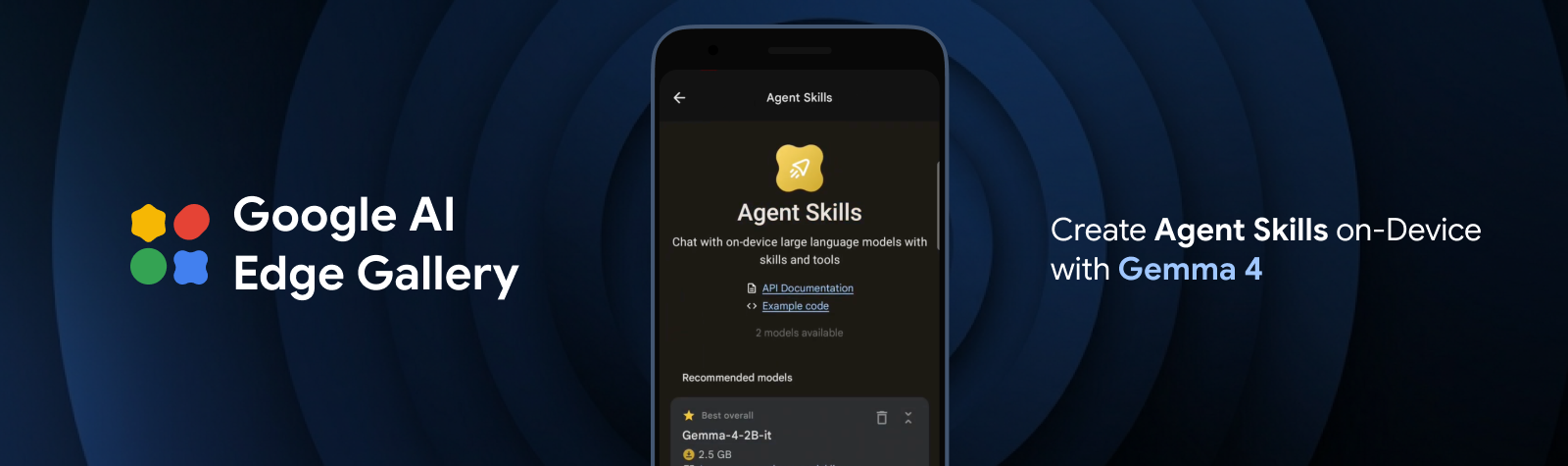
Gemma 4 で最先端のエージェント スキルをエッジに導入する
新しい Gemma 4 ファミリーと LiteRT を使用して、エージェント型とマルチステップ プランニング機能を完全にオンデバイスでデプロイします。

LiteRT: オンデバイス AI のためのユニバーサル フレームワーク
Google の統合オンデバイス ML フレームワーク。高性能なデプロイのために TFLite から進化しました。
MediaTek NPU と LiteRT: 次世代のオンデバイス AI を実現
高効率の AI を実現するため、MediaTek チップセットへの NPU アクセラレーション サポートを拡大。
LiteRT で Qualcomm NPU のパフォーマンスを最大限に引き出す
Qualcomm ニューラル プロセッシング ユニットで生成 AI の画期的なパフォーマンスを実現。

LiteRT: 最大限のパフォーマンスを簡素化
ハードウェアの自動選択と非同期実行のための CompiledModel API を導入しました。
LiteRT-LM を搭載した Chrome、Chromebook Plus、Google Pixel Watch のオンデバイス生成 AI
LiteRT-LM を使用して、ウェアラブルやブラウザベースのプラットフォームに言語モデルをデプロイします。

Google AI Edge の小規模言語モデル、マルチモーダル、関数呼び出し
エッジ言語モデルの RAG、マルチモダリティ、関数呼び出しに関する最新の分析情報
コミュニティに参加
LiteRT GitHub コミュニティ
プロジェクトに直接貢献し、コア デベロッパーとコラボレーションします。

Hugging Face Hub
Hugging Face Hub で最適化されたオープンウェイト モデルにアクセスします。