Imagen は、Google の高忠実度画像生成モデルです。テキスト プロンプトからリアルで高品質な画像を生成できます。すべての生成画像には SynthID の透かしが埋め込まれています。使用可能な Imagen モデル バリエーションの詳細については、モデル バージョンをご覧ください。
Imagen モデルを使用して画像を生成する
次の例は、Imagen モデルを使用して画像を生成する方法を示しています。
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen の構成
Imagen は現在、英語のプロンプトと次のパラメータのみをサポートしています。
numberOfImages: 生成する画像の数(1 ~ 4)。デフォルトは 4 です。imageSize: 生成される画像のサイズ。これは、Standard モデルと Ultra モデルでのみサポートされています。サポートされている値は1Kと2Kです。デフォルトは1Kです。aspectRatio: 生成された画像のアスペクト比を変更します。サポートされている値は"1:1"、"3:4"、"4:3"、"9:16"、"16:9"です。デフォルトは"1:1"です。personGeneration: モデルが人物の画像を生成できるようにします。次の値を使用できます。"dont_allow": 人物の画像の生成をブロックします。"allow_adult": 大人の画像を生成しますが、子供の画像は生成しません。これがデフォルトです。"allow_all": 大人や子供の画像が生成されます。
Imagen プロンプト ガイド
Imagen ガイドのこのセクションでは、テキスト画像変換プロンプトを変更して異なる結果を生成する方法と、作成できる画像の例について説明します。
プロンプト作成の基本
適切なプロンプトは、説明的で明確であり、意味のあるキーワードと修飾子を使用しています。まず、主題、コンテキスト、スタイルについて考えてみましょう。

主題: プロンプトについて最初に考えるべきなのは主題、すなわち画像の主体となる物体、人物、動物、風景などです。
コンテキストと背景: その主題が配置される背景やコンテキストも同様に重要です。主題をさまざまな背景に置いてみてください。たとえば、スタジオの白い背景、屋外、屋内の環境などです。
スタイル: 最後に、希望する画像のスタイルを追加します。スタイルは、概括的なもの(絵画、写真、スケッチ)でも、特定化されたもの(パステル画、木炭画、アイソメトリック 3D)でもかまいません。スタイルを組み合わせることもできます。
プロンプトの最初のバージョンを作成したら、目的の画像が得られるまで詳細を追加してプロンプトを改良します。反復処理が重要です。まずコアアイデアを定義し、生成された画像がビジョンに近づくまで、そのコアアイデアを絞り込み、拡張します。

|

|

|
Imagen モデルは、プロンプトが短くても、長くて詳細でも、アイデアを詳細な画像に変換できます。反復的なプロンプトを通じてビジョンを絞り込み、完璧な結果が得られるまで詳細を追加します。
|
短いプロンプトを使用すると、画像をすばやく生成できます。 
|
長いプロンプトを使用すると、具体的な詳細を追加して画像を作成できます。 
|
Imagen プロンプトの作成に関するその他のヒント:
- わかりやすい表現を使用する: 具体的な形容詞や副詞を使用して、Imagen の明確な画像を描きます。
- コンテキストを提供する: 必要に応じて、AI の理解を助けるために背景情報を含めます。
- 特定のアーティストやスタイルを参照する: 特定の美学を念頭に置いている場合は、特定のアーティストや芸術運動を参照すると役に立ちます。
- プロンプト エンジニアリング ツールを使用する: プロンプトを改良して最適な結果を得るために、プロンプト エンジニアリング ツールやリソースの使用をおすすめします。
- 個人写真やグループ写真の顔の細部を補正する: 写真の焦点として顔の細部を指定します(たとえば、プロンプトで「ポートレート」という単語を使用します)。
画像内のテキストを生成する
Imagen モデルは画像にテキストを追加できるため、よりクリエイティブな画像生成が可能になります。この機能を最大限に活用するには、次のガイダンスに沿って操作してください。
- 確実に反復処理する: 目的の外観になるまで画像を再生成しなければならない場合があります。Imagen のテキスト統合は現在も進化しており、複数回試行することで最良の結果が得られることもあります。
- テキストを短くする: 生成を最適化するには、テキストを 25 文字以下に制限します。
複数のフレーズ: 2 つから 3 つの異なるフレーズをテストして、追加情報を提供します。クリーンな構成にするため、フレーズは 3 つを超えないようにします。

プロンプト: タイトルとして太字のフォントで「Summerland」というテキストが書かれたポスター。このテキストの下には「Summer never felt so good」というスローガンが書かれています ガイド付き配置: Imagen は指示どおりにテキストを配置しようとしますが、場合によっては変動が生じることがあります。この機能は継続的に改善されています。
フォント スタイルを引き出す: 一般的なフォント スタイルを指定して、Imagen の選択に微妙な影響を与えます。正確なフォント レプリケーションに依存せず、クリエイティブな解釈を想定してください。
フォントサイズ: フォントサイズまたはサイズの一般的な指標(小、中、大など)を指定して、フォントサイズの生成に影響を与えます。
プロンプトのパラメータ化
出力結果をより適切に制御するには、Imagen への入力をパラメータ化すると便利です。たとえば、お客様がビジネスのロゴを生成できるようにし、ロゴが常に単色の背景で生成されるようにしたいとします。また、クライアントがメニューから選択できるオプションを制限することもできます。
この例では、次のようなパラメータ化されたプロンプトを作成できます。
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.カスタム ユーザー インターフェースでは、ユーザーはメニューを使用してパラメータを入力できます。選択した値が、Imagen が受け取るプロンプトに入力されます。
次に例を示します。
プロンプト:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
プロンプト:
A modern logo for a software company on a solid color background. Include the text Silo.
プロンプト:
A traditional logo for a baking company on a solid color background. Include the text Seed.
高度なプロンプト作成手法
以下の例を使用すると、属性(写真の記述子、形状と素材、歴史的な芸術運動、画質の修飾子など)に基づいて、より具体的なプロンプトを作成できます。
写真
- プロンプトに「...の写真」が含まれる
このスタイルを使用するには、まず、写真を探していることを Imagen に明確に伝えるキーワードを使用します。プロンプトに「...の写真」と記述します。例を示します。

|

|

|
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 4 モデルを使用して生成されました。
写真の修飾子
次の例では、写真に固有のいくつかの修飾子とパラメータを見ることができます。複数の修飾子を組み合わせて、より正確に制御できます。
カメラの近接性 - クローズアップ、遠くから撮影

プロンプト: コーヒー豆のクローズアップ写真 
プロンプト: 散らかったキッチンに置かれた
コーヒー豆の小さな袋のズームアウト写真カメラの位置 - 空中、下から

プロンプト: 高層ビルがそびえる都会の航空写真 
プロンプト: 下から撮影した青空と林冠の写真 照明 - 自然、ドラマチック、暖かい、寒い

プロンプト: モダンなアームチェアのスタジオ写真、自然光 
プロンプト: モダンなアームチェアのスタジオ写真、ドラマチックな照明 カメラの設定 - モーション ブラー、ソフト フォーカス、ボケ、ポートレート

プロンプト: 高層ビルがそびえる都会を社内から撮影したモーション ブラーのある写真 
プロンプト: 都会の橋を夜間に撮影したソフト フォーカスの写真 レンズの種類 - 35 mm、50 mm、魚眼、広角、マクロ

プロンプト: 葉の写真、マクロレンズ 
プロンプト: 街路写真、ニューヨーク市、魚眼レンズ フィルムの種類 - モノクロ、ポラロイド

プロンプト: サングラスをかけた犬のポラロイド ポートレート 
プロンプト: サングラスをかけた犬のモノクロ写真
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 4 モデルを使用して生成されました。
イラストとアート
- プロンプトには、「...のpainting」、「...のsketch」という表現を含めます。
アートのスタイルは、鉛筆のスケッチなどのモノクロ スタイルから、ハイパーリアルなデジタルアートまで、多岐にわたります。たとえば、次の画像では、同じプロンプトを異なるスタイルで使用します。
「高層ビルを背景にした、角張ったスポーティな電動セダンの[art style or creation technique]」

|

|

|

|

|

|
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 2 モデルを使用して生成されました。
形状と素材
- プロンプトには、「... で作られた ...」、「... の形の ...」という表現を含めます。
このテクノロジーの強みの一つは、他の方法では困難または不可能な画像を作成できることです。たとえば、さまざまな素材やテクスチャで会社のロゴを再現できます。

|

|

|
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 4 モデルを使用して生成されました。
歴史的美術品のリファレンス
- プロンプトには、「... スタイルの ...」という表現を含めます。
特定のスタイルは、長年の間に象徴的な存在になりました。歴史的絵画やアートのスタイルを試すためのアイデアのいくつかを、以下に紹介します。
「[art period or movement] スタイルの画像(風力発電所)を生成」

|

|

|
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 4 モデルを使用して生成されました。
画像品質の修飾子
特定のキーワードから、高品質のアセットを探していることをモデルが認識できます。品質の修飾子の例を次に示します。
- 一般的な修飾子 - 高品質、美しい、図案化された
- 写真 - 4K、HDR、スタジオ写真
- アート、イラスト - プロが作成した、詳細な
以下に、品質の修飾子を使用しない場合のプロンプトと、同じプロンプトで品質の修飾子を使用したいくつかの例を示します。

|

プロカメラマンが撮影した トウモロコシの茎の写真 |
画像の生成元: 各画像は、対応するテキスト プロンプトと Imagen 4 モデルを使用して生成されました。
アスペクト比
Imagen の画像生成では、5 つの異なる画像アスペクト比を設定できます。
- スクエア(1:1、デフォルト)- 標準の正方形の写真。このアスペクト比の一般的な用途としては、ソーシャル メディアの投稿などがあります。
全画面(4:3) - このアスペクト比は、メディアや映画でよく使用されます。また、古い(ワイドスクリーンではない)テレビやミディアム フォーマット カメラでも使用されています。1:1 と比べると、横方向に広いシーンをキャプチャできるため、写真撮影に適したアスペクト比です。

プロンプト: ピアノを弾いているミュージシャンの手のアップ、モノクロ フィルム、ヴィンテージ(4:3 のアスペクト比) 
プロンプト: 高級レストランのフライドポテトのプロのスタジオ写真, フード雑誌のスタイル(アスペクト比 4:3) 縦向き全画面(3:4) - 全画面のアスペクト比を 90 度回転したもの。1:1 のアスペクト比と比べると、縦方向に広がるシーンをキャプチャできます。

プロンプト: ハイキングをする女性, 水たまりに映るブーツのクローズアップ, 背景に大きな山, 広告スタイル, ドラマチックなアングル(3:4 のアスペクト比) 
プロンプト: 神秘的な渓谷を流れる川の空撮(アスペクト比 3:4) ワイドスクリーン(16:9)- 4:3 に代わって、テレビ、モニター、スマートフォンの画面(横向き)で最も一般的なアスペクト比。風景など、広い背景を撮影する場合に使用します。

プロンプト: 全身白の服を着た男性がビーチに座っている, クローズアップ, ゴールデン アワーの照明(アスペクト比 16:9) 縦向き(9:16)- 比率はワイドスクリーンですが、回転しています。これは、ショート動画アプリ(YouTube ショートなど)で普及している比較的新しいアスペクト比です。建物、木、滝など、縦方向に長い対象に使用します。

プロンプト: 巨大な高層ビルのデジタル レンダリング, モダン, 壮大, 壮大な背景に美しい夕日(9:16 のアスペクト比)
フォトリアリスティックな画像
画像生成モデルのさまざまなバージョンによって、芸術的な出力とフォトリアリスティックな出力が混在する場合があります。プロンプトで次の表現を使用することで、生成する主題に応じてよりフォトリアリスティックな出力を生成できます。
| ユースケース | レンズの種類 | レンズ焦点距離 | 補足情報 |
|---|---|---|---|
| 人(縦向き) | プライム、ズーム | 24~35mm | モノクロ フィルム、フィルム ノワール、被写界深度、デュオトーン(2 色について言及) |
| 食品、虫、植物(物体、静物) | マクロ | 60~105mm | 高精細、正確なフォーカス、照明の制御 |
| スポーツ、野生動物(モーション) | 望遠ズーム | 100~400mm | 高速シャッター スピード、アクションまたは動作のトラッキング |
| 天体、風景(広角) | 広角 | 10~24mm | 長い露光時間、シャープ フォーカス、長時間露光、滑らかな水や雲 |
ポートレート
| ユースケース | レンズの種類 | レンズ焦点距離 | 補足情報 |
|---|---|---|---|
| 人(縦向き) | プライム、ズーム | 24~35mm | モノクロ フィルム、フィルム ノワール、被写界深度、デュオトーン(2 色について言及) |
このテーブルから複数のキーワードを使用して、Imagen により次のポートレートを生成できます。

|

|

|

|
プロンプト: 女性、35mm の縦向き、青とグレーのデュオトーン
モデル: imagen-4.0-generate-001

|

|

|

|
プロンプト: 女性、35mm 縦向き、フィルム ノワール
モデル: imagen-4.0-generate-001
オブジェクト
| ユースケース | レンズの種類 | レンズ焦点距離 | 補足情報 |
|---|---|---|---|
| 食品、虫、植物(物体、静物) | マクロ | 60~105mm | 高精細、正確なフォーカス、照明の制御 |
このテーブルから複数のキーワードを使用して、Imagen により次のオブジェクト画像を生成できます。

|

|

|

|
プロンプト: 花類、リーフ、60mm
モデル: imagen-4.0-generate-001

|

|

|

|
プロンプト: パスタのプレート、100mm マクロレンズ
モデル: imagen-4.0-generate-001
モーション
| ユースケース | レンズの種類 | レンズ焦点距離 | 補足情報 |
|---|---|---|---|
| スポーツ、野生動物(モーション) | 望遠ズーム | 100~400mm | 高速シャッター スピード、アクションまたは動作のトラッキング |
このテーブルから複数のキーワードを使用して、Imagen により次の動画を生成できます。

|

|
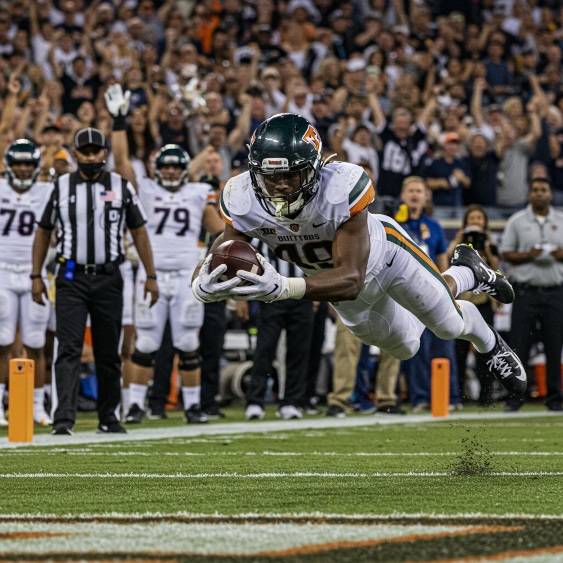
|

|
プロンプト: 勝利のタッチダウン、高速シャッター スピード、動作トラッキング
モデル: imagen-4.0-generate-001

|

|

|

|
プロンプト: 森の中を走るシカ、高速シャッター スピード、動作トラッキング
モデル: imagen-4.0-generate-001
広角
| ユースケース | レンズの種類 | レンズ焦点距離 | 補足情報 |
|---|---|---|---|
| 天体、風景(広角) | 広角 | 10~24mm | 長い露光時間、シャープ フォーカス、長時間露光、滑らかな水や雲 |
このテーブル内の複数のキーワードを使用して、Imagen により次の広角画像を生成できます。

|

|

|

|
プロンプト: 広大な山並み、風景、広角 10mm
モデル: imagen-4.0-generate-001

|

|

|

|
プロンプト: 月の写真、天体写真、広角 10mm
モデル: imagen-4.0-generate-001