
Sử dụng đơn vị xử lý đồ hoạ (GPU) để chạy các mô hình học máy (ML) có thể cải thiện đáng kể hiệu suất của mô hình và trải nghiệm người dùng của các ứng dụng hỗ trợ công nghệ học máy. Trên thiết bị iOS, bạn có thể cho phép sử dụng Thực thi các mô hình được tăng tốc GPU bằng cách sử dụng uỷ quyền. Người được uỷ quyền đóng vai trò là trình điều khiển phần cứng cho LiteRT cho phép bạn chạy mã mô hình của mình trên bộ xử lý GPU.
Trang này mô tả cách bật tính năng tăng tốc GPU cho các mô hình LiteRT trong Ứng dụng iOS. Để biết thêm thông tin về cách sử dụng uỷ quyền GPU cho LiteRT, bao gồm các phương pháp hay nhất và kỹ thuật nâng cao, hãy xem GPU uỷ quyền.
Sử dụng GPU với API phiên dịch
Thông dịch viên LiteRT API cung cấp một tập hợp các API mục đích để xây dựng ứng dụng học máy. Nội dung sau đây sẽ hướng dẫn bạn cách thêm tính năng hỗ trợ GPU vào ứng dụng iOS. Hướng dẫn này giả định rằng bạn đã có một ứng dụng iOS có thể thực thi thành công mô hình học máy với LiteRT.
Sửa đổi Podfile để bao gồm tính năng hỗ trợ GPU
Kể từ bản phát hành LiteRT 2.3.0, uỷ quyền GPU sẽ bị loại trừ
khỏi nhóm để giảm kích thước nhị phân. Bạn có thể đưa chúng vào bằng cách chỉ định
thông số phụ cho nhóm TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
OR
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Bạn cũng có thể dùng TensorFlowLiteObjC hoặc TensorFlowLiteC nếu muốn dùng
Target-C có sẵn cho phiên bản 2.4.0 trở lên hoặc API C.
Khởi chạy và sử dụng tính năng uỷ quyền GPU
Bạn có thể sử dụng tính năng uỷ quyền GPU với Trình thông dịch viên LiteRT API bằng một số phương thức lập trình ngôn ngữ. Bạn nên dùng Swift và object-C, nhưng cũng có thể dùng C++ và C. Bạn phải dùng C nếu đang dùng phiên bản LiteRT trước đó hơn 2,4. Các đoạn mã ví dụ sau đây trình bày cách sử dụng uỷ quyền trong mỗi đoạn mã của những ngôn ngữ này.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (trước phiên bản 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Ghi chú về việc sử dụng ngôn ngữ API GPU
- Các phiên bản LiteRT trước 2.4.0 chỉ có thể sử dụng API C cho Mục tiêu-C.
- Bạn chỉ dùng được API C++ khi sử dụng bazel hoặc tạo TensorFlow Thu gọn một mình. Không thể sử dụng API C++ với CocoaPods.
- Khi sử dụng LiteRT với uỷ quyền GPU bằng C++, hãy lấy GPU
uỷ quyền qua hàm
TFLGpuDelegateCreate()rồi truyền hàm đó vàoInterpreter::ModifyGraphWithDelegate(), thay vì gọiInterpreter::AllocateTensors().
Tạo và kiểm thử bằng chế độ phát hành
Thay đổi thành bản phát hành có chế độ cài đặt trình tăng tốc API Metal thích hợp thành có hiệu suất tốt hơn và để kiểm thử lần cuối. Phần này giải thích cách bật bản phát hành và định cấu hình chế độ cài đặt tăng tốc Metal.
Cách thay đổi thành bản phát hành:
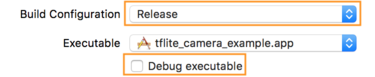
- Chỉnh sửa chế độ cài đặt bản dựng bằng cách chọn Product > Lược đồ > Chỉnh sửa lược đồ... rồi chọn Run (Chạy).
- Trên thẻ Info (Thông tin), hãy thay đổi Build Configuration (Cấu hình bản dựng) thành Release (Bản phát hành) và
bỏ đánh dấu mục Debug executable (Gỡ lỗi thực thi).
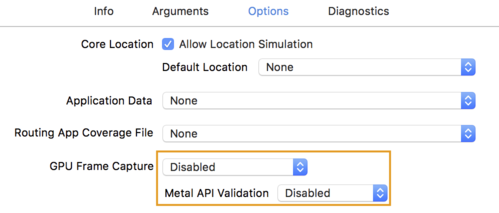
- Nhấp vào thẻ Options (Tuỳ chọn) rồi thay đổi GPU Frame Capture (Chụp khung hình GPU) thành Disabled (Tắt)
và Metal API Validation (Xác thực API kim loại) thành Tắt.
- Hãy nhớ chọn Bản dựng chỉ phát hành trên kiến trúc 64 bit. Thấp hơn
Trình điều hướng dự án > tflite_camera_example > DỰ ÁN > tên_dự_án_của_bạn >
Chế độ cài đặt bản dựng đặt Chỉ tạo kiến trúc hoạt động > Phát hành thành
Có.

Hỗ trợ GPU nâng cao
Phần này đề cập đến cách sử dụng nâng cao của ủy quyền GPU cho iOS, bao gồm các tuỳ chọn uỷ quyền, vùng đệm đầu vào và đầu ra cũng như việc sử dụng các mô hình lượng tử hoá.
Tuỳ chọn uỷ quyền cho iOS
Hàm khởi tạo cho uỷ quyền GPU chấp nhận struct tuỳ chọn trong Swift
API,
Objective-C
API,
và C
.
Truyền nullptr (API C) hoặc không truyền gì (API Target-C và Swift) đến
trình khởi tạo đặt các tuỳ chọn mặc định (được thể hiện trong phần Cách sử dụng cơ bản)
ví dụ ở trên).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Vùng đệm đầu vào/đầu ra sử dụng API C++
Việc tính toán trên GPU yêu cầu dữ liệu phải có sẵn cho GPU. Chiến dịch này thường có nghĩa là bạn phải thực hiện sao chép bộ nhớ. Bạn nên tránh vượt qua ranh giới bộ nhớ CPU/GPU nếu có thể, vì việc này có thể chiếm một lượng thời gian đáng kể. Việc vượt qua này là không thể tránh khỏi, nhưng trong một số các trường hợp đặc biệt, một trong hai trường hợp này có thể được bỏ qua.
Nếu đầu vào của mạng là một hình ảnh đã được tải trong bộ nhớ GPU (ví dụ ví dụ: hoạ tiết GPU chứa nguồn cấp dữ liệu máy ảnh) thì cấu trúc này có thể nằm trong bộ nhớ GPU mà không bao giờ nhập vào bộ nhớ CPU. Tương tự, nếu đầu ra của mạng nằm trong dạng hình ảnh có thể kết xuất hình ảnh, chẳng hạn như kiểu hình ảnh chuyển bạn có thể hiển thị trực tiếp kết quả trên màn hình.
Để đạt được hiệu suất tốt nhất, LiteRT giúp người dùng trực tiếp đọc và ghi vào vùng đệm phần cứng TensorFlow và bỏ qua các bản sao bộ nhớ có thể tránh được.
Giả sử đầu vào hình ảnh nằm trong bộ nhớ GPU, trước tiên bạn phải chuyển đổi hình ảnh đó thành
Đối tượng MTLBuffer cho Metal. Bạn có thể liên kết TfLiteTensor với một
MTLBuffer do người dùng chuẩn bị với TFLGpuDelegateBindMetalBufferToTensor()
. Lưu ý rằng hàm này phải được gọi sau
Interpreter::ModifyGraphWithDelegate(). Ngoài ra, kết quả suy luận là,
theo mặc định, được sao chép từ bộ nhớ GPU sang bộ nhớ CPU. Bạn có thể tắt hành vi này
bằng cách gọi Interpreter::SetAllowBufferHandleOutput(true) trong khoảng thời gian
khởi tạo.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Sau khi bạn tắt chế độ mặc định, hãy sao chép đầu ra suy luận từ GPU
bộ nhớ vào bộ nhớ CPU đòi hỏi một lệnh gọi rõ ràng đến
Interpreter::EnsureTensorDataIsReadable() cho mỗi tensor đầu ra. Chiến dịch này
cũng phù hợp với các mô hình lượng tử hoá, nhưng bạn vẫn cần sử dụng
vùng đệm có kích thước float32 với dữ liệu float32 vì vùng đệm được liên kết với
bộ đệm khử lượng tử nội bộ.
Mô hình lượng tử hoá
Thư viện uỷ quyền GPU của iOS hỗ trợ các mô hình lượng tử hoá theo mặc định. Bạn không cần thực hiện bất kỳ thay đổi nào về mã để sử dụng các mô hình lượng tử hoá với bộ uỷ quyền GPU. Chiến lược phát hành đĩa đơn phần sau đây giải thích cách tắt tính năng hỗ trợ lượng tử hoá cho việc kiểm thử hoặc cho mục đích thử nghiệm.
Tắt tính năng hỗ trợ mô hình lượng tử hoá
Đoạn mã sau đây cho biết cách tắt tính năng hỗ trợ cho các mô hình lượng tử hoá.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Để biết thêm thông tin về cách chạy các mô hình lượng tử hoá bằng tính năng tăng tốc GPU, hãy xem Tổng quan về Uỷ quyền GPU.