
Las herramientas de comparativas de LiteRT miden y calculan estadísticas para las siguientes métricas de rendimiento importantes:
- Hora de inicialización
- Tiempo de inferencia del estado de preparación
- Tiempo de inferencia del estado estable
- Uso de memoria durante el tiempo de inicialización
- Uso general de la memoria
Las herramientas de comparativas están disponibles como apps de comparativas para Android y iOS, y como archivos binarios precompilados de línea de comandos. Todas comparten la misma lógica de medición del rendimiento principal. Ten en cuenta que las opciones disponibles y los formatos de salida son ligeramente diferentes debido a las diferencias en el entorno de ejecución.
App de comparativa de Android
También se proporciona una app de comparativas de Android basada en la API de Interpreter v1. Esta es una mejor medida de cómo se desempeñaría el modelo en una app para Android. Los números de la herramienta de comparativas seguirán difiriendo ligeramente de los que se obtienen cuando se ejecuta la inferencia con el modelo en la app real.
Esta app de comparativas de Android no tiene IU. Instálalo y ejecútalo con el comando adb, y recupera los resultados con el comando adb logcat.
Descarga o compila la app
Descarga las apps de referencia de Android compiladas previamente de la versión nocturna con los siguientes vínculos:
En cuanto a las apps de comparativas de Android que admiten operaciones de TF a través del delegado de Flex, usa los siguientes vínculos:
También puedes compilar la app desde el código fuente siguiendo estas instrucciones.
Prepara la comparativa
Antes de ejecutar la app de comparativas, instálala y envía el archivo del modelo al dispositivo de la siguiente manera:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Ejecutar comparativa
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph es un parámetro obligatorio.
graph:string
Ruta de acceso al archivo del modelo de TFLite.
Puedes especificar más parámetros opcionales para ejecutar la comparativa.
num_threads:int(valor predeterminado=1)
Es la cantidad de subprocesos que se usarán para ejecutar el intérprete de TFLite.use_gpu:bool(valor predeterminado=false)
Usa el delegado de GPU.use_xnnpack:bool(predeterminado=false)
Usa el delegado de XNNPACK.
Según el dispositivo que uses, es posible que algunas de estas opciones no estén disponibles o no tengan efecto. Consulta los parámetros para obtener más parámetros de rendimiento que podrías ejecutar con la app de comparativas.
Consulta los resultados con el comando logcat:
adb logcat | grep "Inference timings"
Los resultados de la comparativa se informan de la siguiente manera:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
App de comparativa para iOS
Para ejecutar comparativas en un dispositivo iOS, debes compilar la app desde el código fuente.
Coloca el archivo del modelo LiteRT en el directorio benchmark_data del árbol de origen y modifica el archivo benchmark_params.json. Esos archivos se empaquetan en la app, y esta lee los datos del directorio. Visita la app de comparativas de iOS para obtener instrucciones detalladas.
Comparativas de rendimiento para modelos conocidos
En esta sección, se enumeran las comparativas de rendimiento de LiteRT cuando se ejecutan modelos conocidos en algunos dispositivos iOS y Android.
Comparativas de rendimiento de Android
Estos números de comparativas de rendimiento se generaron con el objeto binario de comparativas nativo.
En el caso de las comparativas de Android, la afinidad de la CPU se configura para usar núcleos grandes en el dispositivo y reducir la varianza (consulta los detalles).
Se supone que los modelos se descargaron y descomprimieron en el directorio /data/local/tmp/tflite_models. El objeto binario de comparativas se compila con estas instrucciones y se supone que está en el directorio /data/local/tmp.
Para ejecutar la comparativa, haz lo siguiente:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Para ejecutar con el delegado de GPU, establece --use_gpu=true.
Los valores de rendimiento que se muestran a continuación se midieron en Android 10.
| Nombre del modelo | Dispositivo | CPU, 4 subprocesos | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 ms | 6.45 ms |
| Pixel 4 | 14.0 ms | 9.0 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13.4 ms | --- |
| Pixel 4 | 5.0 ms | --- | |
| NASNet Mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34.5 ms | --- | |
| SqueezeNet | Pixel 3 | 35.8 ms | 9.5 ms |
| Pixel 4 | 23.9 ms | 11.1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99.8 ms |
| Pixel 4 | 272.6 ms | 87.2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324.1 ms | 97.6 ms |
Comparativas de rendimiento de iOS
Estos números de comparativas de rendimiento se generaron con la app de comparativas para iOS.
Para ejecutar comparativas de iOS, se modificó la app de comparativas para incluir el modelo adecuado y se modificó benchmark_params.json para establecer num_threads en 2. Para usar el delegado de GPU, también se agregaron las opciones "use_gpu" : "1" y "gpu_wait_type" : "aggressive" a benchmark_params.json.
| Nombre del modelo | Dispositivo | CPU, 2 subprocesos | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 ms | 3.4 ms |
| Mobilenet_1.0_224 (cuant.) | iPhone XS | 11 ms | --- |
| NASNet Mobile | iPhone XS | 30.4 ms | --- |
| SqueezeNet | iPhone XS | 21.1 ms | 15.5 ms |
| Inception_ResNet_V2 | iPhone XS | 261.1 ms | 45.7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54.4 ms |
Registra los detalles internos de LiteRT
Cómo rastrear los elementos internos de LiteRT en Android
Las herramientas de registro de Android pueden capturar los eventos internos del intérprete de LiteRT de una app para Android. Son los mismos eventos que con la API de Trace de Android, por lo que los eventos capturados del código de Java/Kotlin se ven junto con los eventos internos de LiteRT.
Estos son algunos ejemplos de eventos:
- Invocación del operador
- Modificación del gráfico por delegado
- Asignación de tensores
Entre las diferentes opciones para capturar registros, esta guía abarca el CPU Profiler de Android Studio y la app de System Tracing. Consulta la herramienta de línea de comandos de Perfetto o la herramienta de línea de comandos de Systrace para conocer otras opciones.
Cómo agregar eventos de seguimiento en código Java
Este es un fragmento de código de la app de ejemplo de Clasificación de imágenes. El intérprete de LiteRT se ejecuta en la sección recognizeImage/runInference. Este paso es opcional, pero es útil para notar dónde se realiza la llamada de inferencia.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Habilita el registro de LiteRT
Para habilitar el registro de LiteRT, establece la propiedad del sistema Android debug.tflite.trace en 1 antes de iniciar la app para Android.
adb shell setprop debug.tflite.trace 1
Si esta propiedad se configuró cuando se inicializó el intérprete de LiteRT, se hará un seguimiento de los eventos clave (p.ej., la invocación del operador) del intérprete.
Después de capturar todos los registros, inhabilita el registro estableciendo el valor de la propiedad en 0.
adb shell setprop debug.tflite.trace 0
Generador de perfiles de CPU de Android Studio
Para capturar registros con el generador de perfiles de CPU de Android Studio, sigue estos pasos:
Selecciona Run > Profile 'app' en los menús de la parte superior.
Haz clic en cualquier parte del cronograma de CPU cuando aparezca la ventana del Generador de perfiles.
Selecciona "Trace System Calls" entre los modos de generación de perfiles de CPU.
Presiona el botón "Grabar".
Presiona el botón "Detener".
Investiga el resultado del registro.
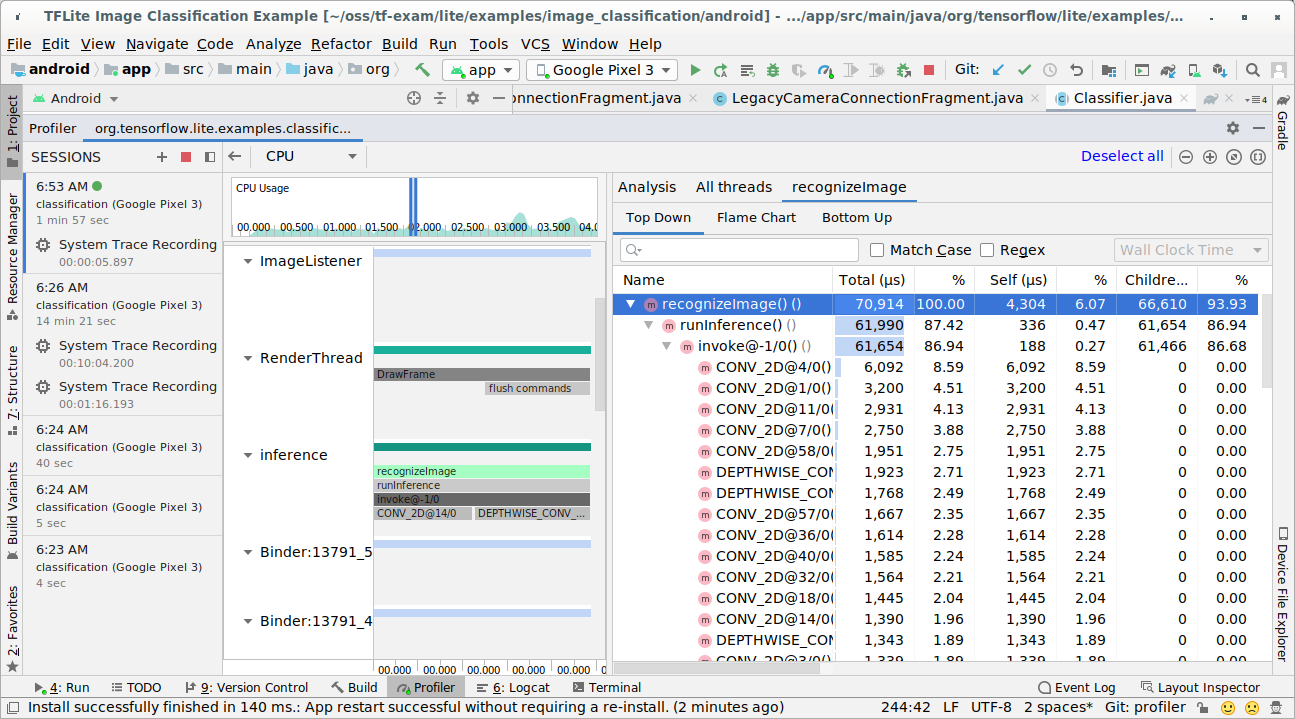
En este ejemplo, puedes ver la jerarquía de eventos en un subproceso y las estadísticas de cada tiempo de operador, así como el flujo de datos de toda la app entre los subprocesos.
La app de Registro del sistema
Para capturar registros sin Android Studio, sigue los pasos que se detallan en la app de System Tracing.
En este ejemplo, se capturaron los mismos eventos de TFLite y se guardaron en formato Perfetto o Systrace, según la versión del dispositivo Android. Los archivos de registro capturados se pueden abrir en la IU de Perfetto.
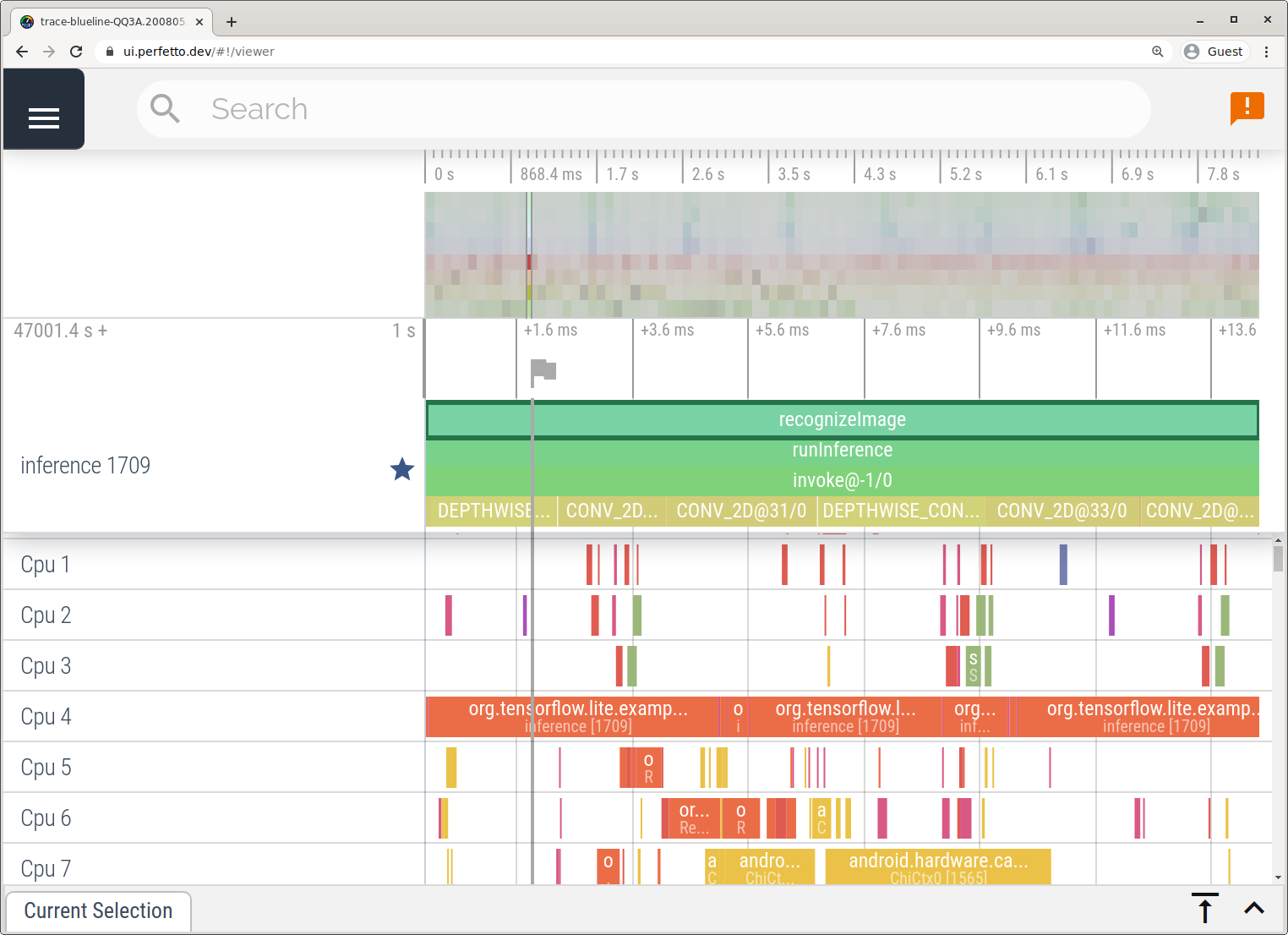
Cómo rastrear los elementos internos de LiteRT en iOS
La herramienta Instruments incluida en Xcode puede capturar los eventos internos del intérprete de LiteRT de una app para iOS. Son los eventos de signpost de iOS, por lo que los eventos capturados del código de Swift/Objective-C se ven junto con los eventos internos de LiteRT.
Estos son algunos ejemplos de eventos:
- Invocación del operador
- Modificación del gráfico por delegado
- Asignación de tensores
Habilita el registro de LiteRT
Sigue los pasos que se indican a continuación para configurar la variable de entorno debug.tflite.trace:
Selecciona Product > Scheme > Edit Scheme… en los menús superiores de Xcode.
Haz clic en "Perfil" en el panel izquierdo.
Anula la selección de la casilla de verificación "Usar los argumentos y las variables de entorno de la acción Ejecutar".
Agrega
debug.tflite.traceen la sección "Variables de entorno".
Si deseas excluir los eventos de LiteRT cuando generes perfiles de la app para iOS, inhabilita el registro quitando la variable de entorno.
Instruments de Xcode
Para capturar registros, sigue estos pasos:
Selecciona Product > Profile en los menús superiores de Xcode.
Haz clic en Logging entre las plantillas de generación de perfiles cuando se inicie la herramienta Instruments.
Presiona el botón "Start".
Presiona el botón "Detener".
Haz clic en "os_signpost" para expandir los elementos del subsistema de registro del SO.
Haz clic en el subsistema de registro del SO "org.tensorflow.lite".
Investiga el resultado del registro.
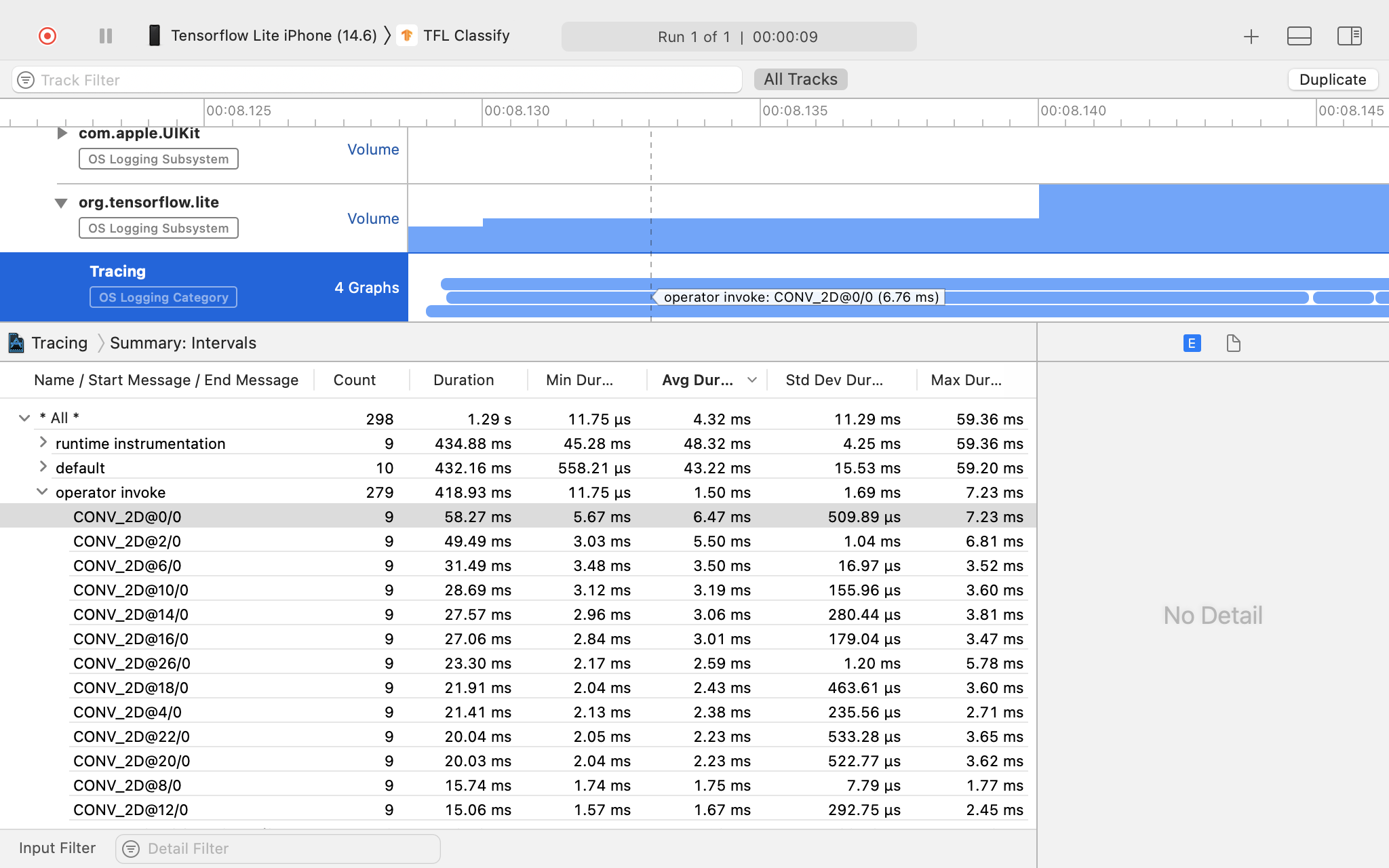
En este ejemplo, puedes ver la jerarquía de eventos y estadísticas para cada período del operador.
Cómo usar los datos de seguimiento
Los datos de seguimiento te permiten identificar cuellos de botella en el rendimiento.
Estos son algunos ejemplos de estadísticas que puedes obtener del generador de perfiles y posibles soluciones para mejorar el rendimiento:
- Si la cantidad de núcleos de CPU disponibles es menor que la cantidad de subprocesos de inferencia, la sobrecarga de programación de la CPU puede generar un rendimiento inferior al esperado. Puedes reprogramar otras tareas que consuman mucha CPU en tu aplicación para evitar que se superpongan con la inferencia del modelo o ajustar la cantidad de subprocesos del intérprete.
- Si los operadores no se delegan por completo, algunas partes del gráfico del modelo se ejecutan en la CPU en lugar del acelerador de hardware esperado. Puedes sustituir los operadores no admitidos por operadores similares admitidos.