
概览
本页介绍了将 TensorFlow 中的复合操作转换为 LiteRT 中的融合操作所需的设计和步骤。此基础架构用途广泛,支持将 TensorFlow 中的任何复合操作转换为 LiteRT 中对应的融合操作。
此基础架构的一个使用示例是将 TensorFlow RNN 操作融合到 LiteRT,详情请参阅此处。
什么是融合操作

TensorFlow 操作可以是基本操作(例如 tf.add),也可以由其他基本操作组成(例如 tf.einsum)。原始操作在 TensorFlow 图中显示为单个节点,而复合操作是 TensorFlow 图中的一组节点。执行复合操作相当于执行其每个组成的原语操作。
融合操作对应于一个操作,该操作包含相应复合操作中每个原始操作执行的所有计算。
融合操作的优势
融合运算旨在通过优化整体计算和减少内存占用量,最大限度地提高其底层内核实现的性能。这非常有用,尤其对于低延迟推理工作负载和资源受限的移动平台。
融合操作还提供了一个更高级别的接口来定义复杂的转换(例如量化),否则在更精细的级别上实现这些转换会非常困难或不可行。
出于上述原因,LiteRT 有许多融合操作实例。这些融合操作通常对应于源 TensorFlow 程序中的复合操作。在 TensorFlow 中,作为 LiteRT 中的单个融合操作实现的复合操作示例包括各种 RNN 操作,例如单向和双向序列 LSTM、卷积(conv2d、偏差加法、relu)、全连接(matmul、偏差加法、relu)等。在 LiteRT 中,LSTM 量化目前仅在融合 LSTM 操作中实现。
融合操作方面的挑战
将复合操作从 TensorFlow 转换为 LiteRT 中的融合操作是一个难题。原因如下:
复合操作在 TensorFlow 图中表示为一组没有明确边界的原始操作。识别(例如通过模式匹配)与此类复合操作对应的子图可能非常困难。
可能存在多个以融合的 LiteRT 操作为目标的 TensorFlow 实现。例如,TensorFlow 中有许多 LSTM 实现(Keras、Babelfish/lingvo 等),每种实现都由不同的基元操作组成,但它们仍然可以全部转换为 LiteRT 中的同一融合 LSTM 操作。
因此,融合操作的转换非常具有挑战性。
从复合运算转换为 TFLite 自定义运算(推荐)
将复合操作封装在 tf.function 中
在许多情况下,模型的一部分可以映射到 TFLite 中的单个操作。这有助于针对特定操作编写优化后的实现,从而提升性能。为了能够在 TFLite 中创建融合操作,请确定图中表示融合操作的部分,并将其封装在 tf.function 中,同时将“experimental_implements”属性设置为 tf.function,该属性具有属性值 tfl_fusable_op,其值为 true。如果自定义操作需要属性,则将这些属性作为同一“experimental_implements”的一部分进行传递。
示例:
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
请注意,您无需在转换器上设置 allow_custom_ops,因为 tfl_fusable_op 属性已暗示这一点。
实现自定义操作并向 TFLite 解释器注册
将融合操作实现为 TFLite 自定义操作 - 请参阅相关说明。
请注意,用于注册操作的名称应与实现签名中 name 属性内指定的名称类似。
示例中相应操作的示例如下:
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
从复合操作转换为融合操作(高级)
将 TensorFlow 复合操作转换为 LiteRT 融合操作的总体架构如下:
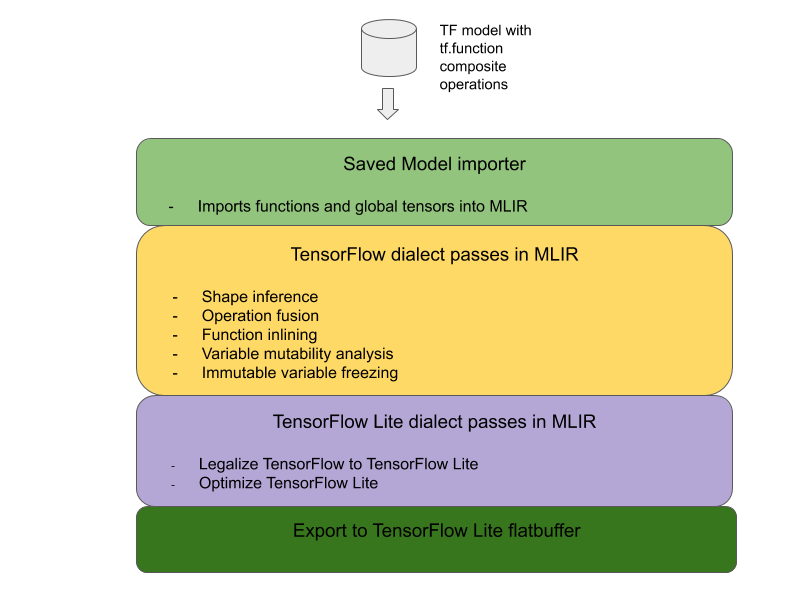
将复合操作封装在 tf.function 中
在 TensorFlow 模型源代码中,识别出复合操作并将其抽象为带有 experimental_implements 函数注释的 tf.function。请参阅嵌入查找的示例。该函数定义了应使用哪些接口及其参数来实现转化逻辑。
编写转化代码
转化代码是根据带有 implements 注释的函数的接口编写的。请参阅嵌入查找的融合示例。从概念上讲,转化代码会将此接口的复合实现替换为融合实现。
在 prepare-composite-functions 传递中,插入您的转换代码。
在更高级的用法中,可以实现复合运算操作数的复杂转换,以便派生融合运算的操作数。请参阅 Keras LSTM 转换代码示例。
转换为 LiteRT
使用 TFLiteConverter.from_saved_model API 转换为 LiteRT。
深入了解
现在,我们将介绍在 LiteRT 中转换为融合操作的总体设计的高级细节。
在 TensorFlow 中组合操作
通过将 tf.function 与 experimental_implements 函数属性搭配使用,用户可以使用 TensorFlow 原始操作显式组合新操作,并指定生成的复合操作实现的接口。这非常有用,因为它提供了:
- 底层 TensorFlow 图中复合运算的明确定义的边界。
- 明确指定相应操作实现的接口。tf.function 的实参与此接口的实参相对应。
举例来说,假设有一个复合操作定义为实现嵌入查找。这会映射到 LiteRT 中的融合操作。
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
通过使模型使用 tf.function 中的复合操作(如上例所示),可以构建一个通用基础架构来识别和转换此类操作,使其成为融合的 LiteRT 操作。
扩展 LiteRT 转换器
今年早些时候发布的 LiteRT 转换器仅支持将 TensorFlow 模型作为图导入,其中所有变量都替换为相应的常量值。这不适用于操作融合,因为此类图表中的所有函数都已内联,以便将变量转换为常量。
为了在转换过程中利用 experimental_implements 功能,需要保留函数,直到转换过程的后期。tf.function
因此,我们在转换器中实现了导入和转换 TensorFlow 模型的新工作流,以支持复合运算融合使用情形。具体来说,添加的新功能包括:
- 将 TensorFlow 保存的模型导入到 MLIR
- 融合复合操作
- 变量可变性分析
- 冻结所有只读变量
这样,我们就可以在函数内嵌和变量冻结之前,使用表示复合操作的函数来执行操作融合。
实现操作融合
我们来详细了解一下操作融合传递。此遍会执行以下操作:
- 遍历 MLIR 模块中的所有函数。
- 如果某个函数具有 tf._implements 属性,则根据该属性的值调用相应的操作融合实用程序。
- 操作融合实用程序对函数的运算对象和属性(用作转换的接口)进行操作,并使用包含融合操作的等效函数正文替换该函数的函数正文。
- 在许多情况下,替换后的正文将包含融合操作以外的其他操作。这些对应于对函数实参的一些静态转换,以便获得融合操作的实参。由于这些计算都可以进行常量折叠,因此它们不会出现在导出的扁平缓冲区中,其中只会存在融合操作。
以下是通行证中的代码段,显示了主工作流:
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
以下代码段展示了如何利用该函数作为转换接口,在 LiteRT 中将此复合操作映射到融合操作。
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}