
Panoramica
Questa pagina descrive la progettazione e i passaggi necessari per convertire le operazioni composite in TensorFlow in operazioni fuse in LiteRT. Questa infrastruttura è di uso generale e supporta la conversione di qualsiasi operazione composita in TensorFlow in un'operazione fusa corrispondente in LiteRT.
Un esempio di utilizzo di questa infrastruttura è la fusione dell'operazione RNN di TensorFlow in LiteRT, come descritto in dettaglio qui.
Che cosa sono le operazioni combinate

Le operazioni TensorFlow possono essere primitive, ad es. tf.add, oppure possono essere composte da altre operazioni primitive, ad es. tf.einsum. Un'operazione primitiva viene visualizzata come un singolo nodo nel grafico TensorFlow, mentre un'operazione composita è una raccolta di nodi nel grafico TensorFlow. L'esecuzione di un'operazione composita equivale all'esecuzione di ciascuna delle sue operazioni primitive costituenti.
Un'operazione fusa corrisponde a una singola operazione che include tutti i calcoli eseguiti da ogni operazione primitiva all'interno dell'operazione composita corrispondente.
Vantaggi delle operazioni combinate
Le operazioni combinate esistono per massimizzare le prestazioni delle implementazioni del kernel sottostanti, ottimizzando il calcolo complessivo e riducendo l'impronta di memoria. Ciò è molto utile, soprattutto per i carichi di lavoro di inferenza a bassa latenza e per le piattaforme mobile con risorse limitate.
Le operazioni di fusione forniscono anche un'interfaccia di livello superiore per definire trasformazioni complesse come la quantizzazione, che altrimenti sarebbero impraticabili o molto difficili da eseguire a un livello più granulare.
LiteRT ha molte istanze di operazioni fuse per i motivi indicati sopra. Queste operazioni combinate in genere corrispondono a operazioni composite nel programma TensorFlow di origine. Esempi di operazioni composite in TensorFlow che vengono implementate come singola operazione fusa in LiteRT includono varie operazioni RNN come LSTM di sequenza unidirezionale e bidirezionale, convoluzione (conv2d, bias add, relu), completamente connessa (matmul, bias add, relu) e altro ancora. In LiteRT, la quantizzazione LSTM è attualmente implementata solo nelle operazioni LSTM fused.
Sfide relative alle operazioni combinate
La conversione di operazioni composite da TensorFlow a operazioni combinate in LiteRT è un problema difficile. I motivi sono i seguenti:
Le operazioni composite sono rappresentate nel grafico TensorFlow come un insieme di operazioni primitive senza un limite ben definito. Può essere molto difficile identificare (ad es. tramite la corrispondenza di pattern) il sottografo corrispondente a un'operazione composita.
Potrebbe esserci più di un'implementazione di TensorFlow che ha come target un'operazione LiteRT fusa. Ad esempio, esistono molte implementazioni LSTM in TensorFlow (Keras, Babelfish/lingvo e così via) e ognuna di queste è composta da diverse operazioni primitive, ma tutte potrebbero comunque essere convertite nella stessa operazione LSTM fusa in LiteRT.
Pertanto, la conversione delle operazioni combinate si è rivelata piuttosto difficile.
Conversione da un'operazione composita a un'operazione personalizzata TFLite (opzione consigliata)
Racchiudi l'operazione composita in un tf.function
In molti casi, una parte del modello può essere mappata a una singola operazione in
TFLite. Ciò può contribuire a migliorare il rendimento quando scrivi un'implementazione ottimizzata
per operazioni specifiche. Per poter creare un'operazione combinata in TFLite,
identifica la parte del grafico che rappresenta un'operazione combinata e racchiudila in
una tf.function con
l'attributo "experimental_implements" a un tf.function, che ha un valore
dell'attributo tfl_fusable_op con valore true. Se l'operazione personalizzata accetta
attributi, trasmettili come parte dello stesso "experimental_implements".
Esempio:
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
Tieni presente che non devi impostare allow_custom_ops sul convertitore perché
l'attributo tfl_fusable_op lo implica già.
Implementa l'operazione personalizzata e registrati con l'interprete TFLite
Implementa l'operazione unita come operazione personalizzata TFLite. Per istruzioni, vedi questo articolo.
Tieni presente che il nome con cui registrare l'operazione deve essere simile a quello specificato nell'attributo name nella firma implements.
Un esempio per l'op nell'esempio è
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
Conversione da operazione composita a operazione unita (Advanced)
Di seguito è riportata l'architettura generale per la conversione delle operazioni composite TensorFlow in operazioni fuse LiteRT:
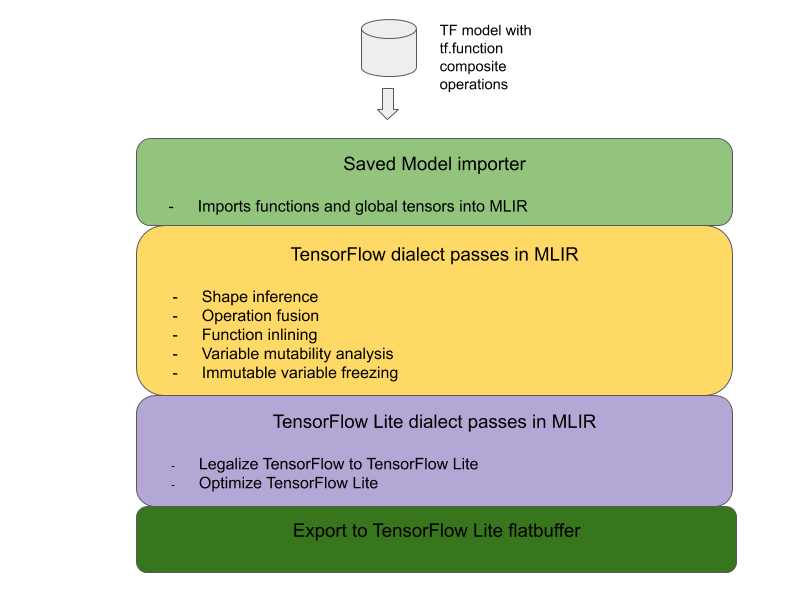
Racchiudi l'operazione composita in un tf.function
Nel codice sorgente del modello TensorFlow, identifica e estrai l'operazione composita in una tf.function con l'annotazione della funzione experimental_implements. Vedi un esempio di ricerca di incorporamento. La funzione definisce l'interfaccia e i relativi argomenti devono essere utilizzati per implementare la logica di conversione.
Scrivere il codice di conversione
Il codice di conversione viene scritto in base all'interfaccia della funzione con l'annotazione
implements. Vedi un esempio di fusione per la ricerca
incorporata. A livello concettuale, il codice di conversione sostituisce l'implementazione
composita di questa interfaccia con quella unita.
Nella fase prepare-composite-functions, inserisci il codice di conversione.
Negli utilizzi più avanzati, è possibile implementare trasformazioni complesse degli operandi dell'operazione composita per derivare gli operandi dell'operazione fusa. Vedi Keras LSTM. conversion code come esempio.
Converti in LiteRT
Utilizza l'API TFLiteConverter.from_saved_model per la conversione in LiteRT.
dietro le quinte
Ora descriviamo i dettagli di alto livello della progettazione complessiva della conversione in operazioni fuse in LiteRT.
Composizione di operazioni in TensorFlow
L'utilizzo di tf.function con l'attributo experimental_implements della funzione consente agli utenti di comporre esplicitamente nuove operazioni utilizzando le operazioni primitive di TensorFlow e specificare l'interfaccia implementata dall'operazione composita risultante. Questa funzionalità è molto utile perché offre:
- Un limite ben definito per l'operazione composita nel grafico TensorFlow sottostante.
- Specifica esplicitamente l'interfaccia implementata da questa operazione. Gli argomenti di tf.function corrispondono agli argomenti di questa interfaccia.
Come esempio, consideriamo un'operazione composita definita per implementare la ricerca di incorporamenti. Questo valore corrisponde a un'operazione combinata in LiteRT.
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
Se i modelli utilizzano operazioni composite tramite tf.function come illustrato sopra, è possibile creare un'infrastruttura generale per identificare e convertire queste operazioni in operazioni LiteRT fuse.
Estensione del convertitore LiteRT
Il convertitore LiteRT rilasciato all'inizio di quest'anno supportava solo l'importazione di modelli TensorFlow come grafico con tutte le variabili sostituite dai valori costanti corrispondenti. Questa operazione non funziona per la fusione delle operazioni, poiché tutti i grafici hanno le funzioni inlined in modo che le variabili possano essere trasformate in costanti.
Per sfruttare tf.function con la funzionalità experimental_implements durante il processo di conversione, le funzioni devono essere conservate fino a un momento successivo del processo di conversione.
Pertanto, abbiamo implementato un nuovo flusso di lavoro di importazione e conversione dei modelli TensorFlow nel convertitore per supportare lo scenario d'uso della fusione di operazioni composite. Nello specifico, le nuove funzionalità aggiunte sono:
- Importazione di modelli salvati TensorFlow in MLIR
- fuse composite operations
- Analisi della mutabilità delle variabili
- blocca tutte le variabili di sola lettura
Ciò consente di eseguire la fusione delle operazioni utilizzando le funzioni che rappresentano le operazioni composite prima dell'incorporamento delle funzioni e del blocco delle variabili.
Implementazione della fusione delle operazioni
Esaminiamo più nel dettaglio il passaggio di fusione delle operazioni. Questa tessera fa quanto segue:
- Esegui il loop di tutte le funzioni nel modulo MLIR.
- Se una funzione ha l'attributo tf._implements, in base al valore dell'attributo chiama l'utilità di fusione delle operazioni appropriata.
- L'utilità di fusione delle operazioni opera sugli operandi e sugli attributi della funzione (che fungono da interfaccia per la conversione) e sostituisce il corpo della funzione con un corpo della funzione equivalente contenente l'operazione unita.
- In molti casi, il corpo sostituito conterrà operazioni diverse da quella unita. Queste corrispondono ad alcune trasformazioni statiche sugli operandi della funzione per ottenere gli operandi dell'operazione combinata. Poiché tutti questi calcoli possono essere eliminati, non saranno presenti nel flatbuffer esportato, in cui esisterà solo l'operazione fusa.
Ecco uno snippet di codice della tessera che mostra il flusso di lavoro principale:
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
Ecco uno snippet di codice che mostra il mapping di questa operazione composita a un'operazione fusa in LiteRT che sfrutta la funzione come interfaccia di conversione.
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}